 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeacher-Guided Policy Optimization for LLM Distillation
May 13, 2026The convergence of reinforcement learning and imitation learning has positioned Reverse KL (RKL) as a promising paradigm for on-policy LLM distillation, aiming to unify exploration with teacher supervision. However, we identify a critical limitation: when the student and teacher distributions diverge significantly, standard RKL often fails to yield meaningful improvement due to uninformative negative feedback. To address this inefficiency, we propose Teacher-Guided Policy Optimization (TGPO), an on-policy algorithm that incorporates dense directional guidance by leveraging teacher predictions conditioned on the student's rollout. Because TGPO remains on-policy, the algorithm integrates seamlessly with existing RLVR frameworks without requiring additional data annotation. Experiments on complex reasoning benchmarks demonstrate that TGPO significantly outperforms standard baselines and is robust to different teachers.
Offline Exploration-Aware Fine-Tuning for Long-Chain Mathematical Reasoning
Mar 17, 2026Through encouraging self-exploration, reinforcement learning from verifiable rewards (RLVR) has significantly advanced the mathematical reasoning capabilities of large language models. As the starting point for RLVR, the capacity of supervised fine-tuning (SFT) to memorize new chain-of-thought trajectories provides a crucial initialization that shapes the subsequent exploration landscape. However, existing research primarily focuses on facilitating exploration during RLVR training, leaving exploration-aware SFT under-explored. To bridge this gap, we propose Offline eXploration-Aware (OXA) fine-tuning. Specifically, OXA optimizes two objectives: promoting low-confidence verified teacher-distillation data to internalize previously uncaptured reasoning patterns, and suppressing high-confidence incorrect self-distillation data to redistribute probability mass of incorrect patterns toward potentially correct candidates. Experimental results across 6 benchmarks show that OXA consistently improves mathematical reasoning performance, especially achieving an average gain of $+6$ Pass@1 and $+5$ Pass@$k$ points compared to conventional SFT on the Qwen2.5-1.5B-Math. Crucially, OXA elevates initial policy entropy, and performance gains persist throughout extensive RLVR training, demonstrating the long-term value of OXA.
Causal Autoregressive Diffusion Language Model
Jan 29, 2026In this work, we propose Causal Autoregressive Diffusion (CARD), a novel framework that unifies the training efficiency of ARMs with the high-throughput inference of diffusion models. CARD reformulates the diffusion process within a strictly causal attention mask, enabling dense, per-token supervision in a single forward pass. To address the optimization instability of causal diffusion, we introduce a soft-tailed masking schema to preserve local context and a context-aware reweighting mechanism derived from signal-to-noise principles. This design enables dynamic parallel decoding, where the model leverages KV-caching to adaptively generate variable-length token sequences based on confidence. Empirically, CARD outperforms existing discrete diffusion baselines while reducing training latency by 3 $\times$ compared to block diffusion methods. Our results demonstrate that CARD achieves ARM-level data efficiency while unlocking the latency benefits of parallel generation, establishing a robust paradigm for next-generation efficient LLMs.
SageLM: A Multi-aspect and Explainable Large Language Model for Speech Judgement
Aug 28, 2025Speech-to-Speech (S2S) Large Language Models (LLMs) are foundational to natural human-computer interaction, enabling end-to-end spoken dialogue systems. However, evaluating these models remains a fundamental challenge. We propose \texttt{SageLM}, an end-to-end, multi-aspect, and explainable speech LLM for comprehensive S2S LLMs evaluation. First, unlike cascaded approaches that disregard acoustic features, SageLM jointly assesses both semantic and acoustic dimensions. Second, it leverages rationale-based supervision to enhance explainability and guide model learning, achieving superior alignment with evaluation outcomes compared to rule-based reinforcement learning methods. Third, we introduce \textit{SpeechFeedback}, a synthetic preference dataset, and employ a two-stage training paradigm to mitigate the scarcity of speech preference data. Trained on both semantic and acoustic dimensions, SageLM achieves an 82.79\% agreement rate with human evaluators, outperforming cascaded and SLM-based baselines by at least 7.42\% and 26.20\%, respectively.
Deliberate then Generate: Enhanced Prompting Framework for Text Generation
May 31, 2023



Large language models (LLMs) have shown remarkable success across a wide range of natural language generation tasks, where proper prompt designs make great impacts. While existing prompting methods are normally restricted to providing correct information, in this paper, we encourage the model to deliberate by proposing a novel Deliberate then Generate (DTG) prompting framework, which consists of error detection instructions and candidates that may contain errors. DTG is a simple yet effective technique that can be applied to various text generation tasks with minimal modifications. We conduct extensive experiments on 20+ datasets across 7 text generation tasks, including summarization, translation, dialogue, and more. We show that DTG consistently outperforms existing prompting methods and achieves state-of-the-art performance on multiple text generation tasks. We also provide in-depth analyses to reveal the underlying mechanisms of DTG, which may inspire future research on prompting for LLMs.
Bridging the Granularity Gap for Acoustic Modeling
May 27, 2023



While Transformer has become the de-facto standard for speech, modeling upon the fine-grained frame-level features remains an open challenge of capturing long-distance dependencies and distributing the attention weights. We propose \textit{Progressive Down-Sampling} (PDS) which gradually compresses the acoustic features into coarser-grained units containing more complete semantic information, like text-level representation. In addition, we develop a representation fusion method to alleviate information loss that occurs inevitably during high compression. In this way, we compress the acoustic features into 1/32 of the initial length while achieving better or comparable performances on the speech recognition task. And as a bonus, it yields inference speedups ranging from 1.20$\times$ to 1.47$\times$. By reducing the modeling burden, we also achieve competitive results when training on the more challenging speech translation task.
ODE Transformer: An Ordinary Differential Equation-Inspired Model for Sequence Generation
Mar 17, 2022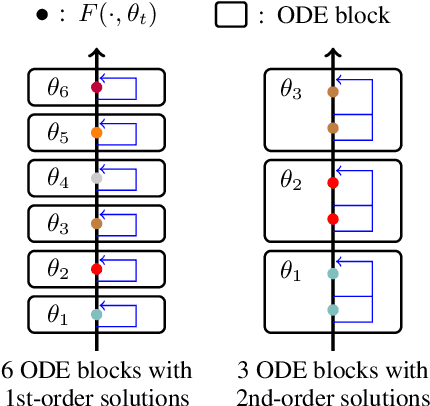
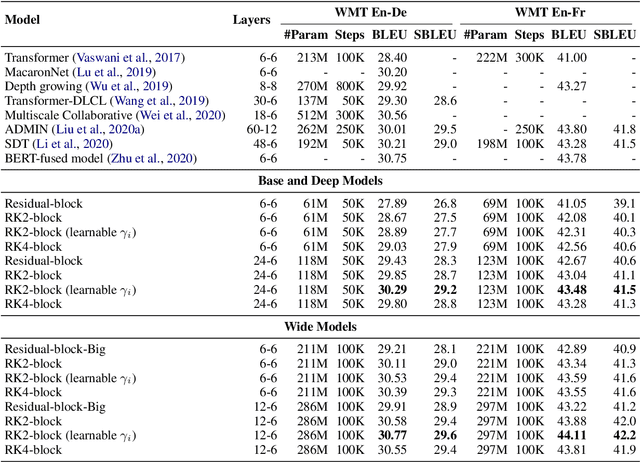
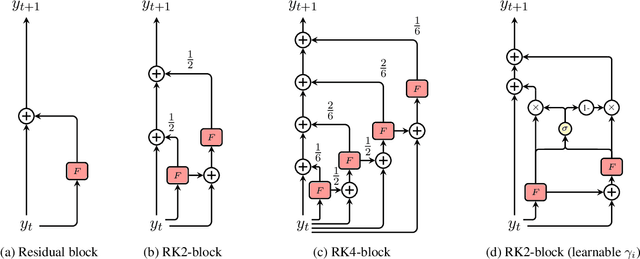
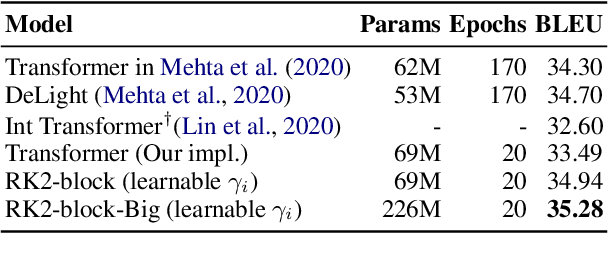
Residual networks are an Euler discretization of solutions to Ordinary Differential Equations (ODE). This paper explores a deeper relationship between Transformer and numerical ODE methods. We first show that a residual block of layers in Transformer can be described as a higher-order solution to ODE. Inspired by this, we design a new architecture, {\it ODE Transformer}, which is analogous to the Runge-Kutta method that is well motivated in ODE. As a natural extension to Transformer, ODE Transformer is easy to implement and efficient to use. Experimental results on the large-scale machine translation, abstractive summarization, and grammar error correction tasks demonstrate the high genericity of ODE Transformer. It can gain large improvements in model performance over strong baselines (e.g., 30.77 and 44.11 BLEU scores on the WMT'14 English-German and English-French benchmarks) at a slight cost in inference efficiency.
On Vision Features in Multimodal Machine Translation
Mar 17, 2022
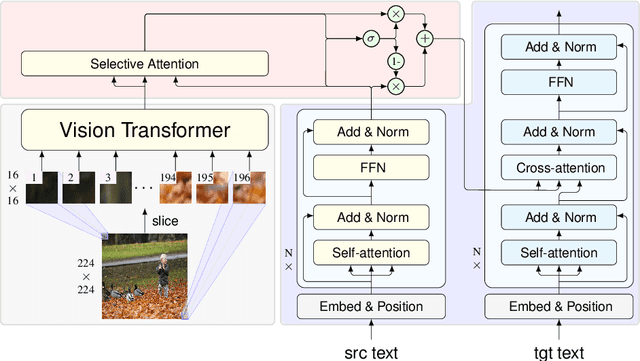
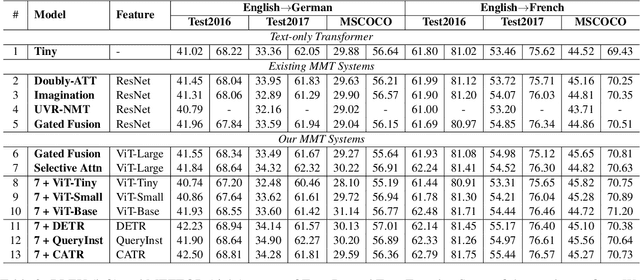
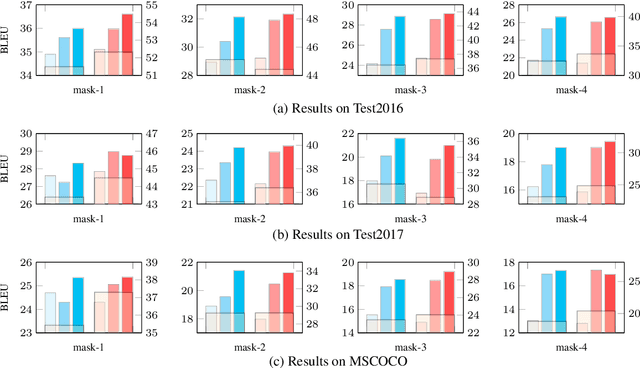
Previous work on multimodal machine translation (MMT) has focused on the way of incorporating vision features into translation but little attention is on the quality of vision models. In this work, we investigate the impact of vision models on MMT. Given the fact that Transformer is becoming popular in computer vision, we experiment with various strong models (such as Vision Transformer) and enhanced features (such as object-detection and image captioning). We develop a selective attention model to study the patch-level contribution of an image in MMT. On detailed probing tasks, we find that stronger vision models are helpful for learning translation from the visual modality. Our results also suggest the need of carefully examining MMT models, especially when current benchmarks are small-scale and biased. Our code could be found at \url{https://github.com/libeineu/fairseq_mmt}.