 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolEvolve: LLM-Guided Evolutionary Search for Interpretable Molecular Optimization
Mar 25, 2026Despite deep learning's success in chemistry, its impact is hindered by a lack of interpretability and an inability to resolve activity cliffs, where minor structural nuances trigger drastic property shifts. Current representation learning, bound by the similarity principle, often fails to capture these structural-activity discontinuities. To address this, we introduce MolEvolve, an evolutionary framework that reformulates molecular discovery as an autonomous, look-ahead planning problem. Unlike traditional methods that depend on human-engineered features or rigid prior knowledge, MolEvolve leverages a Large Language Model (LLM) to actively explore and evolve a library of executable chemical symbolic operations. By utilizing the LLM to cold start and an Monte Carlo Tree Search (MCTS) engine for test-time planning with external tools (e.g. RDKit), the system self-discovers optimal trajectories autonomously. This process evolves transparent reasoning chains that translate complex structural transformations into actionable, human-readable chemical insights. Experimental results demonstrate that MolEvolve's autonomous search not only evolves transparent, human-readable chemical insights, but also outperforms baselines in both property prediction and molecule optimization tasks.
HippMetric: A skeletal-representation-based framework for cross-sectional and longitudinal hippocampal substructural morphometry
Dec 22, 2025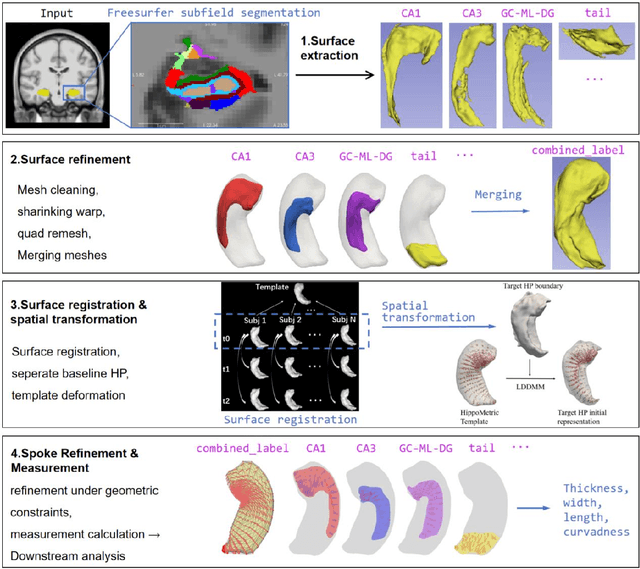
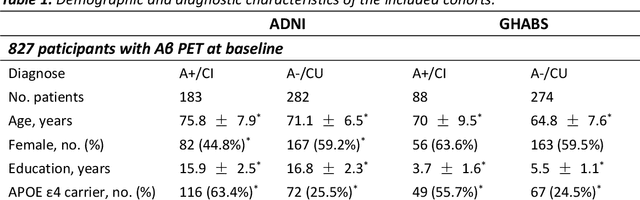
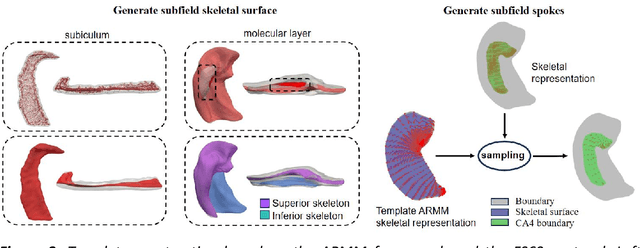
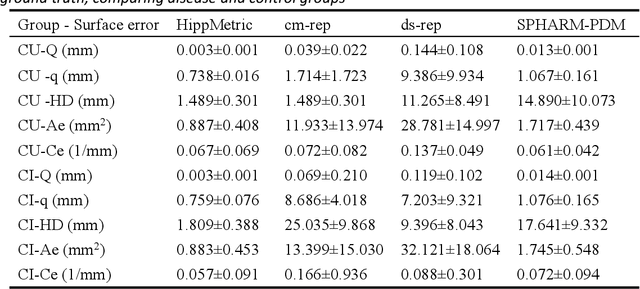
Accurate characterization of hippocampal substructure is crucial for detecting subtle structural changes and identifying early neurodegenerative biomarkers. However, high inter-subject variability and complex folding pattern of human hippocampus hinder consistent cross-subject and longitudinal analysis. Most existing approaches rely on subject-specific modelling and lack a stable intrinsic coordinate system to accommodate anatomical variability, which limits their ability to establish reliable inter- and intra-individual correspondence. To address this, we propose HippMetric, a skeletal representation (s-rep)-based framework for hippocampal substructural morphometry and point-wise correspondence across individuals and scans. HippMetric builds on the Axis-Referenced Morphometric Model (ARMM) and employs a deformable skeletal coordinate system aligned with hippocampal anatomy and function, providing a biologically grounded reference for correspondence. Our framework comprises two core modules: a skeletal-based coordinate system that respects the hippocampus' conserved longitudinal lamellar architecture, in which functional units (lamellae) are stacked perpendicular to the long-axis, enabling anatomically consistent localization across subjects and time; and individualized s-reps generated through surface reconstruction, deformation, and geometrically constrained spoke refinement, enforcing boundary adherence, orthogonality and non-intersection to produce mathematically valid skeletal geometry. Extensive experiments on two international cohorts demonstrate that HippMetric achieves higher accuracy, reliability, and correspondence stability compared to existing shape models.
Medverse: A Universal Model for Full-Resolution 3D Medical Image Segmentation, Transformation and Enhancement
Sep 11, 2025In-context learning (ICL) offers a promising paradigm for universal medical image analysis, enabling models to perform diverse image processing tasks without retraining. However, current ICL models for medical imaging remain limited in two critical aspects: they cannot simultaneously achieve high-fidelity predictions and global anatomical understanding, and there is no unified model trained across diverse medical imaging tasks (e.g., segmentation and enhancement) and anatomical regions. As a result, the full potential of ICL in medical imaging remains underexplored. Thus, we present \textbf{Medverse}, a universal ICL model for 3D medical imaging, trained on 22 datasets covering diverse tasks in universal image segmentation, transformation, and enhancement across multiple organs, imaging modalities, and clinical centers. Medverse employs a next-scale autoregressive in-context learning framework that progressively refines predictions from coarse to fine, generating consistent, full-resolution volumetric outputs and enabling multi-scale anatomical awareness. We further propose a blockwise cross-attention module that facilitates long-range interactions between context and target inputs while preserving computational efficiency through spatial sparsity. Medverse is extensively evaluated on a broad collection of held-out datasets covering previously unseen clinical centers, organs, species, and imaging modalities. Results demonstrate that Medverse substantially outperforms existing ICL baselines and establishes a novel paradigm for in-context learning. Code and model weights will be made publicly available. Our model are publicly available at https://github.com/jiesihu/Medverse.
Building 3D In-Context Learning Universal Model in Neuroimaging
Mar 04, 2025In-context learning (ICL), a type of universal model, demonstrates exceptional generalization across a wide range of tasks without retraining by leveraging task-specific guidance from context, making it particularly effective for the complex demands of neuroimaging. However, existing ICL models, which take 2D images as input, struggle to fully leverage the 3D anatomical structures in neuroimages, leading to a lack of global awareness and suboptimal performance. In this regard, we introduce Neuroverse3D, an ICL model capable of performing multiple neuroimaging tasks (e.g., segmentation, denoising, inpainting) in 3D. Neuroverse3D overcomes the large memory consumption due to 3D inputs through adaptive parallel-sequential context processing and a U-shape fusion strategy, allowing it to handle an unlimited number of context images. Additionally, we propose an optimized loss to balance multi-task training and enhance the focus on anatomical structures. Our study incorporates 43,674 3D scans from 19 neuroimaging datasets and evaluates Neuroverse3D on 14 diverse tasks using held-out test sets. The results demonstrate that Neuroverse3D significantly outperforms existing ICL models and closely matches the performance of task-specific models. The code and model weights are publicly released at: https://github.com/jiesihu/Neu3D.
Touchstone Benchmark: Are We on the Right Way for Evaluating AI Algorithms for Medical Segmentation?
Nov 06, 2024



How can we test AI performance? This question seems trivial, but it isn't. Standard benchmarks often have problems such as in-distribution and small-size test sets, oversimplified metrics, unfair comparisons, and short-term outcome pressure. As a consequence, good performance on standard benchmarks does not guarantee success in real-world scenarios. To address these problems, we present Touchstone, a large-scale collaborative segmentation benchmark of 9 types of abdominal organs. This benchmark is based on 5,195 training CT scans from 76 hospitals around the world and 5,903 testing CT scans from 11 additional hospitals. This diverse test set enhances the statistical significance of benchmark results and rigorously evaluates AI algorithms across various out-of-distribution scenarios. We invited 14 inventors of 19 AI algorithms to train their algorithms, while our team, as a third party, independently evaluated these algorithms on three test sets. In addition, we also evaluated pre-existing AI frameworks--which, differing from algorithms, are more flexible and can support different algorithms--including MONAI from NVIDIA, nnU-Net from DKFZ, and numerous other open-source frameworks. We are committed to expanding this benchmark to encourage more innovation of AI algorithms for the medical domain.
Advancing Brain Imaging Analysis Step-by-step via Progressive Self-paced Learning
Jul 23, 2024



Recent advancements in deep learning have shifted the development of brain imaging analysis. However, several challenges remain, such as heterogeneity, individual variations, and the contradiction between the high dimensionality and small size of brain imaging datasets. These issues complicate the learning process, preventing models from capturing intrinsic, meaningful patterns and potentially leading to suboptimal performance due to biases and overfitting. Curriculum learning (CL) presents a promising solution by organizing training examples from simple to complex, mimicking the human learning process, and potentially fostering the development of more robust and accurate models. Despite its potential, the inherent limitations posed by small initial training datasets present significant challenges, including overfitting and poor generalization. In this paper, we introduce the Progressive Self-Paced Distillation (PSPD) framework, employing an adaptive and progressive pacing and distillation mechanism. This allows for dynamic curriculum adjustments based on the states of both past and present models. The past model serves as a teacher, guiding the current model with gradually refined curriculum knowledge and helping prevent the loss of previously acquired knowledge. We validate PSPD's efficacy and adaptability across various convolutional neural networks using the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset, underscoring its superiority in enhancing model performance and generalization capabilities. The source code for this approach will be released at https://github.com/Hrychen7/PSPD.
Centerline Boundary Dice Loss for Vascular Segmentation
Jul 01, 2024

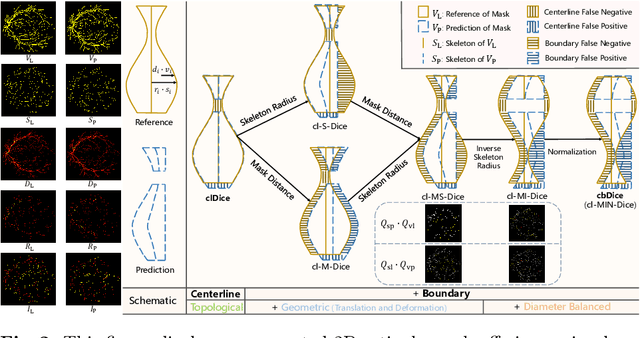
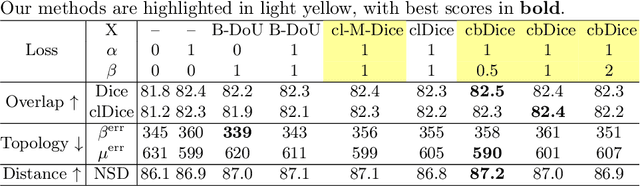
Vascular segmentation in medical imaging plays a crucial role in analysing morphological and functional assessments. Traditional methods, like the centerline Dice (clDice) loss, ensure topology preservation but falter in capturing geometric details, especially under translation and deformation. The combination of clDice with traditional Dice loss can lead to diameter imbalance, favoring larger vessels. Addressing these challenges, we introduce the centerline boundary Dice (cbDice) loss function, which harmonizes topological integrity and geometric nuances, ensuring consistent segmentation across various vessel sizes. cbDice enriches the clDice approach by including boundary-aware aspects, thereby improving geometric detail recognition. It matches the performance of the boundary difference over union (B-DoU) loss through a mask-distance-based approach, enhancing traslation sensitivity. Crucially, cbDice incorporates radius information from vascular skeletons, enabling uniform adaptation to vascular diameter changes and maintaining balance in branch growth and fracture impacts. Furthermore, we conducted a theoretical analysis of clDice variants (cl-X-Dice). We validated cbDice's efficacy on three diverse vascular segmentation datasets, encompassing both 2D and 3D, and binary and multi-class segmentation. Particularly, the method integrated with cbDice demonstrated outstanding performance on the MICCAI 2023 TopCoW Challenge dataset. Our code is made publicly available at: https://github.com/PengchengShi1220/cbDice.
Benchmarking the CoW with the TopCoW Challenge: Topology-Aware Anatomical Segmentation of the Circle of Willis for CTA and MRA
Dec 29, 2023



The Circle of Willis (CoW) is an important network of arteries connecting major circulations of the brain. Its vascular architecture is believed to affect the risk, severity, and clinical outcome of serious neuro-vascular diseases. However, characterizing the highly variable CoW anatomy is still a manual and time-consuming expert task. The CoW is usually imaged by two angiographic imaging modalities, magnetic resonance angiography (MRA) and computed tomography angiography (CTA), but there exist limited public datasets with annotations on CoW anatomy, especially for CTA. Therefore we organized the TopCoW Challenge in 2023 with the release of an annotated CoW dataset and invited submissions worldwide for the CoW segmentation task, which attracted over 140 registered participants from four continents. TopCoW dataset was the first public dataset with voxel-level annotations for CoW's 13 vessel components, made possible by virtual-reality (VR) technology. It was also the first dataset with paired MRA and CTA from the same patients. TopCoW challenge aimed to tackle the CoW characterization problem as a multiclass anatomical segmentation task with an emphasis on topological metrics. The top performing teams managed to segment many CoW components to Dice scores around 90%, but with lower scores for communicating arteries and rare variants. There were also topological mistakes for predictions with high Dice scores. Additional topological analysis revealed further areas for improvement in detecting certain CoW components and matching CoW variant's topology accurately. TopCoW represented a first attempt at benchmarking the CoW anatomical segmentation task for MRA and CTA, both morphologically and topologically.
A Chebyshev Confidence Guided Source-Free Domain Adaptation Framework for Medical Image Segmentation
Oct 27, 2023



Source-free domain adaptation (SFDA) aims to adapt models trained on a labeled source domain to an unlabeled target domain without the access to source data. In medical imaging scenarios, the practical significance of SFDA methods has been emphasized due to privacy concerns. Recent State-of-the-art SFDA methods primarily rely on self-training based on pseudo-labels (PLs). Unfortunately, PLs suffer from accuracy deterioration caused by domain shift, and thus limit the effectiveness of the adaptation process. To address this issue, we propose a Chebyshev confidence guided SFDA framework to accurately assess the reliability of PLs and generate self-improving PLs for self-training. The Chebyshev confidence is estimated by calculating probability lower bound of the PL confidence, given the prediction and the corresponding uncertainty. Leveraging the Chebyshev confidence, we introduce two confidence-guided denoising methods: direct denoising and prototypical denoising. Additionally, we propose a novel teacher-student joint training scheme (TJTS) that incorporates a confidence weighting module to improve PLs iteratively. The TJTS, in collaboration with the denoising methods, effectively prevents the propagation of noise and enhances the accuracy of PLs. Extensive experiments in diverse domain scenarios validate the effectiveness of our proposed framework and establish its superiority over state-of-the-art SFDA methods. Our paper contributes to the field of SFDA by providing a novel approach for precisely estimating the reliability of pseudo-labels and a framework for obtaining high-quality PLs, resulting in improved adaptation performance.
NexToU: Efficient Topology-Aware U-Net for Medical Image Segmentation
May 25, 2023Convolutional neural networks (CNN) and Transformer variants have emerged as the leading medical image segmentation backbones. Nonetheless, due to their limitations in either preserving global image context or efficiently processing irregular shapes in visual objects, these backbones struggle to effectively integrate information from diverse anatomical regions and reduce inter-individual variability, particularly for the vasculature. Motivated by the successful breakthroughs of graph neural networks (GNN) in capturing topological properties and non-Euclidean relationships across various fields, we propose NexToU, a novel hybrid architecture for medical image segmentation. NexToU comprises improved Pool GNN and Swin GNN modules from Vision GNN (ViG) for learning both global and local topological representations while minimizing computational costs. To address the containment and exclusion relationships among various anatomical structures, we reformulate the topological interaction (TI) module based on the nature of binary trees, rapidly encoding the topological constraints into NexToU. Extensive experiments conducted on three datasets (including distinct imaging dimensions, disease types, and imaging modalities) demonstrate that our method consistently outperforms other state-of-the-art (SOTA) architectures. All the code is publicly available at https://github.com/PengchengShi1220/NexToU.