 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Granularity Gap for Acoustic Modeling
May 27, 2023



While Transformer has become the de-facto standard for speech, modeling upon the fine-grained frame-level features remains an open challenge of capturing long-distance dependencies and distributing the attention weights. We propose \textit{Progressive Down-Sampling} (PDS) which gradually compresses the acoustic features into coarser-grained units containing more complete semantic information, like text-level representation. In addition, we develop a representation fusion method to alleviate information loss that occurs inevitably during high compression. In this way, we compress the acoustic features into 1/32 of the initial length while achieving better or comparable performances on the speech recognition task. And as a bonus, it yields inference speedups ranging from 1.20$\times$ to 1.47$\times$. By reducing the modeling burden, we also achieve competitive results when training on the more challenging speech translation task.
A Simple and Effective Approach to Robust Unsupervised Bilingual Dictionary Induction
Nov 30, 2020
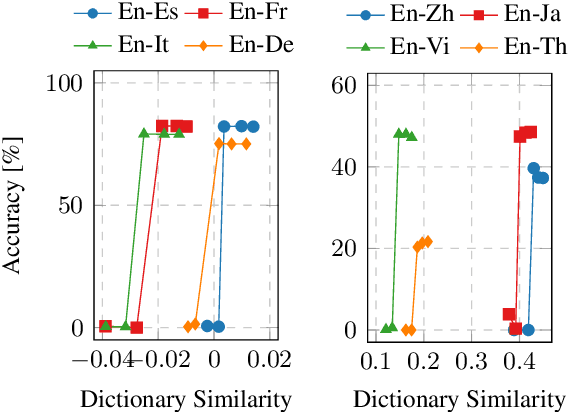
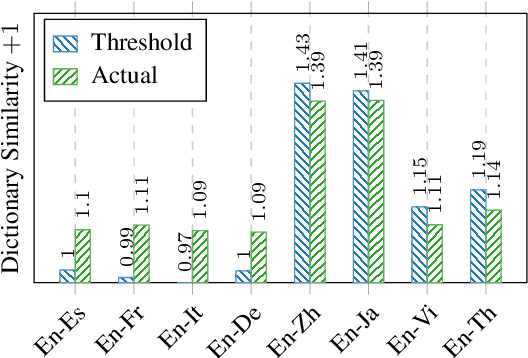

Unsupervised Bilingual Dictionary Induction methods based on the initialization and the self-learning have achieved great success in similar language pairs, e.g., English-Spanish. But they still fail and have an accuracy of 0% in many distant language pairs, e.g., English-Japanese. In this work, we show that this failure results from the gap between the actual initialization performance and the minimum initialization performance for the self-learning to succeed. We propose Iterative Dimension Reduction to bridge this gap. Our experiments show that this simple method does not hamper the performance of similar language pairs and achieves an accuracy of 13.64~55.53% between English and four distant languages, i.e., Chinese, Japanese, Vietnamese and Thai.
Shallow-to-Deep Training for Neural Machine Translation
Oct 08, 2020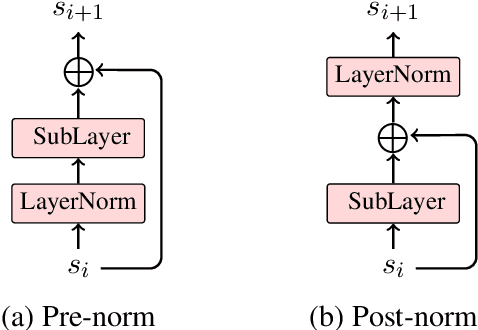
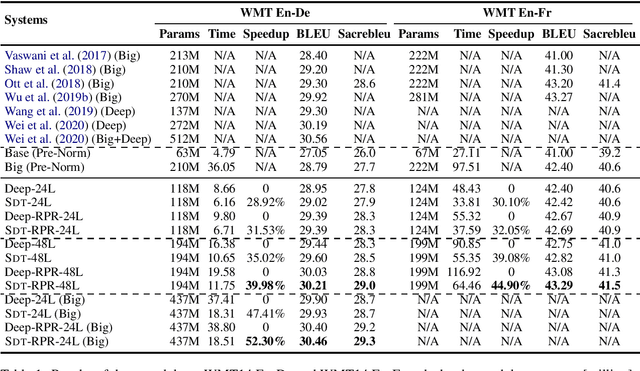


Deep encoders have been proven to be effective in improving neural machine translation (NMT) systems, but training an extremely deep encoder is time consuming. Moreover, why deep models help NMT is an open question. In this paper, we investigate the behavior of a well-tuned deep Transformer system. We find that stacking layers is helpful in improving the representation ability of NMT models and adjacent layers perform similarly. This inspires us to develop a shallow-to-deep training method that learns deep models by stacking shallow models. In this way, we successfully train a Transformer system with a 54-layer encoder. Experimental results on WMT'16 English-German and WMT'14 English-French translation tasks show that it is $1.4$ $\times$ faster than training from scratch, and achieves a BLEU score of $30.33$ and $43.29$ on two tasks. The code is publicly available at https://github.com/libeineu/SDT-Training/.