 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Post-Traumatic Epilepsy from Clinical Records using Large Language Model Embeddings
Apr 16, 2026Objective: Post-traumatic epilepsy (PTE) is a debilitating neurological disorder that develops after traumatic brain injury (TBI). Early prediction of PTE remains challenging due to heterogeneous clinical data, limited positive cases, and reliance on resource-intensive neuroimaging data. We investigate whether routinely collected acute clinical records alone can support early PTE prediction using language model-based approaches. Methods: Using a curated subset of the TRACK-TBI cohort, we developed an automated PTE prediction framework that implements pretrained large language models (LLMs) as fixed feature extractors to encode clinical records. Tabular features, LLM-generated embeddings, and hybrid feature representations were evaluated using gradient-boosted tree classifiers under stratified cross-validation. Results: LLM embeddings achieved performance improvements by capturing contextual clinical information compared to using tabular features alone. The best performance was achieved by a modality-aware feature fusion strategy combining tabular features and LLM embeddings, achieving an AUC-ROC of 0.892 and AUPRC of 0.798. Acute post-traumatic seizures, injury severity, neurosurgical intervention, and ICU stay are key contributors to the predictive performance. Significance: These findings demonstrate that routine acute clinical records contain information suitable for early PTE risk prediction using LLM embeddings in conjunction with gradient-boosted tree classifiers. This approach represents a promising complement to imaging-based prediction.
AirGlove: Exploring Egocentric 3D Hand Tracking and Appearance Generalization for Sensing Gloves
Feb 05, 2026Sensing gloves have become important tools for teleoperation and robotic policy learning as they are able to provide rich signals like speed, acceleration and tactile feedback. A common approach to track gloved hands is to directly use the sensor signals (e.g., angular velocity, gravity orientation) to estimate 3D hand poses. However, sensor-based tracking can be restrictive in practice as the accuracy is often impacted by sensor signal and calibration quality. Recent advances in vision-based approaches have achieved strong performance on human hands via large-scale pre-training, but their performance on gloved hands with distinct visual appearances remains underexplored. In this work, we present the first systematic evaluation of vision-based hand tracking models on gloved hands under both zero-shot and fine-tuning setups. Our analysis shows that existing bare-hand models suffer from substantial performance degradation on sensing gloves due to large appearance gap between bare-hand and glove designs. We therefore propose AirGlove, which leverages existing gloves to generalize the learned glove representations towards new gloves with limited data. Experiments with multiple sensing gloves show that AirGlove effectively generalizes the hand pose models to new glove designs and achieves a significant performance boost over the compared schemes.
Informed Bootstrap Augmentation Improves EEG Decoding
Nov 15, 2025Electroencephalography (EEG) offers detailed access to neural dynamics but remains constrained by noise and trial-by-trial variability, limiting decoding performance in data-restricted or complex paradigms. Data augmentation is often employed to enhance feature representations, yet conventional uniform averaging overlooks differences in trial informativeness and can degrade representational quality. We introduce a weighted bootstrapping approach that prioritizes more reliable trials to generate higher-quality augmented samples. In a Sentence Evaluation paradigm, weights were computed from relative ERP differences and applied during probabilistic sampling and averaging. Across conditions, weighted bootstrapping improved decoding accuracy relative to unweighted (from 68.35% to 71.25% at best), demonstrating that emphasizing reliable trials strengthens representational quality. The results demonstrate that reliability-based augmentation yields more robust and discriminative EEG representations. The code is publicly available at https://github.com/lyricists/NeuroBootstrap.
CPEP: Contrastive Pose-EMG Pre-training Enhances Gesture Generalization on EMG Signals
Sep 04, 2025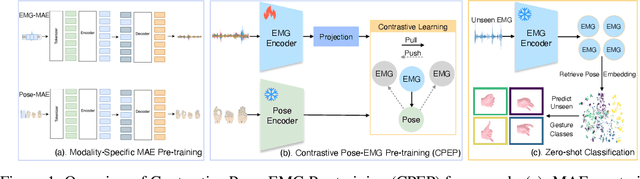

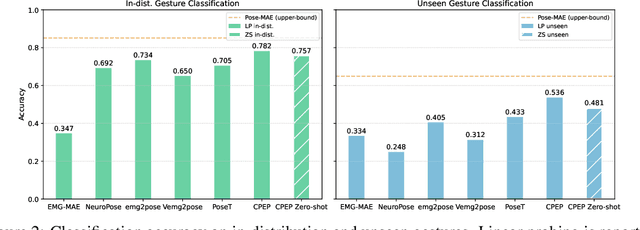
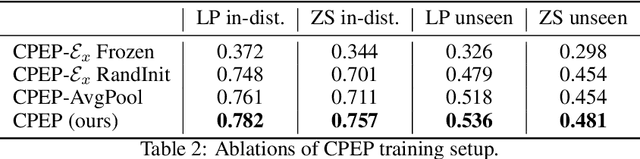
Hand gesture classification using high-quality structured data such as videos, images, and hand skeletons is a well-explored problem in computer vision. Leveraging low-power, cost-effective biosignals, e.g. surface electromyography (sEMG), allows for continuous gesture prediction on wearables. In this paper, we demonstrate that learning representations from weak-modality data that are aligned with those from structured, high-quality data can improve representation quality and enables zero-shot classification. Specifically, we propose a Contrastive Pose-EMG Pre-training (CPEP) framework to align EMG and pose representations, where we learn an EMG encoder that produces high-quality and pose-informative representations. We assess the gesture classification performance of our model through linear probing and zero-shot setups. Our model outperforms emg2pose benchmark models by up to 21% on in-distribution gesture classification and 72% on unseen (out-of-distribution) gesture classification.
Meta Transfer of Self-Supervised Knowledge: Foundation Model in Action for Post-Traumatic Epilepsy Prediction
Dec 21, 2023Despite the impressive advancements achieved using deep-learning for functional brain activity analysis, the heterogeneity of functional patterns and scarcity of imaging data still pose challenges in tasks such as prediction of future onset of Post-Traumatic Epilepsy (PTE) from data acquired shortly after traumatic brain injury (TBI). Foundation models pre-trained on separate large-scale datasets can improve the performance from scarce and heterogeneous datasets. For functional Magnetic Resonance Imaging (fMRI), while data may be abundantly available from healthy controls, clinical data is often scarce, limiting the ability of foundation models to identify clinically-relevant features. We overcome this limitation by introducing a novel training strategy for our foundation model by integrating meta-learning with self-supervised learning to improve the generalization from normal to clinical features. In this way we enable generalization to other downstream clinical tasks, in our case prediction of PTE. To achieve this, we perform self-supervised training on the control dataset to focus on inherent features that are not limited to a particular supervised task while applying meta-learning, which strongly improves the model's generalizability using bi-level optimization. Through experiments on neurological disorder classification tasks, we demonstrate that the proposed strategy significantly improves task performance on small-scale clinical datasets. To explore the generalizability of the foundation model in downstream applications, we then apply the model to an unseen TBI dataset for prediction of PTE using zero-shot learning. Results further demonstrated the enhanced generalizability of our foundation model.
Neuro-GPT: Developing A Foundation Model for EEG
Nov 11, 2023To handle the scarcity and heterogeneity of electroencephalography (EEG) data for Brain-Computer Interface (BCI) tasks, and to harness the power of large publicly available data sets, we propose Neuro-GPT, a foundation model consisting of an EEG encoder and a GPT model. The foundation model is pre-trained on a large-scale data set using a self-supervised task that learns how to reconstruct masked EEG segments. We then fine-tune the model on a Motor Imagery Classification task to validate its performance in a low-data regime (9 subjects). Our experiments demonstrate that applying a foundation model can significantly improve classification performance compared to a model trained from scratch, which provides evidence for the generalizability of the foundation model and its ability to address challenges of data scarcity and heterogeneity in EEG.
SemST: Semantically Consistent Multi-Scale Image Translation via Structure-Texture Alignment
Oct 08, 2023Unsupervised image-to-image (I2I) translation learns cross-domain image mapping that transfers input from the source domain to output in the target domain while preserving its semantics. One challenge is that different semantic statistics in source and target domains result in content discrepancy known as semantic distortion. To address this problem, a novel I2I method that maintains semantic consistency in translation is proposed and named SemST in this work. SemST reduces semantic distortion by employing contrastive learning and aligning the structural and textural properties of input and output by maximizing their mutual information. Furthermore, a multi-scale approach is introduced to enhance translation performance, thereby enabling the applicability of SemST to domain adaptation in high-resolution images. Experiments show that SemST effectively mitigates semantic distortion and achieves state-of-the-art performance. Also, the application of SemST to domain adaptation (DA) is explored. It is demonstrated by preliminary experiments that SemST can be utilized as a beneficial pre-training for the semantic segmentation task.
Toward Improved Generalization: Meta Transfer of Self-supervised Knowledge on Graphs
Dec 16, 2022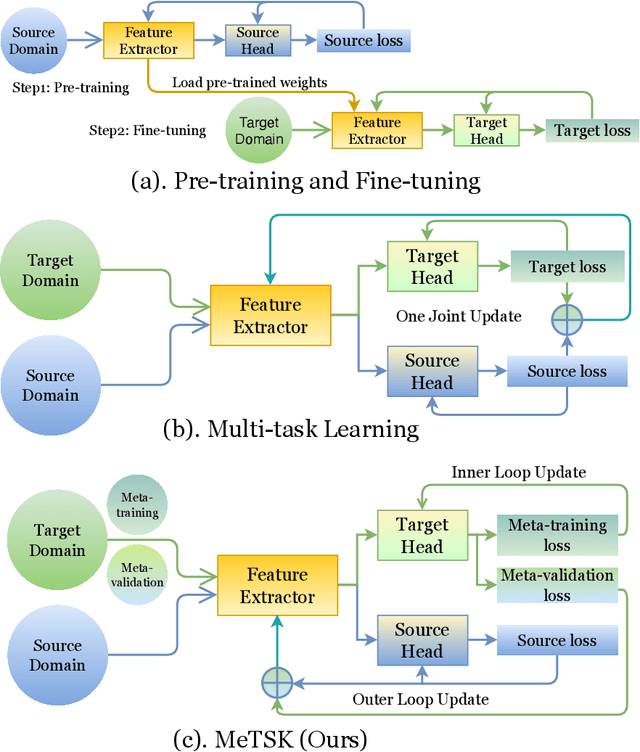

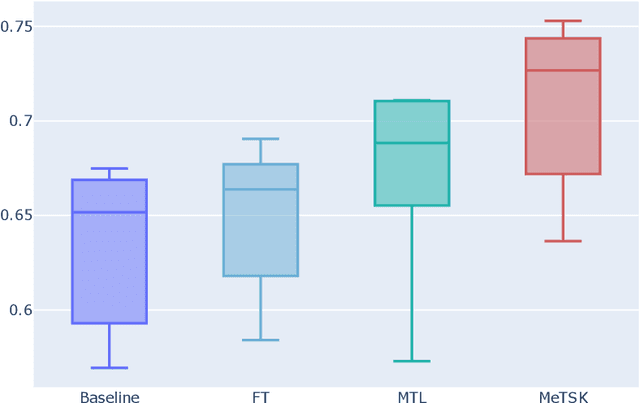

Despite the remarkable success achieved by graph convolutional networks for functional brain activity analysis, the heterogeneity of functional patterns and the scarcity of imaging data still pose challenges in many tasks. Transferring knowledge from a source domain with abundant training data to a target domain is effective for improving representation learning on scarce training data. However, traditional transfer learning methods often fail to generalize the pre-trained knowledge to the target task due to domain discrepancy. Self-supervised learning on graphs can increase the generalizability of graph features since self-supervision concentrates on inherent graph properties that are not limited to a particular supervised task. We propose a novel knowledge transfer strategy by integrating meta-learning with self-supervised learning to deal with the heterogeneity and scarcity of fMRI data. Specifically, we perform a self-supervised task on the source domain and apply meta-learning, which strongly improves the generalizability of the model using the bi-level optimization, to transfer the self-supervised knowledge to the target domain. Through experiments on a neurological disorder classification task, we demonstrate that the proposed strategy significantly improves target task performance by increasing the generalizability and transferability of graph-based knowledge.
Learning from imperfect training data using a robust loss function: application to brain image segmentation
Aug 08, 2022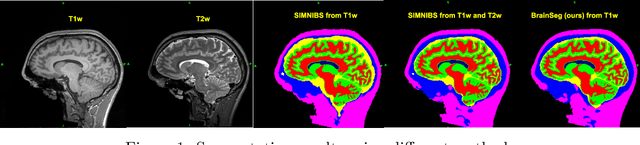

Segmentation is one of the most important tasks in MRI medical image analysis and is often the first and the most critical step in many clinical applications. In brain MRI analysis, head segmentation is commonly used for measuring and visualizing the brain's anatomical structures and is also a necessary step for other applications such as current-source reconstruction in electroencephalography and magnetoencephalography (EEG/MEG). Here we propose a deep learning framework that can segment brain, skull, and extra-cranial tissue using only T1-weighted MRI as input. In addition, we describe a robust method for training the model in the presence of noisy labels.
Semi-supervised Learning using Robust Loss
Mar 03, 2022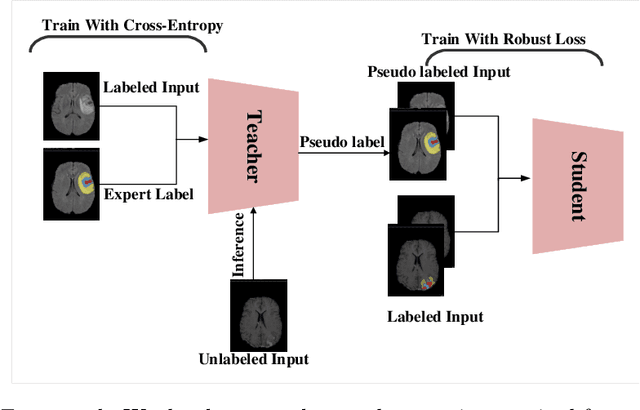

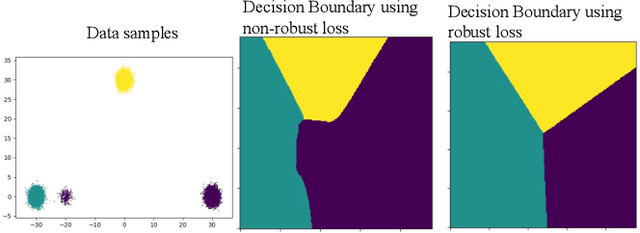

The amount of manually labeled data is limited in medical applications, so semi-supervised learning and automatic labeling strategies can be an asset for training deep neural networks. However, the quality of the automatically generated labels can be uneven and inferior to manual labels. In this paper, we suggest a semi-supervised training strategy for leveraging both manually labeled data and extra unlabeled data. In contrast to the existing approaches, we apply robust loss for the automated labeled data to automatically compensate for the uneven data quality using a teacher-student framework. First, we generate pseudo-labels for unlabeled data using a teacher model pre-trained on labeled data. These pseudo-labels are noisy, and using them along with labeled data for training a deep neural network can severely degrade learned feature representations and the generalization of the network. Here we mitigate the effect of these pseudo-labels by using robust loss functions. Specifically, we use three robust loss functions, namely beta cross-entropy, symmetric cross-entropy, and generalized cross-entropy. We show that our proposed strategy improves the model performance by compensating for the uneven quality of labels in image classification as well as segmentation applications.