 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHippMetric: A skeletal-representation-based framework for cross-sectional and longitudinal hippocampal substructural morphometry
Dec 22, 2025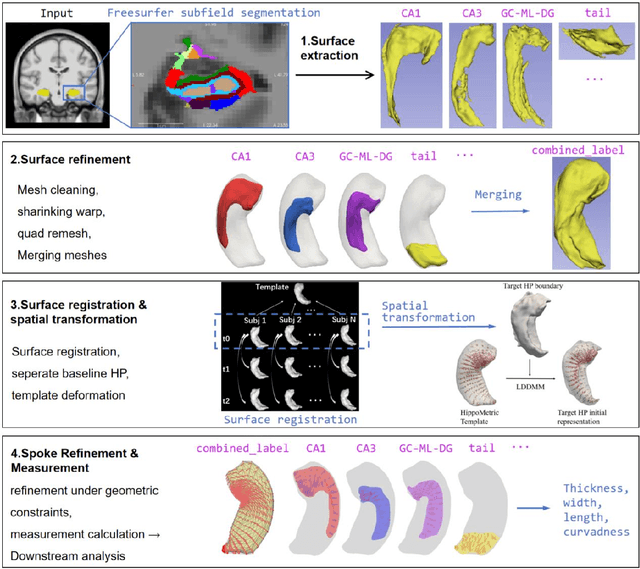
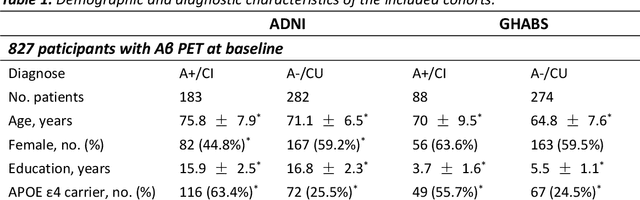
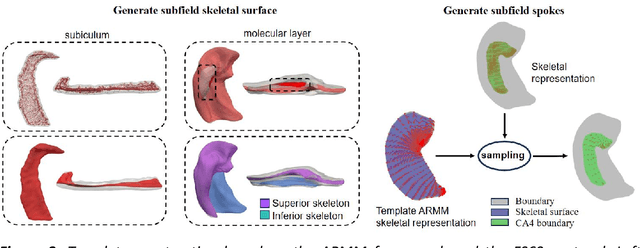
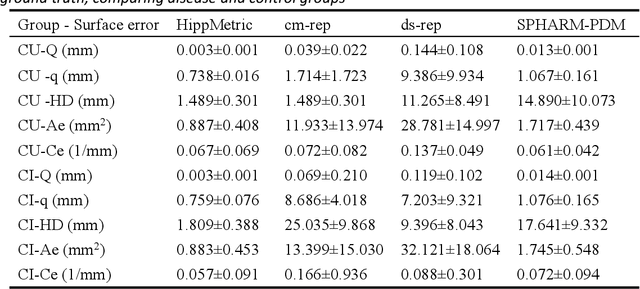
Accurate characterization of hippocampal substructure is crucial for detecting subtle structural changes and identifying early neurodegenerative biomarkers. However, high inter-subject variability and complex folding pattern of human hippocampus hinder consistent cross-subject and longitudinal analysis. Most existing approaches rely on subject-specific modelling and lack a stable intrinsic coordinate system to accommodate anatomical variability, which limits their ability to establish reliable inter- and intra-individual correspondence. To address this, we propose HippMetric, a skeletal representation (s-rep)-based framework for hippocampal substructural morphometry and point-wise correspondence across individuals and scans. HippMetric builds on the Axis-Referenced Morphometric Model (ARMM) and employs a deformable skeletal coordinate system aligned with hippocampal anatomy and function, providing a biologically grounded reference for correspondence. Our framework comprises two core modules: a skeletal-based coordinate system that respects the hippocampus' conserved longitudinal lamellar architecture, in which functional units (lamellae) are stacked perpendicular to the long-axis, enabling anatomically consistent localization across subjects and time; and individualized s-reps generated through surface reconstruction, deformation, and geometrically constrained spoke refinement, enforcing boundary adherence, orthogonality and non-intersection to produce mathematically valid skeletal geometry. Extensive experiments on two international cohorts demonstrate that HippMetric achieves higher accuracy, reliability, and correspondence stability compared to existing shape models.
Medverse: A Universal Model for Full-Resolution 3D Medical Image Segmentation, Transformation and Enhancement
Sep 11, 2025In-context learning (ICL) offers a promising paradigm for universal medical image analysis, enabling models to perform diverse image processing tasks without retraining. However, current ICL models for medical imaging remain limited in two critical aspects: they cannot simultaneously achieve high-fidelity predictions and global anatomical understanding, and there is no unified model trained across diverse medical imaging tasks (e.g., segmentation and enhancement) and anatomical regions. As a result, the full potential of ICL in medical imaging remains underexplored. Thus, we present \textbf{Medverse}, a universal ICL model for 3D medical imaging, trained on 22 datasets covering diverse tasks in universal image segmentation, transformation, and enhancement across multiple organs, imaging modalities, and clinical centers. Medverse employs a next-scale autoregressive in-context learning framework that progressively refines predictions from coarse to fine, generating consistent, full-resolution volumetric outputs and enabling multi-scale anatomical awareness. We further propose a blockwise cross-attention module that facilitates long-range interactions between context and target inputs while preserving computational efficiency through spatial sparsity. Medverse is extensively evaluated on a broad collection of held-out datasets covering previously unseen clinical centers, organs, species, and imaging modalities. Results demonstrate that Medverse substantially outperforms existing ICL baselines and establishes a novel paradigm for in-context learning. Code and model weights will be made publicly available. Our model are publicly available at https://github.com/jiesihu/Medverse.
Building 3D In-Context Learning Universal Model in Neuroimaging
Mar 04, 2025In-context learning (ICL), a type of universal model, demonstrates exceptional generalization across a wide range of tasks without retraining by leveraging task-specific guidance from context, making it particularly effective for the complex demands of neuroimaging. However, existing ICL models, which take 2D images as input, struggle to fully leverage the 3D anatomical structures in neuroimages, leading to a lack of global awareness and suboptimal performance. In this regard, we introduce Neuroverse3D, an ICL model capable of performing multiple neuroimaging tasks (e.g., segmentation, denoising, inpainting) in 3D. Neuroverse3D overcomes the large memory consumption due to 3D inputs through adaptive parallel-sequential context processing and a U-shape fusion strategy, allowing it to handle an unlimited number of context images. Additionally, we propose an optimized loss to balance multi-task training and enhance the focus on anatomical structures. Our study incorporates 43,674 3D scans from 19 neuroimaging datasets and evaluates Neuroverse3D on 14 diverse tasks using held-out test sets. The results demonstrate that Neuroverse3D significantly outperforms existing ICL models and closely matches the performance of task-specific models. The code and model weights are publicly released at: https://github.com/jiesihu/Neu3D.
NexToU: Efficient Topology-Aware U-Net for Medical Image Segmentation
May 25, 2023Convolutional neural networks (CNN) and Transformer variants have emerged as the leading medical image segmentation backbones. Nonetheless, due to their limitations in either preserving global image context or efficiently processing irregular shapes in visual objects, these backbones struggle to effectively integrate information from diverse anatomical regions and reduce inter-individual variability, particularly for the vasculature. Motivated by the successful breakthroughs of graph neural networks (GNN) in capturing topological properties and non-Euclidean relationships across various fields, we propose NexToU, a novel hybrid architecture for medical image segmentation. NexToU comprises improved Pool GNN and Swin GNN modules from Vision GNN (ViG) for learning both global and local topological representations while minimizing computational costs. To address the containment and exclusion relationships among various anatomical structures, we reformulate the topological interaction (TI) module based on the nature of binary trees, rapidly encoding the topological constraints into NexToU. Extensive experiments conducted on three datasets (including distinct imaging dimensions, disease types, and imaging modalities) demonstrate that our method consistently outperforms other state-of-the-art (SOTA) architectures. All the code is publicly available at https://github.com/PengchengShi1220/NexToU.
Accelerating Diffusion Models via Pre-segmentation Diffusion Sampling for Medical Image Segmentation
Oct 27, 2022



Based on the Denoising Diffusion Probabilistic Model (DDPM), medical image segmentation can be described as a conditional image generation task, which allows to compute pixel-wise uncertainty maps of the segmentation and allows an implicit ensemble of segmentations to boost the segmentation performance. However, DDPM requires many iterative denoising steps to generate segmentations from Gaussian noise, resulting in extremely inefficient inference. To mitigate the issue, we propose a principled acceleration strategy, called pre-segmentation diffusion sampling DDPM (PD-DDPM), which is specially used for medical image segmentation. The key idea is to obtain pre-segmentation results based on a separately trained segmentation network, and construct noise predictions (non-Gaussian distribution) according to the forward diffusion rule. We can then start with noisy predictions and use fewer reverse steps to generate segmentation results. Experiments show that PD-DDPM yields better segmentation results over representative baseline methods even if the number of reverse steps is significantly reduced. Moreover, PD-DDPM is orthogonal to existing advanced segmentation models, which can be combined to further improve the segmentation performance.
Multi-modal Dynamic Graph Network: Coupling Structural and Functional Connectome for Disease Diagnosis and Classification
Oct 25, 2022


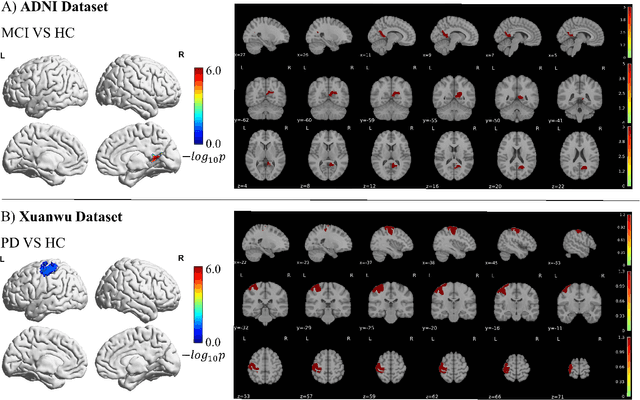
Multi-modal neuroimaging technology has greatlly facilitated the efficiency and diagnosis accuracy, which provides complementary information in discovering objective disease biomarkers. Conventional deep learning methods, e.g. convolutional neural networks, overlook relationships between nodes and fail to capture topological properties in graphs. Graph neural networks have been proven to be of great importance in modeling brain connectome networks and relating disease-specific patterns. However, most existing graph methods explicitly require known graph structures, which are not available in the sophisticated brain system. Especially in heterogeneous multi-modal brain networks, there exists a great challenge to model interactions among brain regions in consideration of inter-modal dependencies. In this study, we propose a Multi-modal Dynamic Graph Convolution Network (MDGCN) for structural and functional brain network learning. Our method benefits from modeling inter-modal representations and relating attentive multi-model associations into dynamic graphs with a compositional correspondence matrix. Moreover, a bilateral graph convolution layer is proposed to aggregate multi-modal representations in terms of multi-modal associations. Extensive experiments on three datasets demonstrate the superiority of our proposed method in terms of disease classification, with the accuracy of 90.4%, 85.9% and 98.3% in predicting Mild Cognitive Impairment (MCI), Parkinson's disease (PD), and schizophrenia (SCHZ) respectively. Furthermore, our statistical evaluations on the correspondence matrix exhibit a high correspondence with previous evidence of biomarkers.
Estimating Brain Age with Global and Local Dependencies
Sep 19, 2022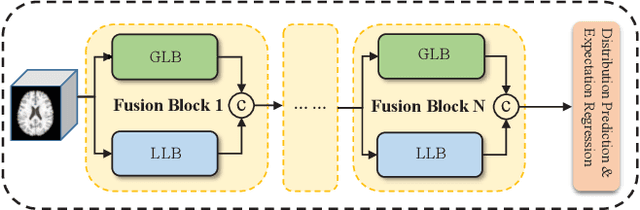
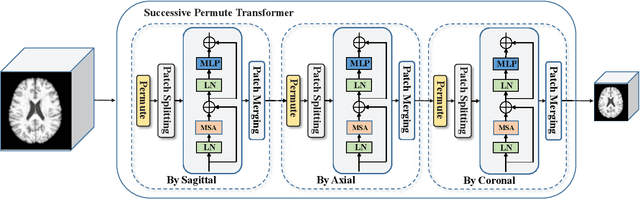
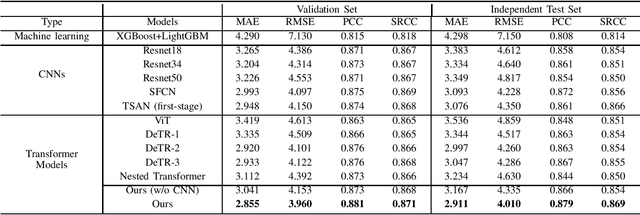
The brain age has been proven to be a phenotype of relevance to cognitive performance and brain disease. Achieving accurate brain age prediction is an essential prerequisite for optimizing the predicted brain-age difference as a biomarker. As a comprehensive biological characteristic, the brain age is hard to be exploited accurately with models using feature engineering and local processing such as local convolution and recurrent operations that process one local neighborhood at a time. Instead, Vision Transformers learn global attentive interaction of patch tokens, introducing less inductive bias and modeling long-range dependencies. In terms of this, we proposed a novel network for learning brain age interpreting with global and local dependencies, where the corresponding representations are captured by Successive Permuted Transformer (SPT) and convolution blocks. The SPT brings computation efficiency and locates the 3D spatial information indirectly via continuously encoding 2D slices from different views. Finally, we collect a large cohort of 22645 subjects with ages ranging from 14 to 97 and our network performed the best among a series of deep learning methods, yielding a mean absolute error (MAE) of 2.855 in validation set, and 2.911 in an independent test set.