 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPR: Penalizing Structural Redundancy in Large Reasoning Models via Anchor-based Process Rewards
Jan 31, 2026Test-Time Scaling (TTS) has significantly enhanced the capabilities of Large Reasoning Models (LRMs) but introduces a critical side-effect known as Overthinking. We conduct a preliminary study to rethink this phenomenon from a fine-grained perspective. We observe that LRMs frequently conduct repetitive self-verification without revision even after obtaining the final answer during the reasoning process. We formally define this specific position where the answer first stabilizes as the Reasoning Anchor. By analyzing pre- and post-anchor reasoning behaviors, we uncover the structural redundancy fixed in LRMs: the meaningless repetitive verification after deriving the first complete answer, which we term the Answer-Stable Tail (AST). Motivated by this observation, we propose Anchor-based Process Reward (APR), a structure-aware reward shaping method that localizes the reasoning anchor and penalizes exclusively the post-anchor AST. Leveraging the policy optimization algorithm suitable for length penalties, our APR models achieved the performance-efficiency Pareto frontier at 1.5B and 7B scales averaged across five mathematical reasoning datasets while requiring significantly fewer computational resources for RL training.
AudioMarathon: A Comprehensive Benchmark for Long-Context Audio Understanding and Efficiency in Audio LLMs
Oct 08, 2025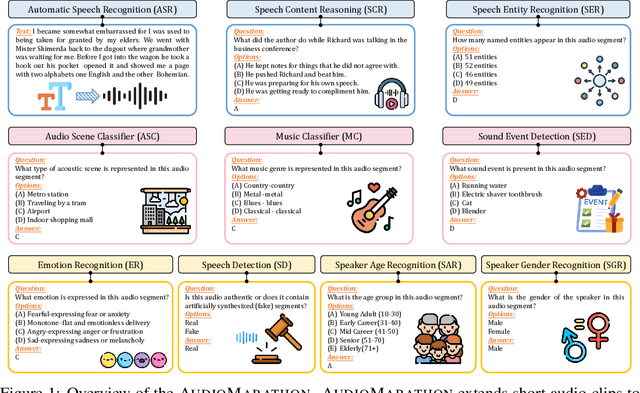
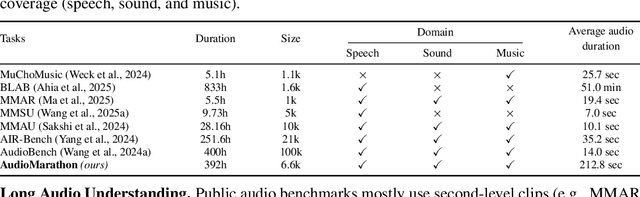
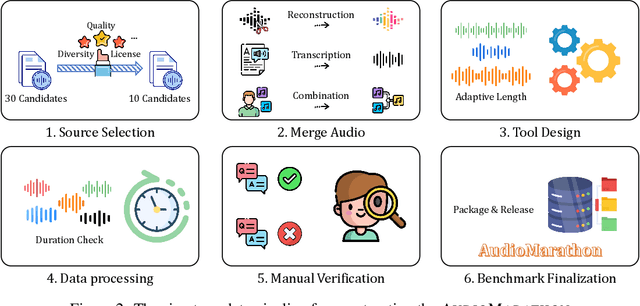

Processing long-form audio is a major challenge for Large Audio Language models (LALMs). These models struggle with the quadratic cost of attention ($O(N^2)$) and with modeling long-range temporal dependencies. Existing audio benchmarks are built mostly from short clips and do not evaluate models in realistic long context settings. To address this gap, we introduce AudioMarathon, a benchmark designed to evaluate both understanding and inference efficiency on long-form audio. AudioMarathon provides a diverse set of tasks built upon three pillars: long-context audio inputs with durations ranging from 90.0 to 300.0 seconds, which correspond to encoded sequences of 2,250 to 7,500 audio tokens, respectively, full domain coverage across speech, sound, and music, and complex reasoning that requires multi-hop inference. We evaluate state-of-the-art LALMs and observe clear performance drops as audio length grows. We also study acceleration techniques and analyze the trade-offs of token pruning and KV cache eviction. The results show large gaps across current LALMs and highlight the need for better temporal reasoning and memory-efficient architectures. We believe AudioMarathon will drive the audio and multimodal research community to develop more advanced audio understanding models capable of solving complex audio tasks.
FLEXI: Benchmarking Full-duplex Human-LLM Speech Interaction
Sep 26, 2025Full-Duplex Speech-to-Speech Large Language Models (LLMs) are foundational to natural human-computer interaction, enabling real-time spoken dialogue systems. However, benchmarking and modeling these models remains a fundamental challenge. We introduce FLEXI, the first benchmark for full-duplex LLM-human spoken interaction that explicitly incorporates model interruption in emergency scenarios. FLEXI systematically evaluates the latency, quality, and conversational effectiveness of real-time dialogue through six diverse human-LLM interaction scenarios, revealing significant gaps between open source and commercial models in emergency awareness, turn terminating, and interaction latency. Finally, we suggest that next token-pair prediction offers a promising path toward achieving truly seamless and human-like full-duplex interaction.
SageLM: A Multi-aspect and Explainable Large Language Model for Speech Judgement
Aug 28, 2025Speech-to-Speech (S2S) Large Language Models (LLMs) are foundational to natural human-computer interaction, enabling end-to-end spoken dialogue systems. However, evaluating these models remains a fundamental challenge. We propose \texttt{SageLM}, an end-to-end, multi-aspect, and explainable speech LLM for comprehensive S2S LLMs evaluation. First, unlike cascaded approaches that disregard acoustic features, SageLM jointly assesses both semantic and acoustic dimensions. Second, it leverages rationale-based supervision to enhance explainability and guide model learning, achieving superior alignment with evaluation outcomes compared to rule-based reinforcement learning methods. Third, we introduce \textit{SpeechFeedback}, a synthetic preference dataset, and employ a two-stage training paradigm to mitigate the scarcity of speech preference data. Trained on both semantic and acoustic dimensions, SageLM achieves an 82.79\% agreement rate with human evaluators, outperforming cascaded and SLM-based baselines by at least 7.42\% and 26.20\%, respectively.
Attention2Probability: Attention-Driven Terminology Probability Estimation for Robust Speech-to-Text System
Aug 26, 2025Recent advances in speech large language models (SLMs) have improved speech recognition and translation in general domains, but accurately generating domain-specific terms or neologisms remains challenging. To address this, we propose Attention2Probability: attention-driven terminology probability estimation for robust speech-to-text system, which is lightweight, flexible, and accurate. Attention2Probability converts cross-attention weights between speech and terminology into presence probabilities, and it further employs curriculum learning to enhance retrieval accuracy. Furthermore, to tackle the lack of data for speech-to-text tasks with terminology intervention, we create and release a new speech dataset with terminology to support future research in this area. Experimental results show that Attention2Probability significantly outperforms the VectorDB method on our test set. Specifically, its maximum recall rates reach 92.57% for Chinese and 86.83% for English. This high recall is achieved with a latency of only 8.71ms per query. Intervening in SLMs' recognition and translation tasks using Attention2Probability-retrieved terms improves terminology accuracy by 6-17%, while revealing that the current utilization of terminology by SLMs has limitations.
TACTIC: Translation Agents with Cognitive-Theoretic Interactive Collaboration
Jun 11, 2025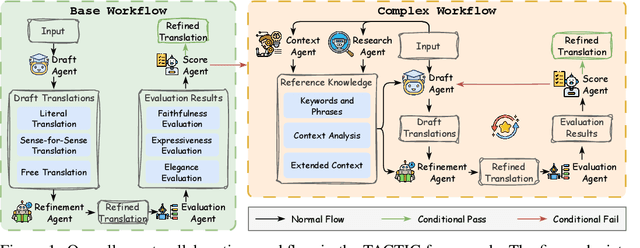
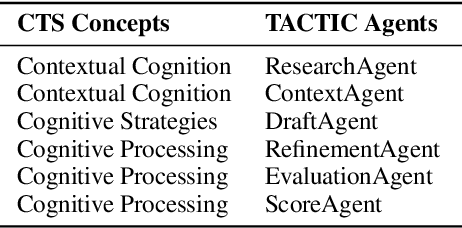
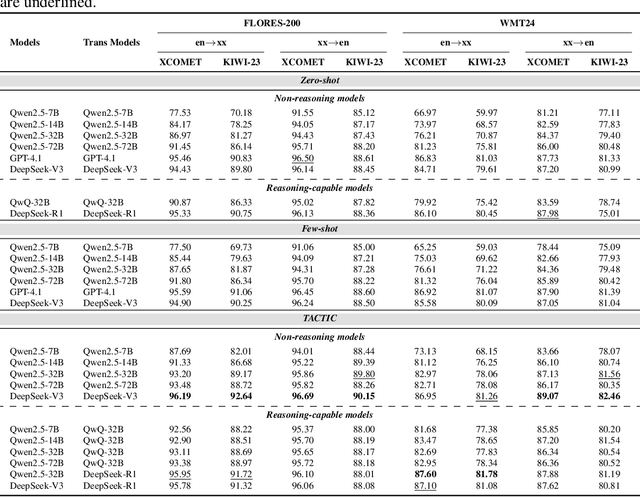

Machine translation has long been a central task in natural language processing. With the rapid advancement of large language models (LLMs), there has been remarkable progress in translation quality. However, fully realizing the translation potential of LLMs remains an open challenge. Recent studies have explored multi-agent systems to decompose complex translation tasks into collaborative subtasks, showing initial promise in enhancing translation quality through agent cooperation and specialization. Nevertheless, existing multi-agent translation frameworks largely neglect foundational insights from cognitive translation studies. These insights emphasize how human translators employ different cognitive strategies, such as balancing literal and free translation, refining expressions based on context, and iteratively evaluating outputs. To address this limitation, we propose a cognitively informed multi-agent framework called TACTIC, which stands for T ranslation A gents with Cognitive- T heoretic Interactive Collaboration. The framework comprises six functionally distinct agents that mirror key cognitive processes observed in human translation behavior. These include agents for drafting, refinement, evaluation, scoring, context reasoning, and external knowledge gathering. By simulating an interactive and theory-grounded translation workflow, TACTIC effectively leverages the full capacity of LLMs for high-quality translation. Experimental results on diverse language pairs from the FLORES-200 and WMT24 benchmarks show that our method consistently achieves state-of-the-art performance. Using DeepSeek-V3 as the base model, TACTIC surpasses GPT-4.1 by an average of +0.6 XCOMET and +1.18 COMETKIWI-23. Compared to DeepSeek-R1, it further improves by +0.84 XCOMET and +2.99 COMETKIWI-23. Code is available at https://github.com/weiyali126/TACTIC.
Beyond Decoder-only: Large Language Models Can be Good Encoders for Machine Translation
Mar 09, 2025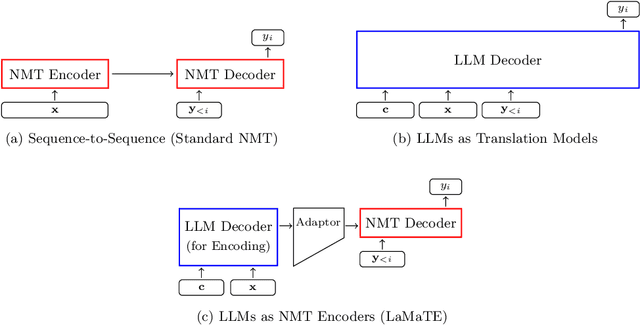
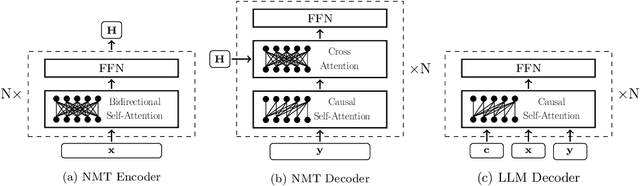
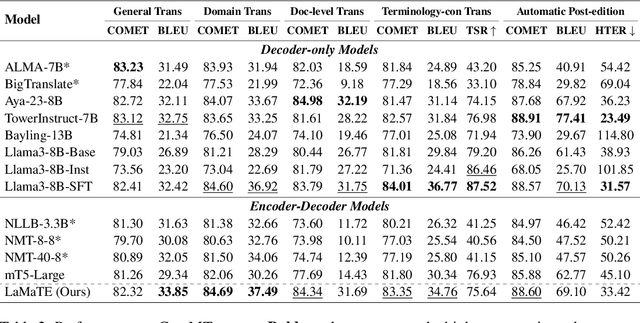
The field of neural machine translation (NMT) has changed with the advent of large language models (LLMs). Much of the recent emphasis in natural language processing (NLP) has been on modeling machine translation and many other problems using a single pre-trained Transformer decoder, while encoder-decoder architectures, which were the standard in earlier NMT models, have received relatively less attention. In this paper, we explore translation models that are universal, efficient, and easy to optimize, by marrying the world of LLMs with the world of NMT. We apply LLMs to NMT encoding and leave the NMT decoder unchanged. We also develop methods for adapting LLMs to work better with the NMT decoder. Furthermore, we construct a new dataset involving multiple tasks to assess how well the machine translation system generalizes across various tasks. Evaluations on the WMT and our datasets show that results using our method match or surpass a range of baselines in terms of translation quality, but achieve $2.4 \sim 6.5 \times$ inference speedups and a $75\%$ reduction in the memory footprint of the KV cache. It also demonstrates strong generalization across a variety of translation-related tasks.
EPO: Explicit Policy Optimization for Strategic Reasoning in LLMs via Reinforcement Learning
Feb 18, 2025
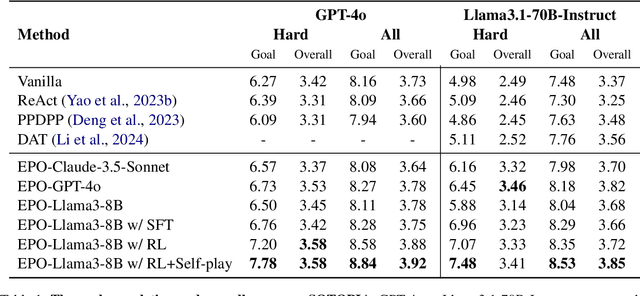
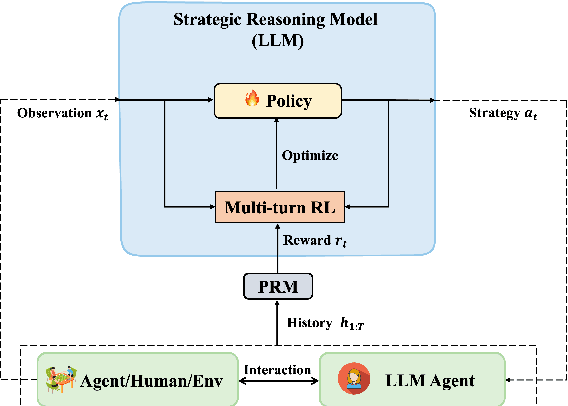
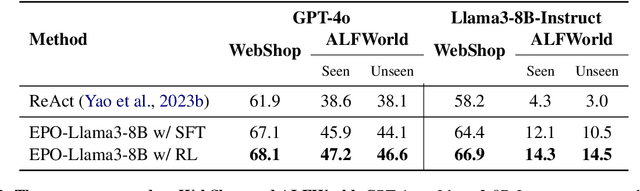
Large Language Models (LLMs) have shown impressive reasoning capabilities in well-defined problems with clear solutions, such as mathematics and coding. However, they still struggle with complex real-world scenarios like business negotiations, which require strategic reasoning-an ability to navigate dynamic environments and align long-term goals amidst uncertainty. Existing methods for strategic reasoning face challenges in adaptability, scalability, and transferring strategies to new contexts. To address these issues, we propose explicit policy optimization (EPO) for strategic reasoning, featuring an LLM that provides strategies in open-ended action space and can be plugged into arbitrary LLM agents to motivate goal-directed behavior. To improve adaptability and policy transferability, we train the strategic reasoning model via multi-turn reinforcement learning (RL) using process rewards and iterative self-play, without supervised fine-tuning (SFT) as a preliminary step. Experiments across social and physical domains demonstrate EPO's ability of long-term goal alignment through enhanced strategic reasoning, achieving state-of-the-art performance on social dialogue and web navigation tasks. Our findings reveal various collaborative reasoning mechanisms emergent in EPO and its effectiveness in generating novel strategies, underscoring its potential for strategic reasoning in real-world applications.
SDPO: Segment-Level Direct Preference Optimization for Social Agents
Jan 03, 2025



Social agents powered by large language models (LLMs) can simulate human social behaviors but fall short in handling complex goal-oriented social dialogues. Direct Preference Optimization (DPO) has proven effective in aligning LLM behavior with human preferences across a variety of agent tasks. Existing DPO-based approaches for multi-turn interactions are divided into turn-level and session-level methods. The turn-level method is overly fine-grained, focusing exclusively on individual turns, while session-level methods are too coarse-grained, often introducing training noise. To address these limitations, we propose Segment-Level Direct Preference Optimization (SDPO), which focuses on specific key segments within interactions to optimize multi-turn agent behavior while minimizing training noise. Evaluations on the SOTOPIA benchmark demonstrate that SDPO-tuned agents consistently outperform both existing DPO-based methods and proprietary LLMs like GPT-4o, underscoring SDPO's potential to advance the social intelligence of LLM-based agents. We release our code and data at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/SDPO.
A Modular-based Strategy for Mitigating Gradient Conflicts in Simultaneous Speech Translation
Sep 24, 2024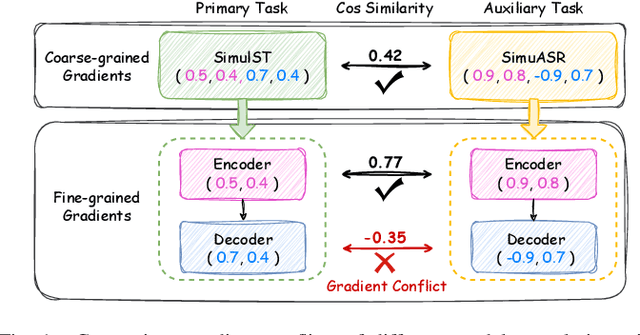
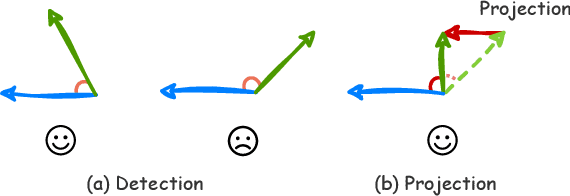
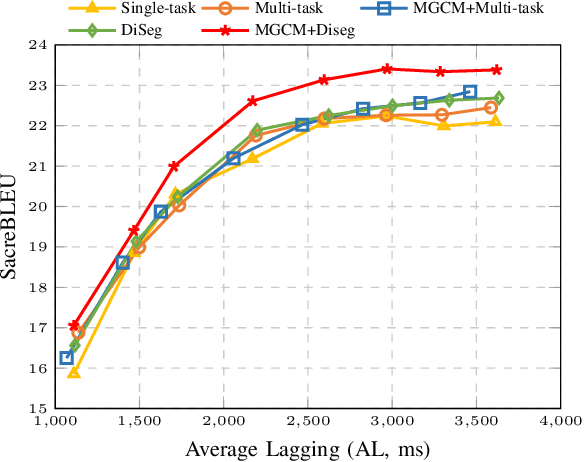
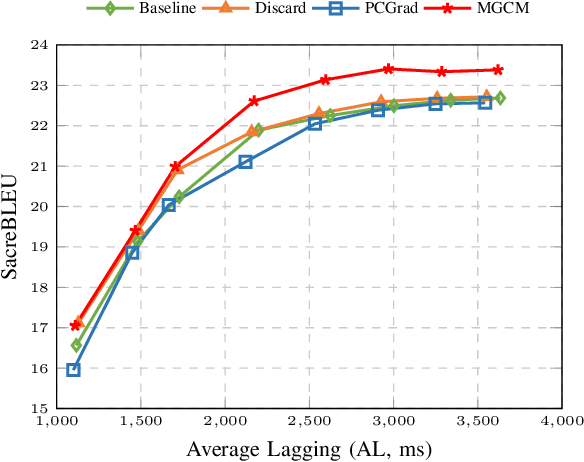
Simultaneous Speech Translation (SimulST) involves generating target language text while continuously processing streaming speech input, presenting significant real-time challenges. Multi-task learning is often employed to enhance SimulST performance but introduces optimization conflicts between primary and auxiliary tasks, potentially compromising overall efficiency. The existing model-level conflict resolution methods are not well-suited for this task which exacerbates inefficiencies and leads to high GPU memory consumption. To address these challenges, we propose a Modular Gradient Conflict Mitigation (MGCM) strategy that detects conflicts at a finer-grained modular level and resolves them utilizing gradient projection. Experimental results demonstrate that MGCM significantly improves SimulST performance, particularly under medium and high latency conditions, achieving a 0.68 BLEU score gain in offline tasks. Additionally, MGCM reduces GPU memory consumption by over 95\% compared to other conflict mitigation methods, establishing it as a robust solution for SimulST tasks.