 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Granularity Gap for Acoustic Modeling
May 27, 2023



While Transformer has become the de-facto standard for speech, modeling upon the fine-grained frame-level features remains an open challenge of capturing long-distance dependencies and distributing the attention weights. We propose \textit{Progressive Down-Sampling} (PDS) which gradually compresses the acoustic features into coarser-grained units containing more complete semantic information, like text-level representation. In addition, we develop a representation fusion method to alleviate information loss that occurs inevitably during high compression. In this way, we compress the acoustic features into 1/32 of the initial length while achieving better or comparable performances on the speech recognition task. And as a bonus, it yields inference speedups ranging from 1.20$\times$ to 1.47$\times$. By reducing the modeling burden, we also achieve competitive results when training on the more challenging speech translation task.
Supporting Medical Relation Extraction via Causality-Pruned Semantic Dependency Forest
Aug 29, 2022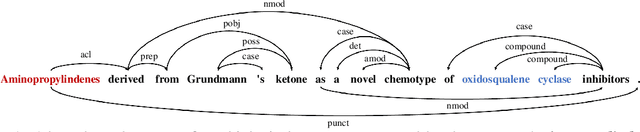

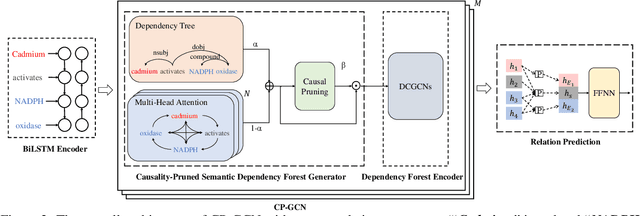
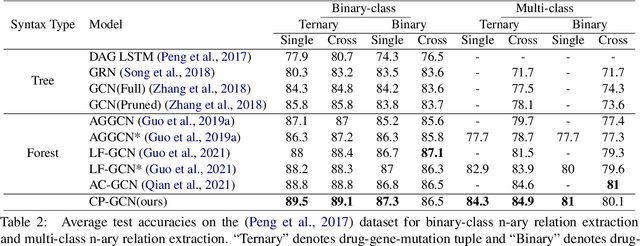
Medical Relation Extraction (MRE) task aims to extract relations between entities in medical texts. Traditional relation extraction methods achieve impressive success by exploring the syntactic information, e.g., dependency tree. However, the quality of the 1-best dependency tree for medical texts produced by an out-of-domain parser is relatively limited so that the performance of medical relation extraction method may degenerate. To this end, we propose a method to jointly model semantic and syntactic information from medical texts based on causal explanation theory. We generate dependency forests consisting of the semantic-embedded 1-best dependency tree. Then, a task-specific causal explainer is adopted to prune the dependency forests, which are further fed into a designed graph convolutional network to learn the corresponding representation for downstream task. Empirically, the various comparisons on benchmark medical datasets demonstrate the effectiveness of our model.
Disentangle and Remerge: Interventional Knowledge Distillation for Few-Shot Object Detection from A Conditional Causal Perspective
Aug 26, 2022
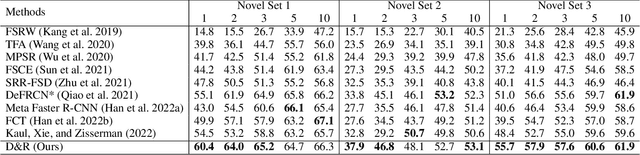
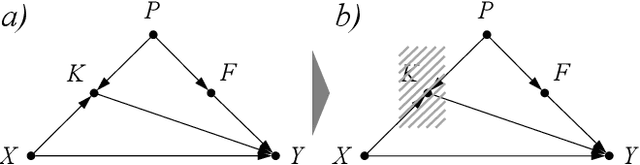
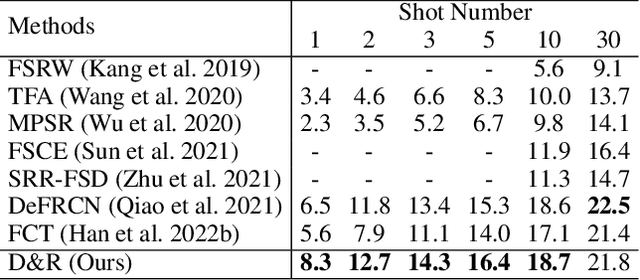
Few-shot learning models learn representations with limited human annotations, and such a learning paradigm demonstrates practicability in various tasks, e.g., image classification, object detection, etc. However, few-shot object detection methods suffer from an intrinsic defect that the limited training data makes the model cannot sufficiently explore semantic information. To tackle this, we introduce knowledge distillation to the few-shot object detection learning paradigm. We further run a motivating experiment, which demonstrates that in the process of knowledge distillation the empirical error of the teacher model degenerates the prediction performance of the few-shot object detection model, as the student. To understand the reasons behind this phenomenon, we revisit the learning paradigm of knowledge distillation on the few-shot object detection task from the causal theoretic standpoint, and accordingly, develop a Structural Causal Model. Following the theoretical guidance, we propose a backdoor adjustment-based knowledge distillation method for the few-shot object detection task, namely Disentangle and Remerge (D&R), to perform conditional causal intervention toward the corresponding Structural Causal Model. Theoretically, we provide an extended definition, i.e., general backdoor path, for the backdoor criterion, which can expand the theoretical application boundary of the backdoor criterion in specific cases. Empirically, the experiments on multiple benchmark datasets demonstrate that D&R can yield significant performance boosts in few-shot object detection.
Learning Multiscale Transformer Models for Sequence Generation
Jun 19, 2022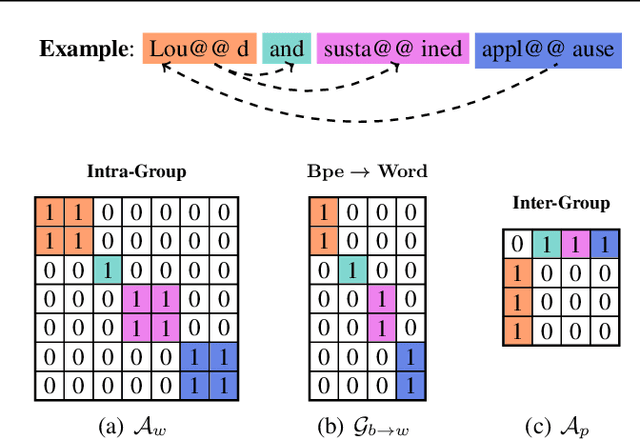

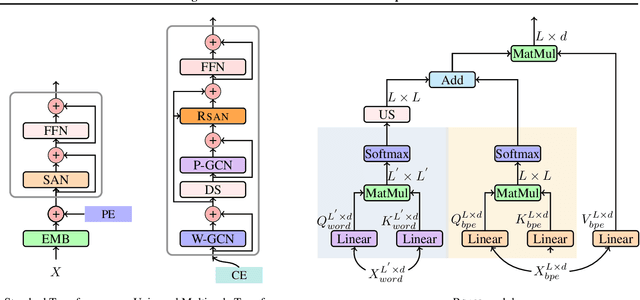
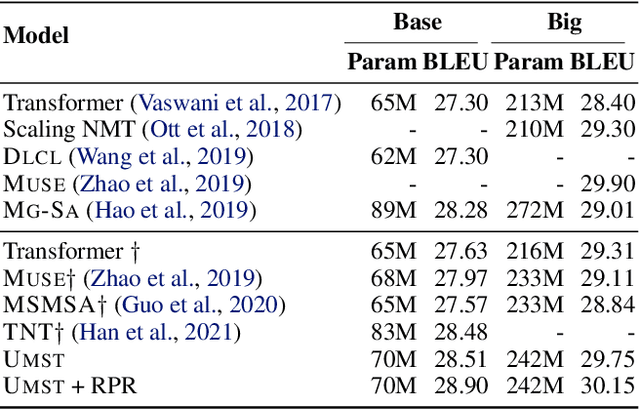
Multiscale feature hierarchies have been witnessed the success in the computer vision area. This further motivates researchers to design multiscale Transformer for natural language processing, mostly based on the self-attention mechanism. For example, restricting the receptive field across heads or extracting local fine-grained features via convolutions. However, most of existing works directly modeled local features but ignored the word-boundary information. This results in redundant and ambiguous attention distributions, which lacks of interpretability. In this work, we define those scales in different linguistic units, including sub-words, words and phrases. We built a multiscale Transformer model by establishing relationships among scales based on word-boundary information and phrase-level prior knowledge. The proposed \textbf{U}niversal \textbf{M}ulti\textbf{S}cale \textbf{T}ransformer, namely \textsc{Umst}, was evaluated on two sequence generation tasks. Notably, it yielded consistent performance gains over the strong baseline on several test sets without sacrificing the efficiency.