 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPRI: SVD-Partitioned Residual Initialization for Data-Constrained MoE Upcycling
Jun 15, 2026Mixture-of-Experts (MoE) models enable efficient scaling, but training them from scratch remains prohibitively expensive. MoE upcycling mitigates this cost by converting pretrained dense models into sparse MoE models. However, existing upcycling methods typically rely on large-scale continued training and often perform poorly under data-constrained supervised adaptation, due to either homogeneous experts or overly disruptive perturbations to pretrained parameters. In this setting, effective upcycling must leverage pretrained weight structure while introducing sufficient diversity among routed experts. To this end, we propose SVD-Partitioned Residual Initialization (SPRI), which distributes SVD-partitioned residuals derived from pretrained feed-forward network (FFN) weights across routed experts, introducing controlled expert diversity grounded in pretrained spectral structure. We further introduce a two-stage training strategy to improve adaptation stability. We evaluate SPRI on multilingual speech-to-text translation, where limited supervised data challenges MoE upcycling and multiple target languages provide natural routing heterogeneity. On CoVoST2 across 15 En-to-XX directions, SPRI improves average BLEU and COMET over fully fine-tuned dense models by 2.58 and 3.32 points, respectively, and outperforms the prior best MoE upcycling baseline by 3.39 BLEU and 4.34 COMET points.
RouteLMT: Learned Sample Routing for Hybrid LLM Translation Deployment
Apr 24, 2026Large Language Models (LLMs) have achieved remarkable performance in Machine Translation (MT), but deploying them at scale remains prohibitively expensive. A widely adopted remedy is the hybrid system paradigm, which balances cost and quality by serving most requests with a small model and selectively routing a fraction to a large model. However, existing routing strategies often rely on heuristics, external predictors, or absolute quality estimation, which fail to capture whether the large model actually provides a worthwhile improvement over the small one. In this paper, we formulate routing as a budget allocation problem and identify marginal gain, i.e., the large model's improvement over the small model, as the optimal signal for budgeted decisions. Building on this, we propose \textbf{RouteLMT} (routing for LLM-based MT), an efficient in-model router that predicts this expected gain by probing the small translators prompt-token representation, without requiring external models or hypothesis decoding. Extensive experiments demonstrate that our RouteLMT outperforms heuristics, quality/difficulty estimation baselines, achieving a superior quality-budget Pareto frontier. Furthermore, we analyze regression risks and show that a simple guarded variant can mitigate severe quality losses.
APR: Penalizing Structural Redundancy in Large Reasoning Models via Anchor-based Process Rewards
Jan 31, 2026Test-Time Scaling (TTS) has significantly enhanced the capabilities of Large Reasoning Models (LRMs) but introduces a critical side-effect known as Overthinking. We conduct a preliminary study to rethink this phenomenon from a fine-grained perspective. We observe that LRMs frequently conduct repetitive self-verification without revision even after obtaining the final answer during the reasoning process. We formally define this specific position where the answer first stabilizes as the Reasoning Anchor. By analyzing pre- and post-anchor reasoning behaviors, we uncover the structural redundancy fixed in LRMs: the meaningless repetitive verification after deriving the first complete answer, which we term the Answer-Stable Tail (AST). Motivated by this observation, we propose Anchor-based Process Reward (APR), a structure-aware reward shaping method that localizes the reasoning anchor and penalizes exclusively the post-anchor AST. Leveraging the policy optimization algorithm suitable for length penalties, our APR models achieved the performance-efficiency Pareto frontier at 1.5B and 7B scales averaged across five mathematical reasoning datasets while requiring significantly fewer computational resources for RL training.
Beyond English: Toward Inclusive and Scalable Multilingual Machine Translation with LLMs
Nov 10, 2025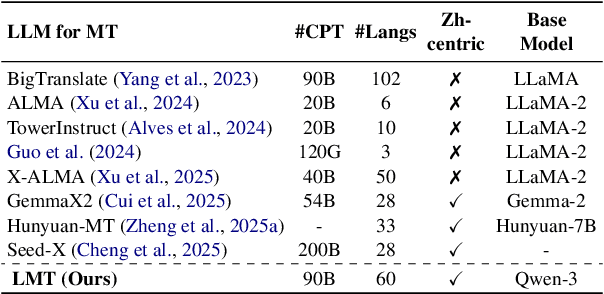
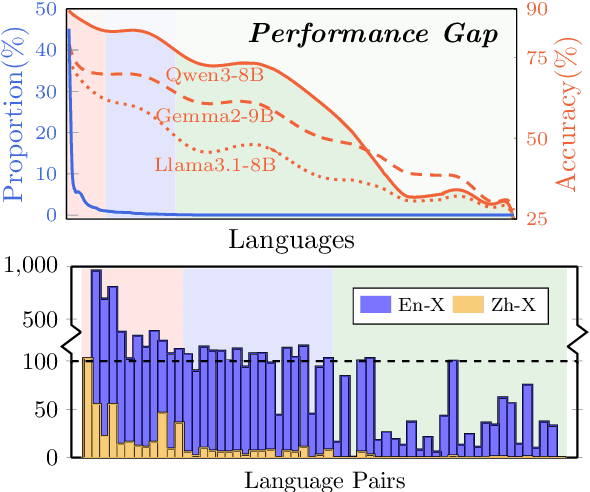
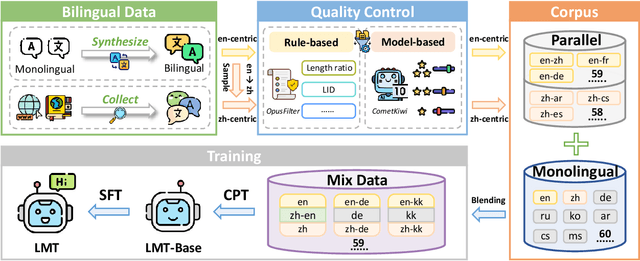
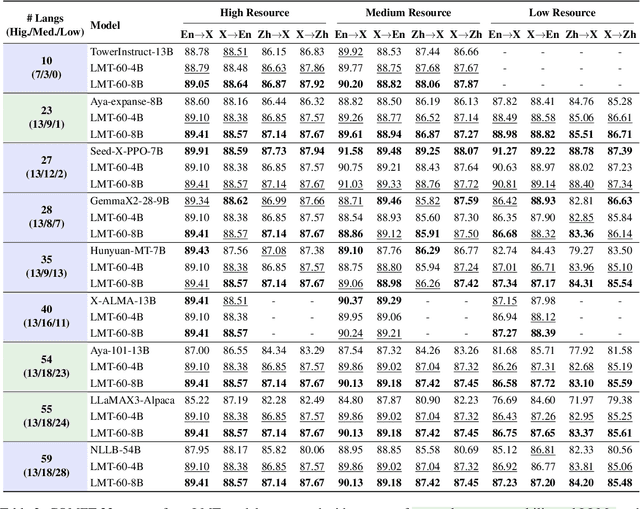
Large language models have significantly advanced Multilingual Machine Translation (MMT), yet the broad language coverage, consistent translation quality, and English-centric bias remain open challenges. To address these challenges, we introduce \textbf{LMT}, a suite of \textbf{L}arge-scale \textbf{M}ultilingual \textbf{T}ranslation models centered on both Chinese and English, covering 60 languages and 234 translation directions. During development, we identify a previously overlooked phenomenon of \textbf{directional degeneration}, where symmetric multi-way fine-tuning data overemphasize reverse directions (X $\to$ En/Zh), leading to excessive many-to-one mappings and degraded translation quality. We propose \textbf{Strategic Downsampling}, a simple yet effective method to mitigate this degeneration. In addition, we design \textbf{Parallel Multilingual Prompting (PMP)}, which leverages typologically related auxiliary languages to enhance cross-lingual transfer. Through rigorous data curation and refined adaptation strategies, LMT achieves SOTA performance among models of comparable language coverage, with our 4B model (LMT-60-4B) surpassing the much larger Aya-101-13B and NLLB-54B models by a substantial margin. We release LMT in four sizes (0.6B/1.7B/4B/8B) to catalyze future research and provide strong baselines for inclusive, scalable, and high-quality MMT \footnote{\href{https://github.com/NiuTrans/LMT}{https://github.com/NiuTrans/LMT}}.
One Size Does Not Fit All: A Distribution-Aware Sparsification for More Precise Model Merging
Aug 08, 2025Model merging has emerged as a compelling data-free paradigm for multi-task learning, enabling the fusion of multiple fine-tuned models into a single, powerful entity. A key technique in merging methods is sparsification, which prunes redundant parameters from task vectors to mitigate interference. However, prevailing approaches employ a ``one-size-fits-all'' strategy, applying a uniform sparsity ratio that overlooks the inherent structural and statistical heterogeneity of model parameters. This often leads to a suboptimal trade-off, where critical parameters are inadvertently pruned while less useful ones are retained. To address this limitation, we introduce \textbf{TADrop} (\textbf{T}ensor-wise \textbf{A}daptive \textbf{Drop}), an adaptive sparsification strategy that respects this heterogeneity. Instead of a global ratio, TADrop assigns a tailored sparsity level to each parameter tensor based on its distributional properties. The core intuition is that tensors with denser, more redundant distributions can be pruned aggressively, while sparser, more critical ones are preserved. As a simple and plug-and-play module, we validate TADrop by integrating it with foundational, classic, and SOTA merging methods. Extensive experiments across diverse tasks (vision, language, and multimodal) and models (ViT, BEiT) demonstrate that TADrop consistently and significantly boosts their performance. For instance, when enhancing a leading merging method, it achieves an average performance gain of 2.0\% across 8 ViT-B/32 tasks. TADrop provides a more effective way to mitigate parameter interference by tailoring sparsification to the model's structure, offering a new baseline for high-performance model merging.
Beyond Decoder-only: Large Language Models Can be Good Encoders for Machine Translation
Mar 09, 2025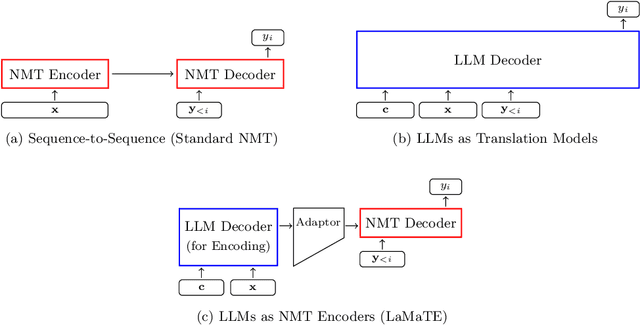
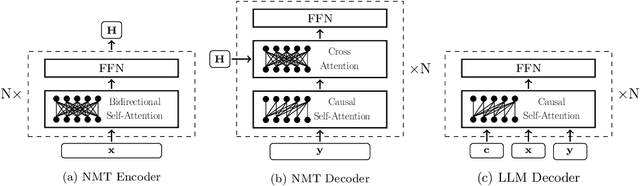
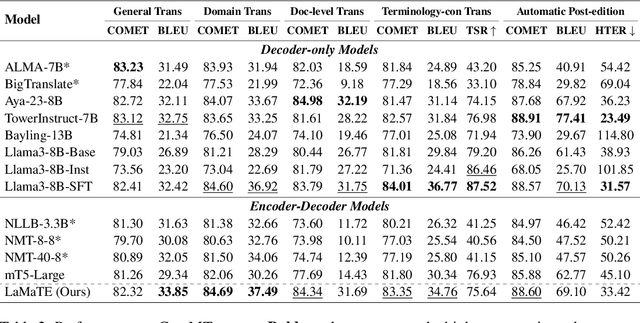
The field of neural machine translation (NMT) has changed with the advent of large language models (LLMs). Much of the recent emphasis in natural language processing (NLP) has been on modeling machine translation and many other problems using a single pre-trained Transformer decoder, while encoder-decoder architectures, which were the standard in earlier NMT models, have received relatively less attention. In this paper, we explore translation models that are universal, efficient, and easy to optimize, by marrying the world of LLMs with the world of NMT. We apply LLMs to NMT encoding and leave the NMT decoder unchanged. We also develop methods for adapting LLMs to work better with the NMT decoder. Furthermore, we construct a new dataset involving multiple tasks to assess how well the machine translation system generalizes across various tasks. Evaluations on the WMT and our datasets show that results using our method match or surpass a range of baselines in terms of translation quality, but achieve $2.4 \sim 6.5 \times$ inference speedups and a $75\%$ reduction in the memory footprint of the KV cache. It also demonstrates strong generalization across a variety of translation-related tasks.
Enhancing Speech Large Language Models with Prompt-Aware Mixture of Audio Encoders
Feb 21, 2025Connecting audio encoders with large language models (LLMs) allows the LLM to perform various audio understanding tasks, such as automatic speech recognition (ASR) and audio captioning (AC). Most research focuses on training an adapter layer to generate a unified audio feature for the LLM. However, different tasks may require distinct features that emphasize either semantic or acoustic aspects, making task-specific audio features more desirable. In this paper, we propose Prompt-aware Mixture (PaM) to enhance the Speech LLM that uses multiple audio encoders. Our approach involves using different experts to extract different features based on the prompt that indicates different tasks. Experiments demonstrate that with PaM, only one Speech LLM surpasses the best performances achieved by all single-encoder Speech LLMs on ASR, Speaker Number Verification, and AC tasks. PaM also outperforms other feature fusion baselines, such as concatenation and averaging.
Boosting Text-To-Image Generation via Multilingual Prompting in Large Multimodal Models
Jan 13, 2025Previous work on augmenting large multimodal models (LMMs) for text-to-image (T2I) generation has focused on enriching the input space of in-context learning (ICL). This includes providing a few demonstrations and optimizing image descriptions to be more detailed and logical. However, as demand for more complex and flexible image descriptions grows, enhancing comprehension of input text within the ICL paradigm remains a critical yet underexplored area. In this work, we extend this line of research by constructing parallel multilingual prompts aimed at harnessing the multilingual capabilities of LMMs. More specifically, we translate the input text into several languages and provide the models with both the original text and the translations. Experiments on two LMMs across 3 benchmarks show that our method, PMT2I, achieves superior performance in general, compositional, and fine-grained assessments, especially in human preference alignment. Additionally, with its advantage of generating more diverse images, PMT2I significantly outperforms baseline prompts when incorporated with reranking methods. Our code and parallel multilingual data can be found at https://github.com/takagi97/PMT2I.
Early Exit Is a Natural Capability in Transformer-based Models: An Empirical Study on Early Exit without Joint Optimization
Dec 02, 2024



Large language models (LLMs) exhibit exceptional performance across various downstream tasks. However, they encounter limitations due to slow inference speeds stemming from their extensive parameters. The early exit (EE) is an approach that aims to accelerate auto-regressive decoding. EE generates outputs from intermediate layers instead of using the whole model, which offers a promising solution to this challenge. However, additional output layers and joint optimization used in conventional EE hinder the application of EE in LLMs. In this paper, we explore the possibility of LLMs EE without additional output layers and joint optimization. Our findings indicate that EE is a natural capability within transformer-based models. While joint optimization does not give model EE capability, it must be employed to address challenges by improving the accuracy of locating the optimal EE layer through gating functions. Additionally, our study reveals patterns in EE behavior from a sub-word perspective based on the LLaMA model and the potential possibility for EE based on sub-layers.
Efficient Prompting Methods for Large Language Models: A Survey
Apr 01, 2024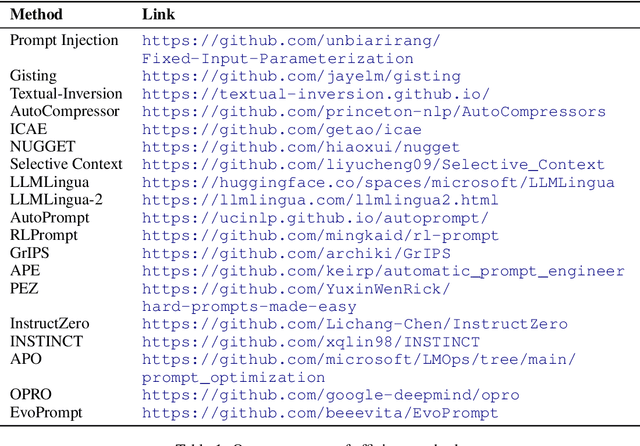
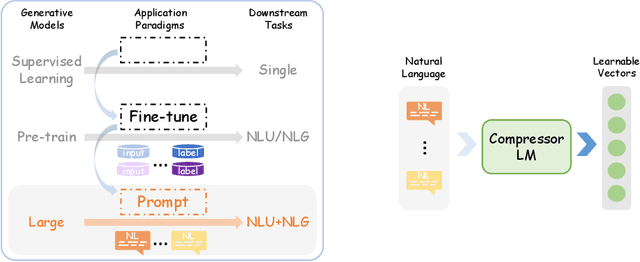

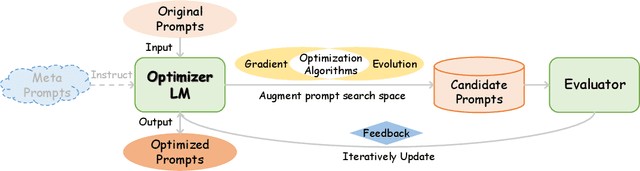
Prompting has become a mainstream paradigm for adapting large language models (LLMs) to specific natural language processing tasks. While this approach opens the door to in-context learning of LLMs, it brings the additional computational burden of model inference and human effort of manual-designed prompts, particularly when using lengthy and complex prompts to guide and control the behavior of LLMs. As a result, the LLM field has seen a remarkable surge in efficient prompting methods. In this paper, we present a comprehensive overview of these methods. At a high level, efficient prompting methods can broadly be categorized into two approaches: prompting with efficient computation and prompting with efficient design. The former involves various ways of compressing prompts, and the latter employs techniques for automatic prompt optimization. We present the basic concepts of prompting, review the advances for efficient prompting, and highlight future research directions.