 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Dynamic Graph Network: Coupling Structural and Functional Connectome for Disease Diagnosis and Classification
Oct 25, 2022


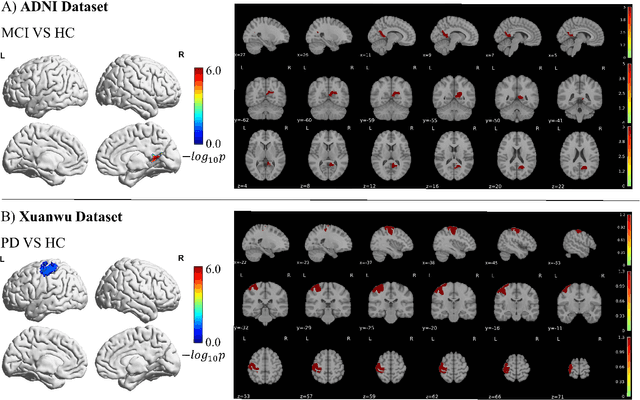
Multi-modal neuroimaging technology has greatlly facilitated the efficiency and diagnosis accuracy, which provides complementary information in discovering objective disease biomarkers. Conventional deep learning methods, e.g. convolutional neural networks, overlook relationships between nodes and fail to capture topological properties in graphs. Graph neural networks have been proven to be of great importance in modeling brain connectome networks and relating disease-specific patterns. However, most existing graph methods explicitly require known graph structures, which are not available in the sophisticated brain system. Especially in heterogeneous multi-modal brain networks, there exists a great challenge to model interactions among brain regions in consideration of inter-modal dependencies. In this study, we propose a Multi-modal Dynamic Graph Convolution Network (MDGCN) for structural and functional brain network learning. Our method benefits from modeling inter-modal representations and relating attentive multi-model associations into dynamic graphs with a compositional correspondence matrix. Moreover, a bilateral graph convolution layer is proposed to aggregate multi-modal representations in terms of multi-modal associations. Extensive experiments on three datasets demonstrate the superiority of our proposed method in terms of disease classification, with the accuracy of 90.4%, 85.9% and 98.3% in predicting Mild Cognitive Impairment (MCI), Parkinson's disease (PD), and schizophrenia (SCHZ) respectively. Furthermore, our statistical evaluations on the correspondence matrix exhibit a high correspondence with previous evidence of biomarkers.
Estimating Brain Age with Global and Local Dependencies
Sep 19, 2022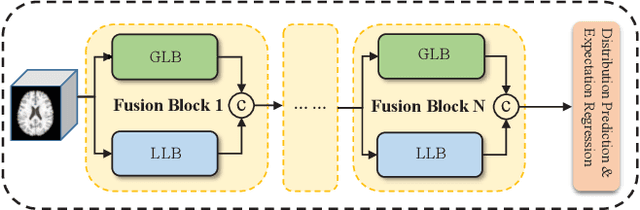
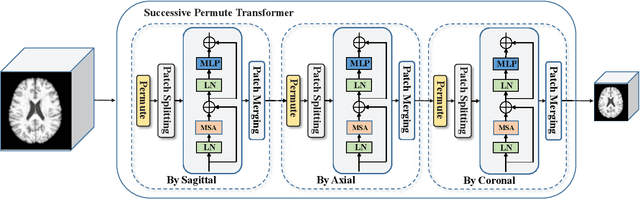
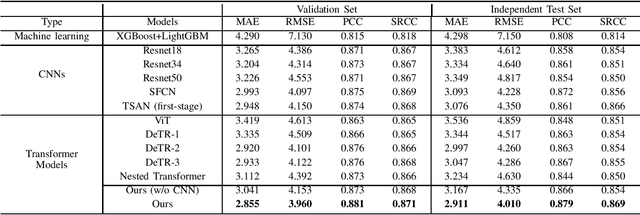
The brain age has been proven to be a phenotype of relevance to cognitive performance and brain disease. Achieving accurate brain age prediction is an essential prerequisite for optimizing the predicted brain-age difference as a biomarker. As a comprehensive biological characteristic, the brain age is hard to be exploited accurately with models using feature engineering and local processing such as local convolution and recurrent operations that process one local neighborhood at a time. Instead, Vision Transformers learn global attentive interaction of patch tokens, introducing less inductive bias and modeling long-range dependencies. In terms of this, we proposed a novel network for learning brain age interpreting with global and local dependencies, where the corresponding representations are captured by Successive Permuted Transformer (SPT) and convolution blocks. The SPT brings computation efficiency and locates the 3D spatial information indirectly via continuously encoding 2D slices from different views. Finally, we collect a large cohort of 22645 subjects with ages ranging from 14 to 97 and our network performed the best among a series of deep learning methods, yielding a mean absolute error (MAE) of 2.855 in validation set, and 2.911 in an independent test set.