 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedverse: A Universal Model for Full-Resolution 3D Medical Image Segmentation, Transformation and Enhancement
Sep 11, 2025In-context learning (ICL) offers a promising paradigm for universal medical image analysis, enabling models to perform diverse image processing tasks without retraining. However, current ICL models for medical imaging remain limited in two critical aspects: they cannot simultaneously achieve high-fidelity predictions and global anatomical understanding, and there is no unified model trained across diverse medical imaging tasks (e.g., segmentation and enhancement) and anatomical regions. As a result, the full potential of ICL in medical imaging remains underexplored. Thus, we present \textbf{Medverse}, a universal ICL model for 3D medical imaging, trained on 22 datasets covering diverse tasks in universal image segmentation, transformation, and enhancement across multiple organs, imaging modalities, and clinical centers. Medverse employs a next-scale autoregressive in-context learning framework that progressively refines predictions from coarse to fine, generating consistent, full-resolution volumetric outputs and enabling multi-scale anatomical awareness. We further propose a blockwise cross-attention module that facilitates long-range interactions between context and target inputs while preserving computational efficiency through spatial sparsity. Medverse is extensively evaluated on a broad collection of held-out datasets covering previously unseen clinical centers, organs, species, and imaging modalities. Results demonstrate that Medverse substantially outperforms existing ICL baselines and establishes a novel paradigm for in-context learning. Code and model weights will be made publicly available. Our model are publicly available at https://github.com/jiesihu/Medverse.
Building 3D In-Context Learning Universal Model in Neuroimaging
Mar 04, 2025In-context learning (ICL), a type of universal model, demonstrates exceptional generalization across a wide range of tasks without retraining by leveraging task-specific guidance from context, making it particularly effective for the complex demands of neuroimaging. However, existing ICL models, which take 2D images as input, struggle to fully leverage the 3D anatomical structures in neuroimages, leading to a lack of global awareness and suboptimal performance. In this regard, we introduce Neuroverse3D, an ICL model capable of performing multiple neuroimaging tasks (e.g., segmentation, denoising, inpainting) in 3D. Neuroverse3D overcomes the large memory consumption due to 3D inputs through adaptive parallel-sequential context processing and a U-shape fusion strategy, allowing it to handle an unlimited number of context images. Additionally, we propose an optimized loss to balance multi-task training and enhance the focus on anatomical structures. Our study incorporates 43,674 3D scans from 19 neuroimaging datasets and evaluates Neuroverse3D on 14 diverse tasks using held-out test sets. The results demonstrate that Neuroverse3D significantly outperforms existing ICL models and closely matches the performance of task-specific models. The code and model weights are publicly released at: https://github.com/jiesihu/Neu3D.
Advancing Brain Imaging Analysis Step-by-step via Progressive Self-paced Learning
Jul 23, 2024



Recent advancements in deep learning have shifted the development of brain imaging analysis. However, several challenges remain, such as heterogeneity, individual variations, and the contradiction between the high dimensionality and small size of brain imaging datasets. These issues complicate the learning process, preventing models from capturing intrinsic, meaningful patterns and potentially leading to suboptimal performance due to biases and overfitting. Curriculum learning (CL) presents a promising solution by organizing training examples from simple to complex, mimicking the human learning process, and potentially fostering the development of more robust and accurate models. Despite its potential, the inherent limitations posed by small initial training datasets present significant challenges, including overfitting and poor generalization. In this paper, we introduce the Progressive Self-Paced Distillation (PSPD) framework, employing an adaptive and progressive pacing and distillation mechanism. This allows for dynamic curriculum adjustments based on the states of both past and present models. The past model serves as a teacher, guiding the current model with gradually refined curriculum knowledge and helping prevent the loss of previously acquired knowledge. We validate PSPD's efficacy and adaptability across various convolutional neural networks using the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset, underscoring its superiority in enhancing model performance and generalization capabilities. The source code for this approach will be released at https://github.com/Hrychen7/PSPD.
Centerline Boundary Dice Loss for Vascular Segmentation
Jul 01, 2024

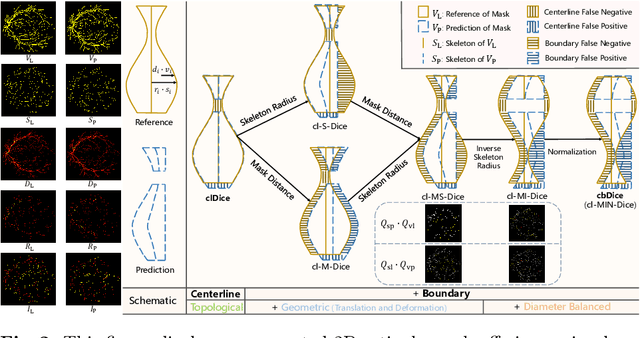
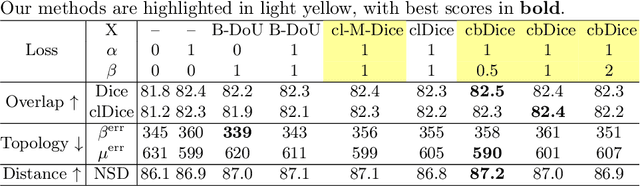
Vascular segmentation in medical imaging plays a crucial role in analysing morphological and functional assessments. Traditional methods, like the centerline Dice (clDice) loss, ensure topology preservation but falter in capturing geometric details, especially under translation and deformation. The combination of clDice with traditional Dice loss can lead to diameter imbalance, favoring larger vessels. Addressing these challenges, we introduce the centerline boundary Dice (cbDice) loss function, which harmonizes topological integrity and geometric nuances, ensuring consistent segmentation across various vessel sizes. cbDice enriches the clDice approach by including boundary-aware aspects, thereby improving geometric detail recognition. It matches the performance of the boundary difference over union (B-DoU) loss through a mask-distance-based approach, enhancing traslation sensitivity. Crucially, cbDice incorporates radius information from vascular skeletons, enabling uniform adaptation to vascular diameter changes and maintaining balance in branch growth and fracture impacts. Furthermore, we conducted a theoretical analysis of clDice variants (cl-X-Dice). We validated cbDice's efficacy on three diverse vascular segmentation datasets, encompassing both 2D and 3D, and binary and multi-class segmentation. Particularly, the method integrated with cbDice demonstrated outstanding performance on the MICCAI 2023 TopCoW Challenge dataset. Our code is made publicly available at: https://github.com/PengchengShi1220/cbDice.
A Chebyshev Confidence Guided Source-Free Domain Adaptation Framework for Medical Image Segmentation
Oct 27, 2023



Source-free domain adaptation (SFDA) aims to adapt models trained on a labeled source domain to an unlabeled target domain without the access to source data. In medical imaging scenarios, the practical significance of SFDA methods has been emphasized due to privacy concerns. Recent State-of-the-art SFDA methods primarily rely on self-training based on pseudo-labels (PLs). Unfortunately, PLs suffer from accuracy deterioration caused by domain shift, and thus limit the effectiveness of the adaptation process. To address this issue, we propose a Chebyshev confidence guided SFDA framework to accurately assess the reliability of PLs and generate self-improving PLs for self-training. The Chebyshev confidence is estimated by calculating probability lower bound of the PL confidence, given the prediction and the corresponding uncertainty. Leveraging the Chebyshev confidence, we introduce two confidence-guided denoising methods: direct denoising and prototypical denoising. Additionally, we propose a novel teacher-student joint training scheme (TJTS) that incorporates a confidence weighting module to improve PLs iteratively. The TJTS, in collaboration with the denoising methods, effectively prevents the propagation of noise and enhances the accuracy of PLs. Extensive experiments in diverse domain scenarios validate the effectiveness of our proposed framework and establish its superiority over state-of-the-art SFDA methods. Our paper contributes to the field of SFDA by providing a novel approach for precisely estimating the reliability of pseudo-labels and a framework for obtaining high-quality PLs, resulting in improved adaptation performance.
DECOR-NET: A COVID-19 Lung Infection Segmentation Network Improved by Emphasizing Low-level Features and Decorrelating Features
Feb 28, 2023Since 2019, coronavirus Disease 2019 (COVID-19) has been widely spread and posed a serious threat to public health. Chest Computed Tomography (CT) holds great potential for screening and diagnosis of this disease. The segmentation of COVID-19 CT imaging can achieves quantitative evaluation of infections and tracks disease progression. COVID-19 infections are characterized by high heterogeneity and unclear boundaries, so capturing low-level features such as texture and intensity is critical for segmentation. However, segmentation networks that emphasize low-level features are still lacking. In this work, we propose a DECOR-Net capable of capturing more decorrelated low-level features. The channel re-weighting strategy is applied to obtain plenty of low-level features and the dependencies between channels are reduced by proposed decorrelation loss. Experiments show that DECOR-Net outperforms other cutting-edge methods and surpasses the baseline by 5.1% and 4.9% in terms of Dice coefficient and intersection over union. Moreover, the proposed decorrelation loss can improve the performance constantly under different settings. The Code is available at https://github.com/jiesihu/DECOR-Net.git.
Evaluation of Multimodal Semantic Segmentation using RGB-D Data
Mar 31, 2021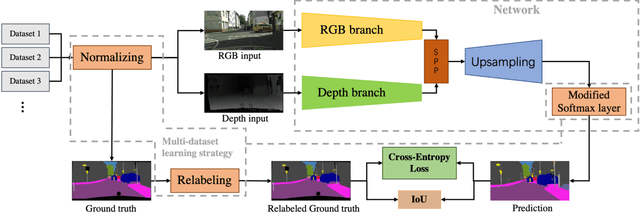
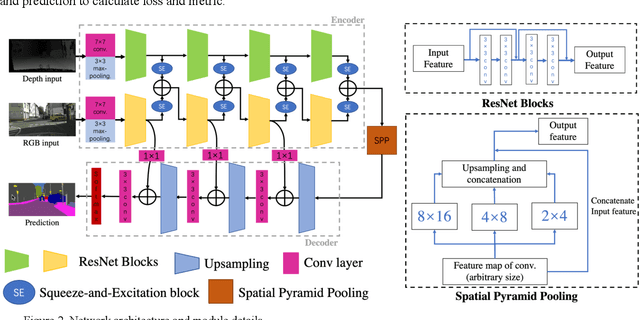


Our goal is to develop stable, accurate, and robust semantic scene understanding methods for wide-area scene perception and understanding, especially in challenging outdoor environments. To achieve this, we are exploring and evaluating a range of related technology and solutions, including AI-driven multimodal scene perception, fusion, processing, and understanding. This work reports our efforts on the evaluation of a state-of-the-art approach for semantic segmentation with multiple RGB and depth sensing data. We employ four large datasets composed of diverse urban and terrain scenes and design various experimental methods and metrics. In addition, we also develop new strategies of multi-datasets learning to improve the detection and recognition of unseen objects. Extensive experiments, implementations, and results are reported in the paper.
CalibDNN: Multimodal Sensor Calibration for Perception Using Deep Neural Networks
Mar 27, 2021Current perception systems often carry multimodal imagers and sensors such as 2D cameras and 3D LiDAR sensors. To fuse and utilize the data for downstream perception tasks, robust and accurate calibration of the multimodal sensor data is essential. We propose a novel deep learning-driven technique (CalibDNN) for accurate calibration among multimodal sensor, specifically LiDAR-Camera pairs. The key innovation of the proposed work is that it does not require any specific calibration targets or hardware assistants, and the entire processing is fully automatic with a single model and single iteration. Results comparison among different methods and extensive experiments on different datasets demonstrates the state-of-the-art performance.