 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond English: Toward Inclusive and Scalable Multilingual Machine Translation with LLMs
Nov 10, 2025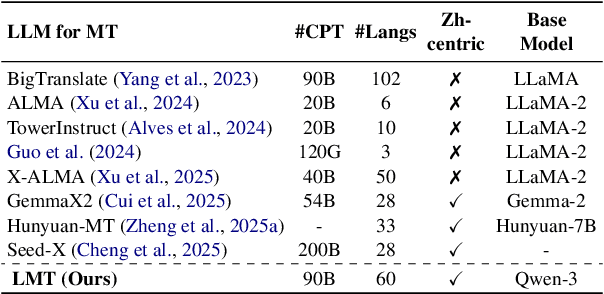
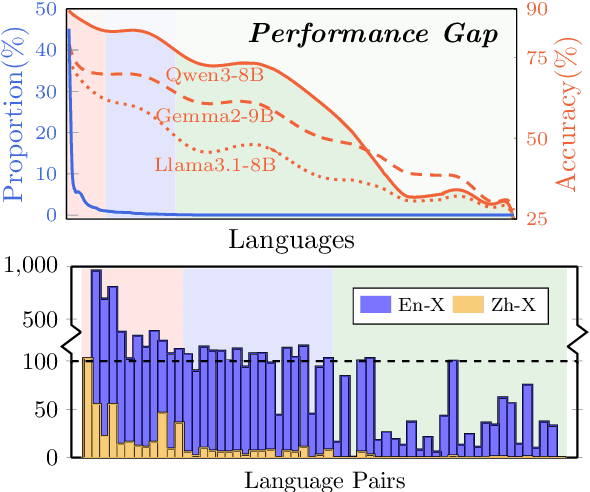
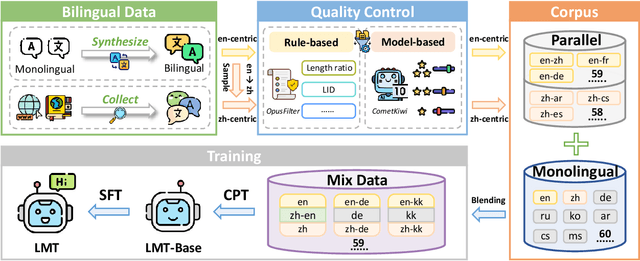
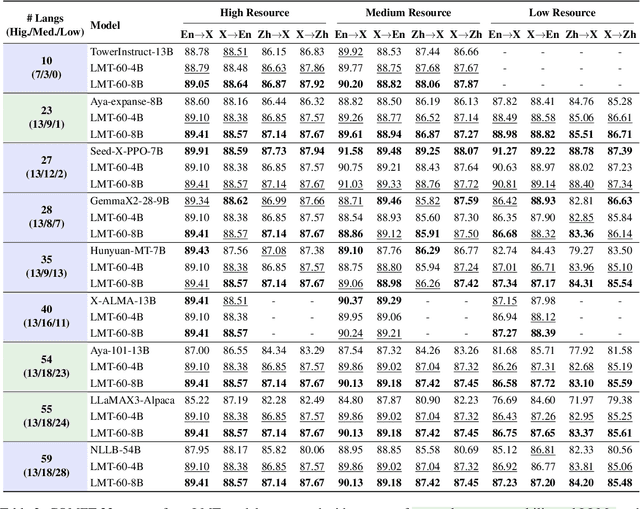
Large language models have significantly advanced Multilingual Machine Translation (MMT), yet the broad language coverage, consistent translation quality, and English-centric bias remain open challenges. To address these challenges, we introduce \textbf{LMT}, a suite of \textbf{L}arge-scale \textbf{M}ultilingual \textbf{T}ranslation models centered on both Chinese and English, covering 60 languages and 234 translation directions. During development, we identify a previously overlooked phenomenon of \textbf{directional degeneration}, where symmetric multi-way fine-tuning data overemphasize reverse directions (X $\to$ En/Zh), leading to excessive many-to-one mappings and degraded translation quality. We propose \textbf{Strategic Downsampling}, a simple yet effective method to mitigate this degeneration. In addition, we design \textbf{Parallel Multilingual Prompting (PMP)}, which leverages typologically related auxiliary languages to enhance cross-lingual transfer. Through rigorous data curation and refined adaptation strategies, LMT achieves SOTA performance among models of comparable language coverage, with our 4B model (LMT-60-4B) surpassing the much larger Aya-101-13B and NLLB-54B models by a substantial margin. We release LMT in four sizes (0.6B/1.7B/4B/8B) to catalyze future research and provide strong baselines for inclusive, scalable, and high-quality MMT \footnote{\href{https://github.com/NiuTrans/LMT}{https://github.com/NiuTrans/LMT}}.
Beyond Decoder-only: Large Language Models Can be Good Encoders for Machine Translation
Mar 09, 2025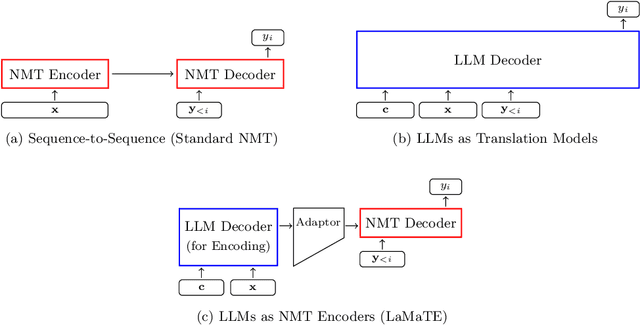
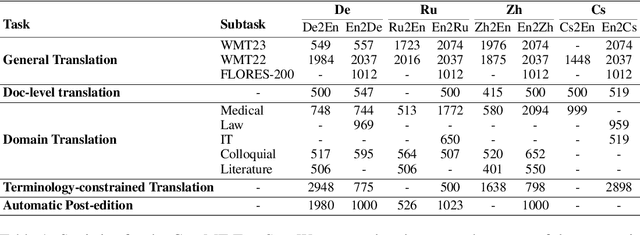
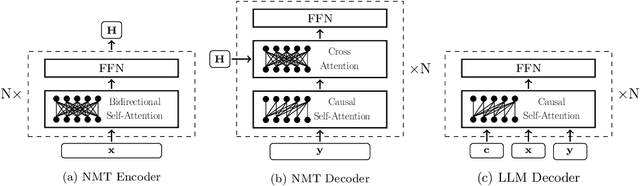
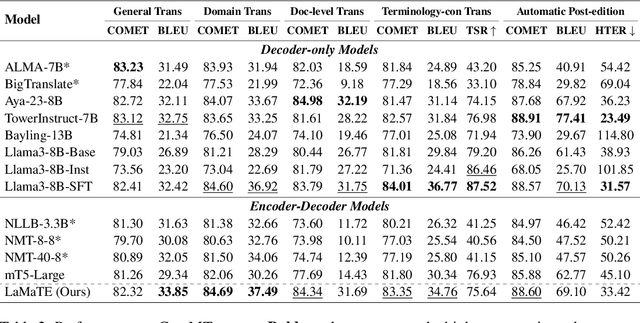
The field of neural machine translation (NMT) has changed with the advent of large language models (LLMs). Much of the recent emphasis in natural language processing (NLP) has been on modeling machine translation and many other problems using a single pre-trained Transformer decoder, while encoder-decoder architectures, which were the standard in earlier NMT models, have received relatively less attention. In this paper, we explore translation models that are universal, efficient, and easy to optimize, by marrying the world of LLMs with the world of NMT. We apply LLMs to NMT encoding and leave the NMT decoder unchanged. We also develop methods for adapting LLMs to work better with the NMT decoder. Furthermore, we construct a new dataset involving multiple tasks to assess how well the machine translation system generalizes across various tasks. Evaluations on the WMT and our datasets show that results using our method match or surpass a range of baselines in terms of translation quality, but achieve $2.4 \sim 6.5 \times$ inference speedups and a $75\%$ reduction in the memory footprint of the KV cache. It also demonstrates strong generalization across a variety of translation-related tasks.
Large Language Models are Parallel Multilingual Learners
Mar 14, 2024In this study, we reveal an in-context learning (ICL) capability of multilingual large language models (LLMs): by translating the input to several languages, we provide Parallel Input in Multiple Languages (PiM) to LLMs, which significantly enhances their comprehension abilities. To test this capability, we design extensive experiments encompassing 8 typical datasets, 7 languages and 8 state-of-the-art multilingual LLMs. Experimental results show that (1) incorporating more languages help PiM surpass the conventional ICL further; (2) even combining with the translations that are inferior to baseline performance can also help. Moreover, by examining the activated neurons in LLMs, we discover a counterintuitive but interesting phenomenon. Contrary to the common thought that PiM would activate more neurons than monolingual input to leverage knowledge learned from diverse languages, PiM actually inhibits neurons and promotes more precise neuron activation especially when more languages are added. This phenomenon aligns with the neuroscience insight about synaptic pruning, which removes less used neural connections, strengthens remainders, and then enhances brain intelligence.