 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta Transfer of Self-Supervised Knowledge: Foundation Model in Action for Post-Traumatic Epilepsy Prediction
Dec 21, 2023Despite the impressive advancements achieved using deep-learning for functional brain activity analysis, the heterogeneity of functional patterns and scarcity of imaging data still pose challenges in tasks such as prediction of future onset of Post-Traumatic Epilepsy (PTE) from data acquired shortly after traumatic brain injury (TBI). Foundation models pre-trained on separate large-scale datasets can improve the performance from scarce and heterogeneous datasets. For functional Magnetic Resonance Imaging (fMRI), while data may be abundantly available from healthy controls, clinical data is often scarce, limiting the ability of foundation models to identify clinically-relevant features. We overcome this limitation by introducing a novel training strategy for our foundation model by integrating meta-learning with self-supervised learning to improve the generalization from normal to clinical features. In this way we enable generalization to other downstream clinical tasks, in our case prediction of PTE. To achieve this, we perform self-supervised training on the control dataset to focus on inherent features that are not limited to a particular supervised task while applying meta-learning, which strongly improves the model's generalizability using bi-level optimization. Through experiments on neurological disorder classification tasks, we demonstrate that the proposed strategy significantly improves task performance on small-scale clinical datasets. To explore the generalizability of the foundation model in downstream applications, we then apply the model to an unseen TBI dataset for prediction of PTE using zero-shot learning. Results further demonstrated the enhanced generalizability of our foundation model.
SemST: Semantically Consistent Multi-Scale Image Translation via Structure-Texture Alignment
Oct 08, 2023Unsupervised image-to-image (I2I) translation learns cross-domain image mapping that transfers input from the source domain to output in the target domain while preserving its semantics. One challenge is that different semantic statistics in source and target domains result in content discrepancy known as semantic distortion. To address this problem, a novel I2I method that maintains semantic consistency in translation is proposed and named SemST in this work. SemST reduces semantic distortion by employing contrastive learning and aligning the structural and textural properties of input and output by maximizing their mutual information. Furthermore, a multi-scale approach is introduced to enhance translation performance, thereby enabling the applicability of SemST to domain adaptation in high-resolution images. Experiments show that SemST effectively mitigates semantic distortion and achieves state-of-the-art performance. Also, the application of SemST to domain adaptation (DA) is explored. It is demonstrated by preliminary experiments that SemST can be utilized as a beneficial pre-training for the semantic segmentation task.
A Study on Improving Realism of Synthetic Data for Machine Learning
Apr 28, 2023Synthetic-to-real data translation using generative adversarial learning has achieved significant success in improving synthetic data. Yet, limited studies focus on deep evaluation and comparison of adversarial training on general-purpose synthetic data for machine learning. This work aims to train and evaluate a synthetic-to-real generative model that transforms the synthetic renderings into more realistic styles on general-purpose datasets conditioned with unlabeled real-world data. Extensive performance evaluation and comparison have been conducted through qualitative and quantitative metrics and a defined downstream perception task.
Unsupervised Synthetic Image Refinement via Contrastive Learning and Consistent Semantic-Structural Constraints
Apr 26, 2023Ensuring the realism of computer-generated synthetic images is crucial to deep neural network (DNN) training. Due to different semantic distributions between synthetic and real-world captured datasets, there exists semantic mismatch between synthetic and refined images, which in turn results in the semantic distortion. Recently, contrastive learning (CL) has been successfully used to pull correlated patches together and push uncorrelated ones apart. In this work, we exploit semantic and structural consistency between synthetic and refined images and adopt CL to reduce the semantic distortion. Besides, we incorporate hard negative mining to improve the performance furthermore. We compare the performance of our method with several other benchmarking methods using qualitative and quantitative measures and show that our method offers the state-of-the-art performance.
LGSQE: Lightweight Generated Sample Quality Evaluatoin
Nov 08, 2022



Despite prolific work on evaluating generative models, little research has been done on the quality evaluation of an individual generated sample. To address this problem, a lightweight generated sample quality evaluation (LGSQE) method is proposed in this work. In the training stage of LGSQE, a binary classifier is trained on real and synthetic samples, where real and synthetic data are labeled by 0 and 1, respectively. In the inference stage, the classifier assigns soft labels (ranging from 0 to 1) to each generated sample. The value of soft label indicates the quality level; namely, the quality is better if its soft label is closer to 0. LGSQE can serve as a post-processing module for quality control. Furthermore, LGSQE can be used to evaluate the performance of generative models, such as accuracy, AUC, precision and recall, by aggregating sample-level quality. Experiments are conducted on CIFAR-10 and MNIST to demonstrate that LGSQE can preserve the same performance rank order as that predicted by the Frechet Inception Distance (FID) but with significantly lower complexity.
TGHop: An Explainable, Efficient and Lightweight Method for Texture Generation
Jul 08, 2021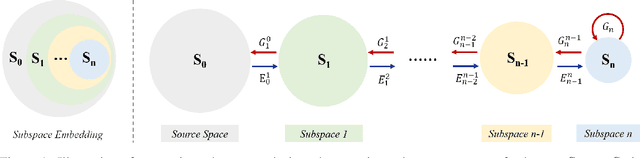
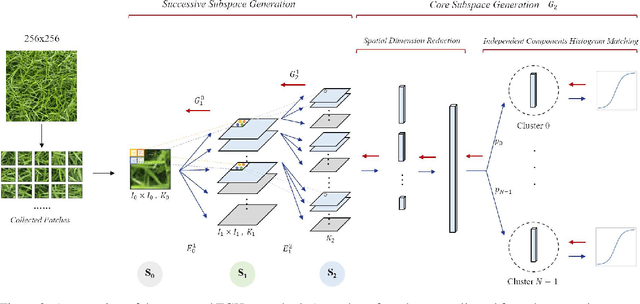

An explainable, efficient and lightweight method for texture generation, called TGHop (an acronym of Texture Generation PixelHop), is proposed in this work. Although synthesis of visually pleasant texture can be achieved by deep neural networks, the associated models are large in size, difficult to explain in theory, and computationally expensive in training. In contrast, TGHop is small in its model size, mathematically transparent, efficient in training and inference, and able to generate high quality texture. Given an exemplary texture, TGHop first crops many sample patches out of it to form a collection of sample patches called the source. Then, it analyzes pixel statistics of samples from the source and obtains a sequence of fine-to-coarse subspaces for these patches by using the PixelHop++ framework. To generate texture patches with TGHop, we begin with the coarsest subspace, which is called the core, and attempt to generate samples in each subspace by following the distribution of real samples. Finally, texture patches are stitched to form texture images of a large size. It is demonstrated by experimental results that TGHop can generate texture images of superior quality with a small model size and at a fast speed.
Evaluation of Multimodal Semantic Segmentation using RGB-D Data
Mar 31, 2021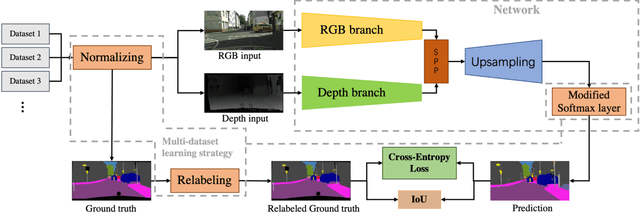
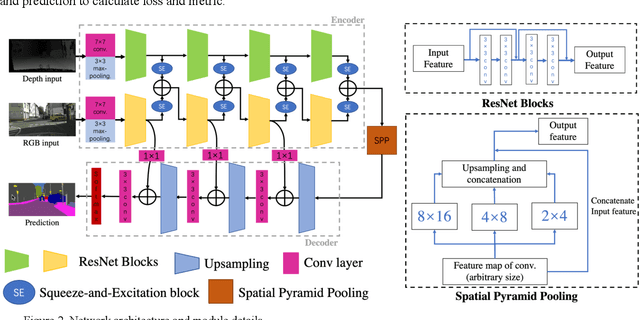


Our goal is to develop stable, accurate, and robust semantic scene understanding methods for wide-area scene perception and understanding, especially in challenging outdoor environments. To achieve this, we are exploring and evaluating a range of related technology and solutions, including AI-driven multimodal scene perception, fusion, processing, and understanding. This work reports our efforts on the evaluation of a state-of-the-art approach for semantic segmentation with multiple RGB and depth sensing data. We employ four large datasets composed of diverse urban and terrain scenes and design various experimental methods and metrics. In addition, we also develop new strategies of multi-datasets learning to improve the detection and recognition of unseen objects. Extensive experiments, implementations, and results are reported in the paper.
CalibDNN: Multimodal Sensor Calibration for Perception Using Deep Neural Networks
Mar 27, 2021Current perception systems often carry multimodal imagers and sensors such as 2D cameras and 3D LiDAR sensors. To fuse and utilize the data for downstream perception tasks, robust and accurate calibration of the multimodal sensor data is essential. We propose a novel deep learning-driven technique (CalibDNN) for accurate calibration among multimodal sensor, specifically LiDAR-Camera pairs. The key innovation of the proposed work is that it does not require any specific calibration targets or hardware assistants, and the entire processing is fully automatic with a single model and single iteration. Results comparison among different methods and extensive experiments on different datasets demonstrates the state-of-the-art performance.
NITES: A Non-Parametric Interpretable Texture Synthesis Method
Sep 02, 2020



A non-parametric interpretable texture synthesis method, called the NITES method, is proposed in this work. Although automatic synthesis of visually pleasant texture can be achieved by deep neural networks nowadays, the associated generation models are mathematically intractable and their training demands higher computational cost. NITES offers a new texture synthesis solution to address these shortcomings. NITES is mathematically transparent and efficient in training and inference. The input is a single exemplary texture image. The NITES method crops out patches from the input and analyzes the statistical properties of these texture patches to obtain their joint spatial-spectral representations. Then, the probabilistic distributions of samples in the joint spatial-spectral spaces are characterized. Finally, numerous texture images that are visually similar to the exemplary texture image can be generated automatically. Experimental results are provided to show the superior quality of generated texture images and efficiency of the proposed NITES method in terms of both training and inference time.