 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAerial World Model for Long-horizon Visual Generation and Navigation in 3D Space
Dec 26, 2025Unmanned aerial vehicles (UAVs) have emerged as powerful embodied agents. One of the core abilities is autonomous navigation in large-scale three-dimensional environments. Existing navigation policies, however, are typically optimized for low-level objectives such as obstacle avoidance and trajectory smoothness, lacking the ability to incorporate high-level semantics into planning. To bridge this gap, we propose ANWM, an aerial navigation world model that predicts future visual observations conditioned on past frames and actions, thereby enabling agents to rank candidate trajectories by their semantic plausibility and navigational utility. ANWM is trained on 4-DoF UAV trajectories and introduces a physics-inspired module: Future Frame Projection (FFP), which projects past frames into future viewpoints to provide coarse geometric priors. This module mitigates representational uncertainty in long-distance visual generation and captures the mapping between 3D trajectories and egocentric observations. Empirical results demonstrate that ANWM significantly outperforms existing world models in long-distance visual forecasting and improves UAV navigation success rates in large-scale environments.
The Point, the Vision and the Text: Does Point Cloud Boost Spatial Reasoning of Large Language Models?
Apr 06, 20253D Large Language Models (LLMs) leveraging spatial information in point clouds for 3D spatial reasoning attract great attention. Despite some promising results, the role of point clouds in 3D spatial reasoning remains under-explored. In this work, we comprehensively evaluate and analyze these models to answer the research question: \textit{Does point cloud truly boost the spatial reasoning capacities of 3D LLMs?} We first evaluate the spatial reasoning capacity of LLMs with different input modalities by replacing the point cloud with the visual and text counterparts. We then propose a novel 3D QA (Question-answering) benchmark, ScanReQA, that comprehensively evaluates models' understanding of binary spatial relationships. Our findings reveal several critical insights: 1) LLMs without point input could even achieve competitive performance even in a zero-shot manner; 2) existing 3D LLMs struggle to comprehend the binary spatial relationships; 3) 3D LLMs exhibit limitations in exploiting the structural coordinates in point clouds for fine-grained spatial reasoning. We think these conclusions can help the next step of 3D LLMs and also offer insights for foundation models in other modalities. We release datasets and reproducible codes in the anonymous project page: https://3d-llm.xyz.
AUGlasses: Continuous Action Unit based Facial Reconstruction with Low-power IMUs on Smart Glasses
May 22, 2024Recent advancements in augmented reality (AR) have enabled the use of various sensors on smart glasses for applications like facial reconstruction, which is vital to improve AR experiences for virtual social activities. However, the size and power constraints of smart glasses demand a miniature and low-power sensing solution. AUGlasses achieves unobtrusive low-power facial reconstruction by placing inertial measurement units (IMU) against the temporal area on the face to capture the skin deformations, which are caused by facial muscle movements. These IMU signals, along with historical data on facial action units (AUs), are processed by a transformer-based deep learning model to estimate AU intensities in real-time, which are then used for facial reconstruction. Our results show that AUGlasses accurately predicts the strength (0-5 scale) of 14 key AUs with a cross-user mean absolute error (MAE) of 0.187 (STD = 0.025) and achieves facial reconstruction with a cross-user MAE of 1.93 mm (STD = 0.353). We also integrated various preprocessing and training techniques to ensure robust performance for continuous sensing. Micro-benchmark tests indicate that our system consistently performs accurate continuous facial reconstruction with a fine-tuned cross-user model, achieving an AU MAE of 0.35.
An Autonomous Large Language Model Agent for Chemical Literature Data Mining
Feb 20, 2024



Chemical synthesis, which is crucial for advancing material synthesis and drug discovery, impacts various sectors including environmental science and healthcare. The rise of technology in chemistry has generated extensive chemical data, challenging researchers to discern patterns and refine synthesis processes. Artificial intelligence (AI) helps by analyzing data to optimize synthesis and increase yields. However, AI faces challenges in processing literature data due to the unstructured format and diverse writing style of chemical literature. To overcome these difficulties, we introduce an end-to-end AI agent framework capable of high-fidelity extraction from extensive chemical literature. This AI agent employs large language models (LLMs) for prompt generation and iterative optimization. It functions as a chemistry assistant, automating data collection and analysis, thereby saving manpower and enhancing performance. Our framework's efficacy is evaluated using accuracy, recall, and F1 score of reaction condition data, and we compared our method with human experts in terms of content correctness and time efficiency. The proposed approach marks a significant advancement in automating chemical literature extraction and demonstrates the potential for AI to revolutionize data management and utilization in chemistry.
xTrimoPGLM: Unified 100B-Scale Pre-trained Transformer for Deciphering the Language of Protein
Jan 11, 2024Protein language models have shown remarkable success in learning biological information from protein sequences. However, most existing models are limited by either autoencoding or autoregressive pre-training objectives, which makes them struggle to handle protein understanding and generation tasks concurrently. We propose a unified protein language model, xTrimoPGLM, to address these two types of tasks simultaneously through an innovative pre-training framework. Our key technical contribution is an exploration of the compatibility and the potential for joint optimization of the two types of objectives, which has led to a strategy for training xTrimoPGLM at an unprecedented scale of 100 billion parameters and 1 trillion training tokens. Our extensive experiments reveal that 1) xTrimoPGLM significantly outperforms other advanced baselines in 18 protein understanding benchmarks across four categories. The model also facilitates an atomic-resolution view of protein structures, leading to an advanced 3D structural prediction model that surpasses existing language model-based tools. 2) xTrimoPGLM not only can generate de novo protein sequences following the principles of natural ones, but also can perform programmable generation after supervised fine-tuning (SFT) on curated sequences. These results highlight the substantial capability and versatility of xTrimoPGLM in understanding and generating protein sequences, contributing to the evolving landscape of foundation models in protein science.
xTrimoGene: An Efficient and Scalable Representation Learner for Single-Cell RNA-Seq Data
Nov 26, 2023Advances in high-throughput sequencing technology have led to significant progress in measuring gene expressions at the single-cell level. The amount of publicly available single-cell RNA-seq (scRNA-seq) data is already surpassing 50M records for humans with each record measuring 20,000 genes. This highlights the need for unsupervised representation learning to fully ingest these data, yet classical transformer architectures are prohibitive to train on such data in terms of both computation and memory. To address this challenge, we propose a novel asymmetric encoder-decoder transformer for scRNA-seq data, called xTrimoGene$^\alpha$ (or xTrimoGene for short), which leverages the sparse characteristic of the data to scale up the pre-training. This scalable design of xTrimoGene reduces FLOPs by one to two orders of magnitude compared to classical transformers while maintaining high accuracy, enabling us to train the largest transformer models over the largest scRNA-seq dataset today. Our experiments also show that the performance of xTrimoGene improves as we scale up the model sizes, and it also leads to SOTA performance over various downstream tasks, such as cell type annotation, perturb-seq effect prediction, and drug combination prediction. xTrimoGene model is now available for use as a service via the following link: https://api.biomap.com/xTrimoGene/apply.
GestureGPT: Zero-shot Interactive Gesture Understanding and Grounding with Large Language Model Agents
Oct 30, 2023



Current gesture recognition systems primarily focus on identifying gestures within a predefined set, leaving a gap in connecting these gestures to interactive GUI elements or system functions (e.g., linking a 'thumb-up' gesture to a 'like' button). We introduce GestureGPT, a novel zero-shot gesture understanding and grounding framework leveraging large language models (LLMs). Gesture descriptions are formulated based on hand landmark coordinates from gesture videos and fed into our dual-agent dialogue system. A gesture agent deciphers these descriptions and queries about the interaction context (e.g., interface, history, gaze data), which a context agent organizes and provides. Following iterative exchanges, the gesture agent discerns user intent, grounding it to an interactive function. We validated the gesture description module using public first-view and third-view gesture datasets and tested the whole system in two real-world settings: video streaming and smart home IoT control. The highest zero-shot Top-5 grounding accuracies are 80.11% for video streaming and 90.78% for smart home tasks, showing potential of the new gesture understanding paradigm.
Joint Beamforming for RIS Aided Full-Duplex Integrated Sensing and Uplink Communication
Sep 21, 2023



This paper studies integrated sensing and communication (ISAC) technology in a full-duplex (FD) uplink communication system. As opposed to the half-duplex system, where sensing is conducted in a first-emit-then-listen manner, FD ISAC system emits and listens simultaneously and hence conducts uninterrupted target sensing. Besides, impressed by the recently emerging reconfigurable intelligent surface (RIS) technology, we also employ RIS to improve the self-interference (SI) suppression and signal processing gain. As will be seen, the joint beamforming, RIS configuration and mobile users' power allocation is a difficult optimization problem. To resolve this challenge, via leveraging the cutting-the-edge majorization-minimization (MM) and penalty-dual-decomposition (PDD) methods, we develop an iterative solution that optimizes all variables via using convex optimization techniques. Numerical results demonstrate the effectiveness of our proposed solution and the great benefit of employing RIS in the FD ISAC system.
Bridging the Granularity Gap for Acoustic Modeling
May 27, 2023



While Transformer has become the de-facto standard for speech, modeling upon the fine-grained frame-level features remains an open challenge of capturing long-distance dependencies and distributing the attention weights. We propose \textit{Progressive Down-Sampling} (PDS) which gradually compresses the acoustic features into coarser-grained units containing more complete semantic information, like text-level representation. In addition, we develop a representation fusion method to alleviate information loss that occurs inevitably during high compression. In this way, we compress the acoustic features into 1/32 of the initial length while achieving better or comparable performances on the speech recognition task. And as a bonus, it yields inference speedups ranging from 1.20$\times$ to 1.47$\times$. By reducing the modeling burden, we also achieve competitive results when training on the more challenging speech translation task.
ODE Transformer: An Ordinary Differential Equation-Inspired Model for Sequence Generation
Mar 17, 2022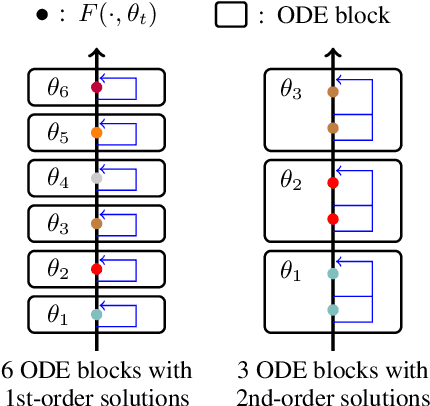
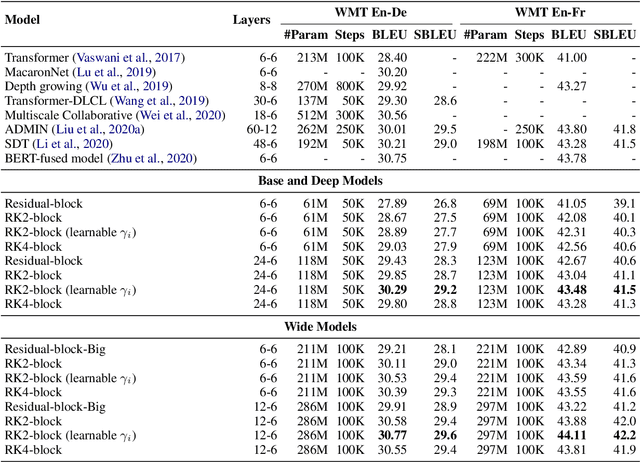
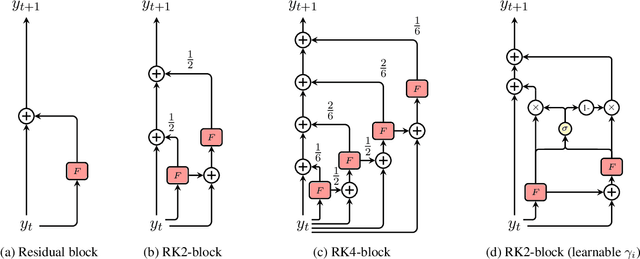
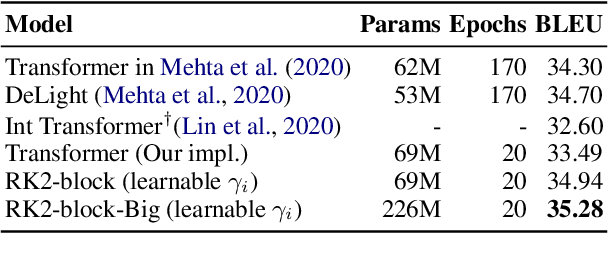
Residual networks are an Euler discretization of solutions to Ordinary Differential Equations (ODE). This paper explores a deeper relationship between Transformer and numerical ODE methods. We first show that a residual block of layers in Transformer can be described as a higher-order solution to ODE. Inspired by this, we design a new architecture, {\it ODE Transformer}, which is analogous to the Runge-Kutta method that is well motivated in ODE. As a natural extension to Transformer, ODE Transformer is easy to implement and efficient to use. Experimental results on the large-scale machine translation, abstractive summarization, and grammar error correction tasks demonstrate the high genericity of ODE Transformer. It can gain large improvements in model performance over strong baselines (e.g., 30.77 and 44.11 BLEU scores on the WMT'14 English-German and English-French benchmarks) at a slight cost in inference efficiency.