 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Feasibility Study of Task-Based fMRI at 0.55 T
May 26, 20250.55T MRI offers advantages compared to conventional field strengths, including reduced susceptibility artifacts and better compatibility with simultaneous EEG recordings. However, reliable task-based fMRI at 0.55T has not been significantly demonstrated. In this study, we establish a robust task-based fMRI protocol and analysis pipeline at 0.55T that achieves full brain coverage and results comparable to what is expected for activation extent and location. We attempted fMRI at 0.55T by combining EPI acquisition with custom analysis techniques. Finger-tapping and visual tasks were used, comparing 5- and 10-minute runs to enhance activation detection. The results show significant activations, demonstrating that high-quality task-based fMRI is achievable at 0.55T in single subjects. This study demonstrates that reliable task-based fMRI is feasible on 0.55T scanners, potentially broadening functional neuroimaging access in clinical and research settings where high-field MRI is unavailable or impractical, supporting broader diagnostic and research applications.
Multi-Center Fetal Brain Tissue Annotation (FeTA) Challenge 2022 Results
Feb 08, 2024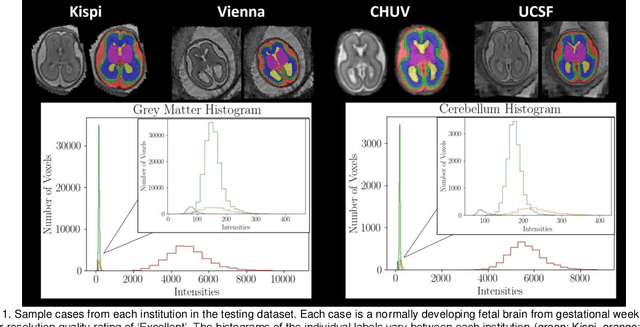
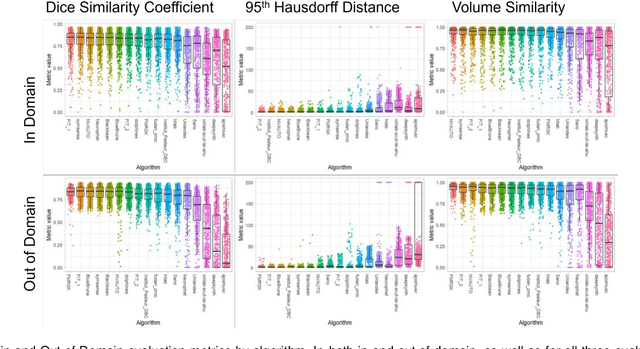
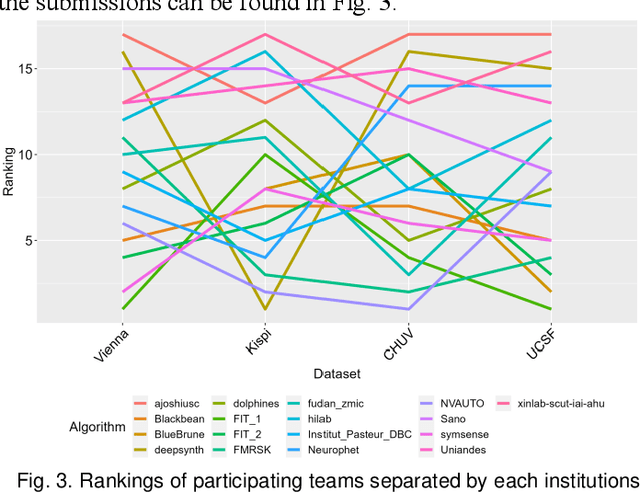
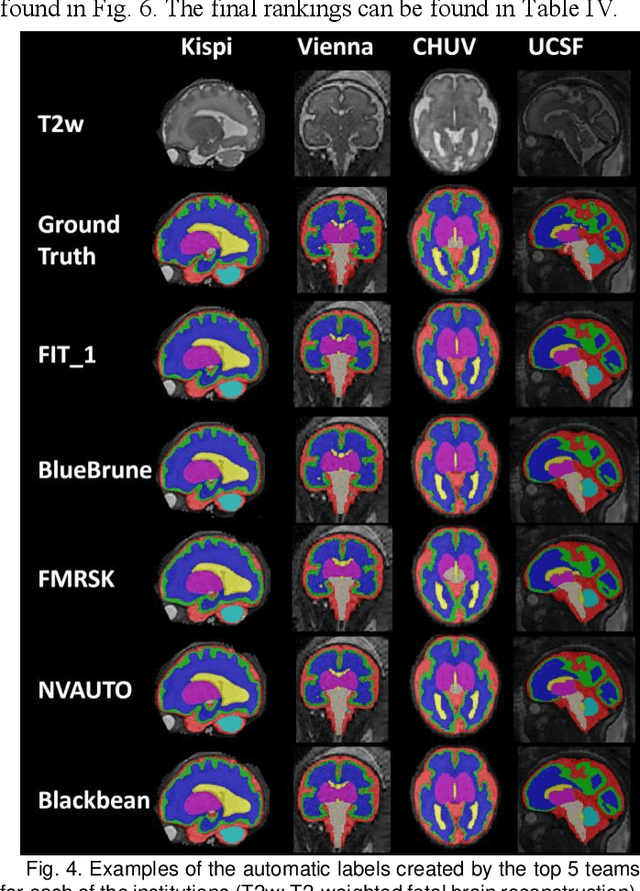
Segmentation is a critical step in analyzing the developing human fetal brain. There have been vast improvements in automatic segmentation methods in the past several years, and the Fetal Brain Tissue Annotation (FeTA) Challenge 2021 helped to establish an excellent standard of fetal brain segmentation. However, FeTA 2021 was a single center study, and the generalizability of algorithms across different imaging centers remains unsolved, limiting real-world clinical applicability. The multi-center FeTA Challenge 2022 focuses on advancing the generalizability of fetal brain segmentation algorithms for magnetic resonance imaging (MRI). In FeTA 2022, the training dataset contained images and corresponding manually annotated multi-class labels from two imaging centers, and the testing data contained images from these two imaging centers as well as two additional unseen centers. The data from different centers varied in many aspects, including scanners used, imaging parameters, and fetal brain super-resolution algorithms applied. 16 teams participated in the challenge, and 17 algorithms were evaluated. Here, a detailed overview and analysis of the challenge results are provided, focusing on the generalizability of the submissions. Both in- and out of domain, the white matter and ventricles were segmented with the highest accuracy, while the most challenging structure remains the cerebral cortex due to anatomical complexity. The FeTA Challenge 2022 was able to successfully evaluate and advance generalizability of multi-class fetal brain tissue segmentation algorithms for MRI and it continues to benchmark new algorithms. The resulting new methods contribute to improving the analysis of brain development in utero.
Meta Transfer of Self-Supervised Knowledge: Foundation Model in Action for Post-Traumatic Epilepsy Prediction
Dec 21, 2023Despite the impressive advancements achieved using deep-learning for functional brain activity analysis, the heterogeneity of functional patterns and scarcity of imaging data still pose challenges in tasks such as prediction of future onset of Post-Traumatic Epilepsy (PTE) from data acquired shortly after traumatic brain injury (TBI). Foundation models pre-trained on separate large-scale datasets can improve the performance from scarce and heterogeneous datasets. For functional Magnetic Resonance Imaging (fMRI), while data may be abundantly available from healthy controls, clinical data is often scarce, limiting the ability of foundation models to identify clinically-relevant features. We overcome this limitation by introducing a novel training strategy for our foundation model by integrating meta-learning with self-supervised learning to improve the generalization from normal to clinical features. In this way we enable generalization to other downstream clinical tasks, in our case prediction of PTE. To achieve this, we perform self-supervised training on the control dataset to focus on inherent features that are not limited to a particular supervised task while applying meta-learning, which strongly improves the model's generalizability using bi-level optimization. Through experiments on neurological disorder classification tasks, we demonstrate that the proposed strategy significantly improves task performance on small-scale clinical datasets. To explore the generalizability of the foundation model in downstream applications, we then apply the model to an unseen TBI dataset for prediction of PTE using zero-shot learning. Results further demonstrated the enhanced generalizability of our foundation model.
Neuro-GPT: Developing A Foundation Model for EEG
Nov 11, 2023To handle the scarcity and heterogeneity of electroencephalography (EEG) data for Brain-Computer Interface (BCI) tasks, and to harness the power of large publicly available data sets, we propose Neuro-GPT, a foundation model consisting of an EEG encoder and a GPT model. The foundation model is pre-trained on a large-scale data set using a self-supervised task that learns how to reconstruct masked EEG segments. We then fine-tune the model on a Motor Imagery Classification task to validate its performance in a low-data regime (9 subjects). Our experiments demonstrate that applying a foundation model can significantly improve classification performance compared to a model trained from scratch, which provides evidence for the generalizability of the foundation model and its ability to address challenges of data scarcity and heterogeneity in EEG.
Toward Improved Generalization: Meta Transfer of Self-supervised Knowledge on Graphs
Dec 16, 2022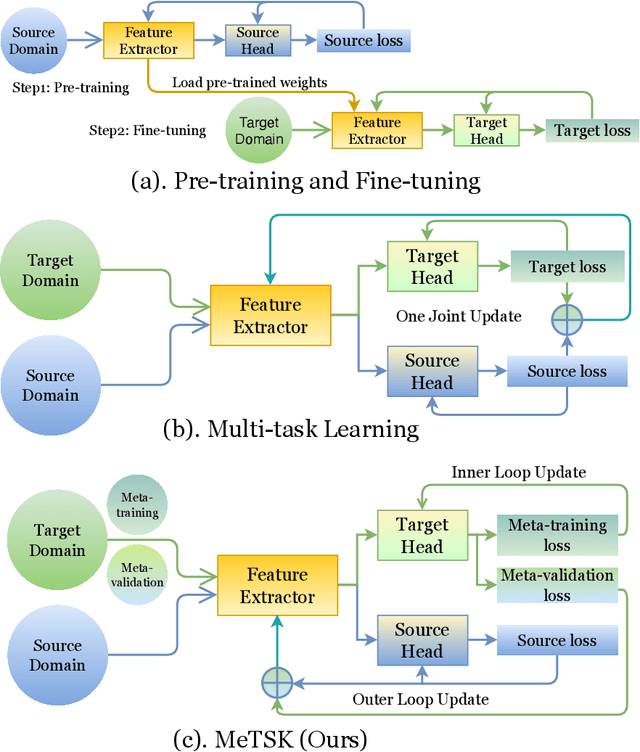

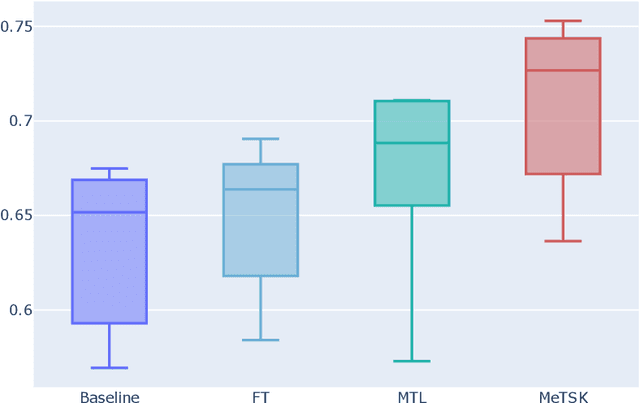

Despite the remarkable success achieved by graph convolutional networks for functional brain activity analysis, the heterogeneity of functional patterns and the scarcity of imaging data still pose challenges in many tasks. Transferring knowledge from a source domain with abundant training data to a target domain is effective for improving representation learning on scarce training data. However, traditional transfer learning methods often fail to generalize the pre-trained knowledge to the target task due to domain discrepancy. Self-supervised learning on graphs can increase the generalizability of graph features since self-supervision concentrates on inherent graph properties that are not limited to a particular supervised task. We propose a novel knowledge transfer strategy by integrating meta-learning with self-supervised learning to deal with the heterogeneity and scarcity of fMRI data. Specifically, we perform a self-supervised task on the source domain and apply meta-learning, which strongly improves the generalizability of the model using the bi-level optimization, to transfer the self-supervised knowledge to the target domain. Through experiments on a neurological disorder classification task, we demonstrate that the proposed strategy significantly improves target task performance by increasing the generalizability and transferability of graph-based knowledge.
Semi-supervised Learning with Robust Loss in Brain Segmentation
Dec 03, 2022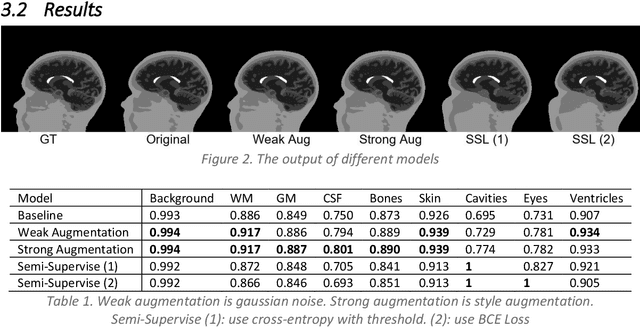
In this work, we used a semi-supervised learning method to train deep learning model that can segment the brain MRI images. The semi-supervised model uses less labeled data, and the performance is competitive with the supervised model with full labeled data. This framework could reduce the cost of labeling MRI images. We also introduced robust loss to reduce the noise effects of inaccurate labels generated in semi-supervised learning.
Semi-supervised Learning using Robust Loss
Mar 03, 2022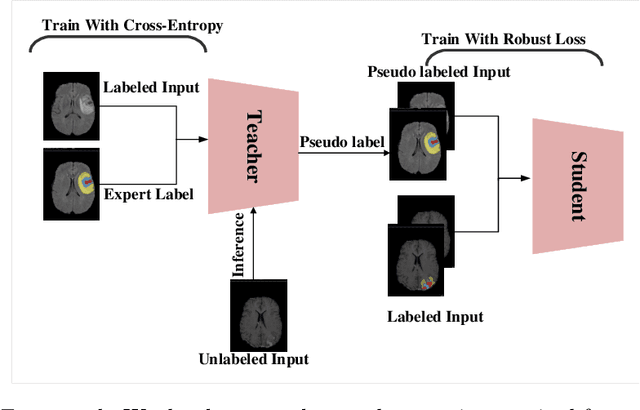

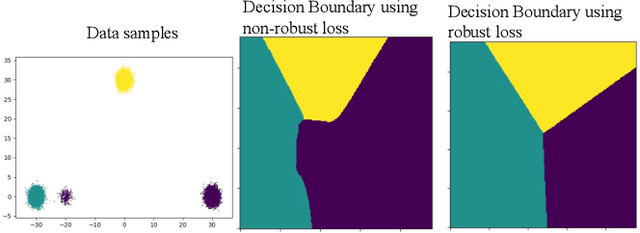

The amount of manually labeled data is limited in medical applications, so semi-supervised learning and automatic labeling strategies can be an asset for training deep neural networks. However, the quality of the automatically generated labels can be uneven and inferior to manual labels. In this paper, we suggest a semi-supervised training strategy for leveraging both manually labeled data and extra unlabeled data. In contrast to the existing approaches, we apply robust loss for the automated labeled data to automatically compensate for the uneven data quality using a teacher-student framework. First, we generate pseudo-labels for unlabeled data using a teacher model pre-trained on labeled data. These pseudo-labels are noisy, and using them along with labeled data for training a deep neural network can severely degrade learned feature representations and the generalization of the network. Here we mitigate the effect of these pseudo-labels by using robust loss functions. Specifically, we use three robust loss functions, namely beta cross-entropy, symmetric cross-entropy, and generalized cross-entropy. We show that our proposed strategy improves the model performance by compensating for the uneven quality of labels in image classification as well as segmentation applications.
fMRI-Kernel Regression: A Kernel-based Method for Pointwise Statistical Analysis of rs-fMRI for Population Studies
Dec 13, 2020



Due to the spontaneous nature of resting-state fMRI (rs-fMRI) signals, cross-subject comparison and therefore, group studies of rs-fMRI are challenging. Most existing group comparison methods use features extracted from the fMRI time series, such as connectivity features, independent component analysis (ICA), and functional connectivity density (FCD) methods. However, in group studies, especially in the case of spectrum disorders, distances to a single atlas or a representative subject do not fully reflect the differences between subjects that may lie on a multi-dimensional spectrum. Moreover, there may not exist an individual subject or even an average atlas in such cases that is representative of all subjects. Here we describe an approach that measures pairwise distances between the synchronized rs-fMRI signals of pairs of subjects instead of to a single reference point. We also present a method for fMRI data comparison that leverages this generated pairwise feature to establish a radial basis function kernel matrix. This kernel matrix is used in turn to perform kernel regression of rs-fMRI to a clinical variable such as a cognitive or neurophysiological performance score of interest. This method opens a new pointwise analysis paradigm for fMRI data. We demonstrate the application of this method by performing a pointwise analysis on the cortical surface using rs-fMRI data to identify cortical regions associated with variability in ADHD index. While pointwise analysis methods are common in anatomical studies such as cortical thickness analysis and voxel- and tensor-based morphometry and its variants, such a method is lacking for rs-fMRI and could improve the utility of rs-fMRI for group studies. The method presented in this paper is aimed at filling this gap.
Addressing Variance Shrinkage in Variational Autoencoders using Quantile Regression
Oct 18, 2020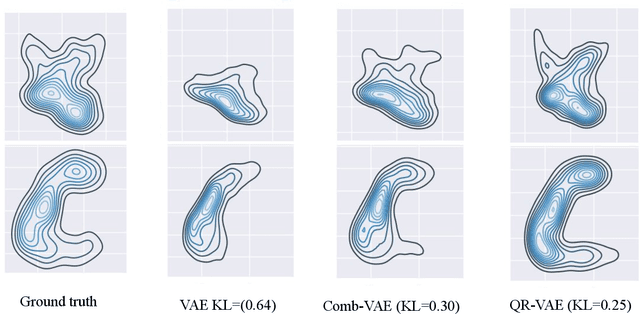
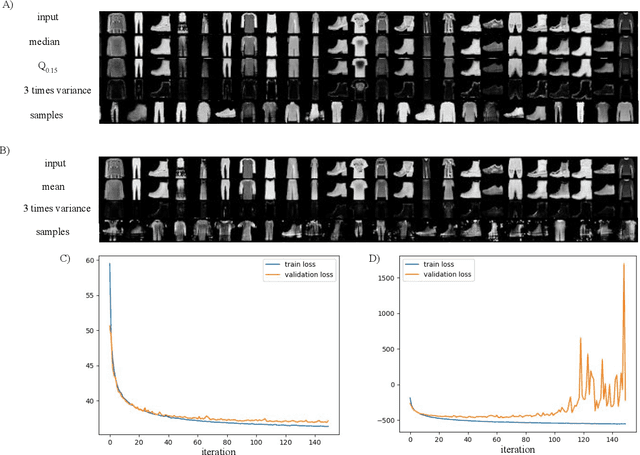
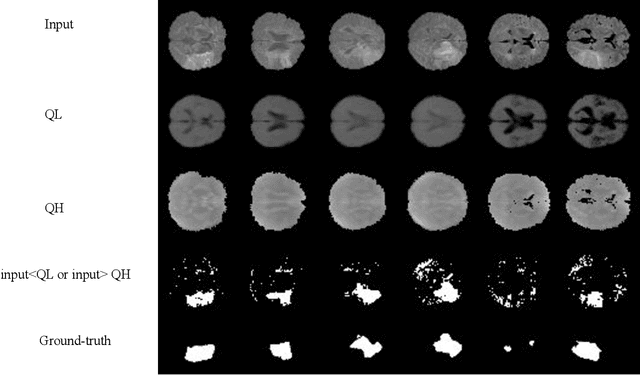
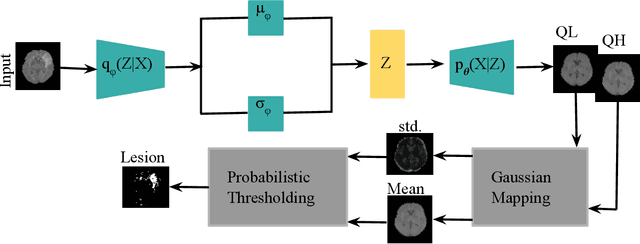
Estimation of uncertainty in deep learning models is of vital importance, especially in medical imaging, where reliance on inference without taking into account uncertainty could lead to misdiagnosis. Recently, the probabilistic Variational AutoEncoder (VAE) has become a popular model for anomaly detection in applications such as lesion detection in medical images. The VAE is a generative graphical model that is used to learn the data distribution from samples and then generate new samples from this distribution. By training on normal samples, the VAE can be used to detect inputs that deviate from this learned distribution. The VAE models the output as a conditionally independent Gaussian characterized by means and variances for each output dimension. VAEs can therefore use reconstruction probability instead of reconstruction error for anomaly detection. Unfortunately, joint optimization of both mean and variance in the VAE leads to the well-known problem of shrinkage or underestimation of variance. We describe an alternative approach that avoids this variance shrinkage problem by using quantile regression. Using estimated quantiles to compute mean and variance under the Gaussian assumption, we compute reconstruction probability as a principled approach to outlier or anomaly detection. Results on simulated and Fashion MNIST data demonstrate the effectiveness of our approach. We also show how our approach can be used for principled heterogeneous thresholding for lesion detection in brain images.
Robust Variational Autoencoder for Tabular Data with Beta Divergence
Jun 16, 2020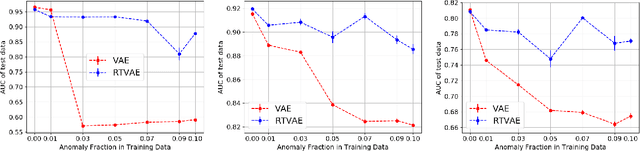
We propose a robust variational autoencoder with $\beta$ divergence for tabular data (RTVAE) with mixed categorical and continuous features. Variational autoencoders (VAE) and their variations are popular frameworks for anomaly detection problems. The primary assumption is that we can learn representations for normal patterns via VAEs and any deviation from that can indicate anomalies. However, the training data itself can contain outliers. The source of outliers in training data include the data collection process itself (random noise) or a malicious attacker (data poisoning) who may target to degrade the performance of the machine learning model. In either case, these outliers can disproportionately affect the training process of VAEs and may lead to wrong conclusions about what the normal behavior is. In this work, we derive a novel form of a variational autoencoder for tabular data sets with categorical and continuous features that is robust to outliers in training data. Our results on the anomaly detection application for network traffic datasets demonstrate the effectiveness of our approach.