 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Autonomous Large Language Model Agent for Chemical Literature Data Mining
Feb 20, 2024



Chemical synthesis, which is crucial for advancing material synthesis and drug discovery, impacts various sectors including environmental science and healthcare. The rise of technology in chemistry has generated extensive chemical data, challenging researchers to discern patterns and refine synthesis processes. Artificial intelligence (AI) helps by analyzing data to optimize synthesis and increase yields. However, AI faces challenges in processing literature data due to the unstructured format and diverse writing style of chemical literature. To overcome these difficulties, we introduce an end-to-end AI agent framework capable of high-fidelity extraction from extensive chemical literature. This AI agent employs large language models (LLMs) for prompt generation and iterative optimization. It functions as a chemistry assistant, automating data collection and analysis, thereby saving manpower and enhancing performance. Our framework's efficacy is evaluated using accuracy, recall, and F1 score of reaction condition data, and we compared our method with human experts in terms of content correctness and time efficiency. The proposed approach marks a significant advancement in automating chemical literature extraction and demonstrates the potential for AI to revolutionize data management and utilization in chemistry.
Semi-Supervised Brain Lesion Segmentation with an Adapted Mean Teacher Model
Mar 04, 2019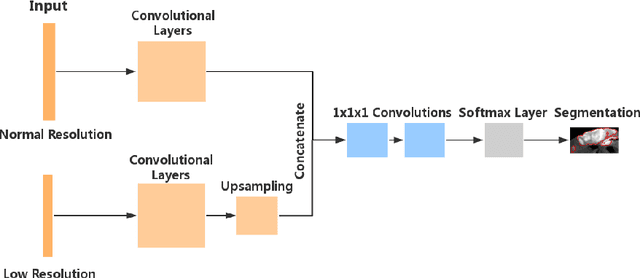
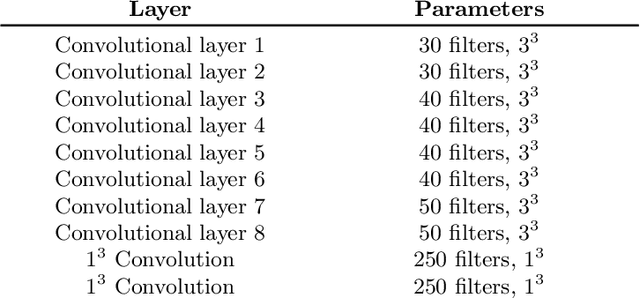
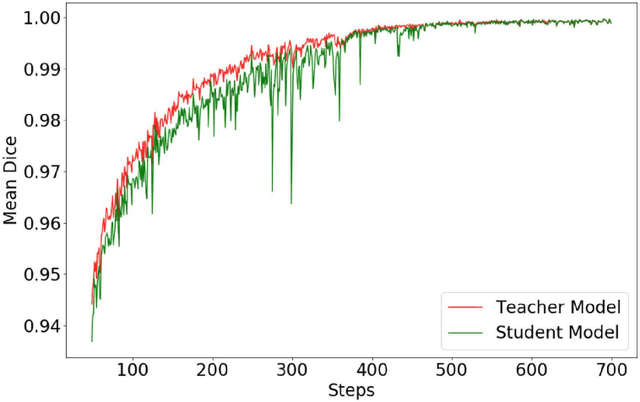

Automated brain lesion segmentation provides valuable information for the analysis and intervention of patients. In particular, methods based on convolutional neural networks (CNNs) have achieved state-of-the-art segmentation performance. However, CNNs usually require a decent amount of annotated data, which may be costly and time-consuming to obtain. Since unannotated data is generally abundant, it is desirable to use unannotated data to improve the segmentation performance for CNNs when limited annotated data is available. In this work, we propose a semi-supervised learning (SSL) approach to brain lesion segmentation, where unannotated data is incorporated into the training of CNNs. We adapt the mean teacher model, which is originally developed for SSL-based image classification, for brain lesion segmentation. Assuming that the network should produce consistent outputs for similar inputs, a loss of segmentation consistency is designed and integrated into a self-ensembling framework. Specifically, we build a student model and a teacher model, which share the same CNN architecture for segmentation. The student and teacher models are updated alternately. At each step, the student model learns from the teacher model by minimizing the weighted sum of the segmentation loss computed from annotated data and the segmentation consistency loss between the teacher and student models computed from unannotated data. Then, the teacher model is updated by combining the updated student model with the historical information of teacher models using an exponential moving average strategy. For demonstration, the proposed approach was evaluated on ischemic stroke lesion segmentation, where it improves stroke lesion segmentation with the incorporation of unannotated data.