 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI run as fast as a rabbit, can you? A Multilingual Simile Dialogue Dataset
Jun 09, 2023



A simile is a figure of speech that compares two different things (called the tenor and the vehicle) via shared properties. The tenor and the vehicle are usually connected with comparator words such as "like" or "as". The simile phenomena are unique and complex in a real-life dialogue scene where the tenor and the vehicle can be verbal phrases or sentences, mentioned by different speakers, exist in different sentences, or occur in reversed order. However, the current simile research usually focuses on similes in a triplet tuple (tenor, property, vehicle) or a single sentence where the tenor and vehicle are usually entities or noun phrases, which could not reflect complex simile phenomena in real scenarios. In this paper, we propose a novel and high-quality multilingual simile dialogue (MSD) dataset to facilitate the study of complex simile phenomena. The MSD is the largest manually annotated simile data ($\sim$20K) and it contains both English and Chinese data. Meanwhile, the MSD data can also be used on dialogue tasks to test the ability of dialogue systems when using similes. We design 3 simile tasks (recognition, interpretation, and generation) and 2 dialogue tasks (retrieval and generation) with MSD. For each task, we provide experimental results from strong pre-trained or state-of-the-art models. The experiments demonstrate the challenge of MSD and we have released the data/code on GitHub.
MCTS: A Multi-Reference Chinese Text Simplification Dataset
Jun 05, 2023Text simplification aims to make the text easier to understand by applying rewriting transformations. There has been very little research on Chinese text simplification for a long time. The lack of generic evaluation data is an essential reason for this phenomenon. In this paper, we introduce MCTS, a multi-reference Chinese text simplification dataset. We describe the annotation process of the dataset and provide a detailed analysis of it. Furthermore, we evaluate the performance of some unsupervised methods and advanced large language models. We hope to build a basic understanding of Chinese text simplification through the foundational work and provide references for future research. We release our data at https://github.com/blcuicall/mcts.
Multi-Path Transformer is Better: A Case Study on Neural Machine Translation
May 10, 2023



For years the model performance in machine learning obeyed a power-law relationship with the model size. For the consideration of parameter efficiency, recent studies focus on increasing model depth rather than width to achieve better performance. In this paper, we study how model width affects the Transformer model through a parameter-efficient multi-path structure. To better fuse features extracted from different paths, we add three additional operations to each sublayer: a normalization at the end of each path, a cheap operation to produce more features, and a learnable weighted mechanism to fuse all features flexibly. Extensive experiments on 12 WMT machine translation tasks show that, with the same number of parameters, the shallower multi-path model can achieve similar or even better performance than the deeper model. It reveals that we should pay more attention to the multi-path structure, and there should be a balance between the model depth and width to train a better large-scale Transformer.
ODE Transformer: An Ordinary Differential Equation-Inspired Model for Sequence Generation
Mar 17, 2022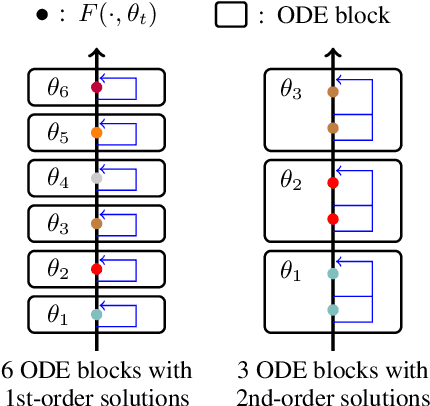
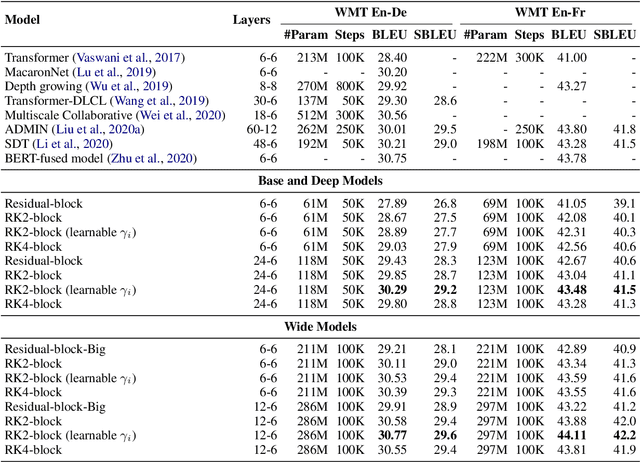
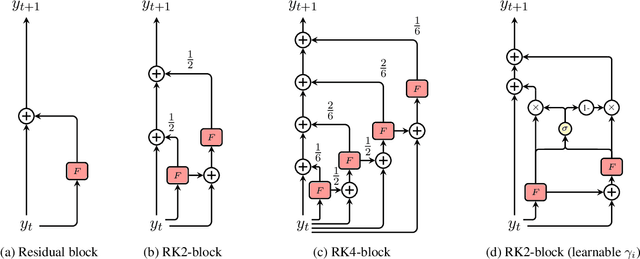
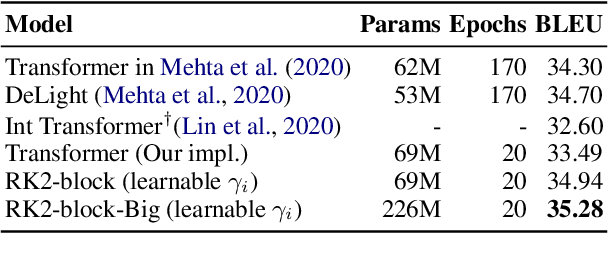
Residual networks are an Euler discretization of solutions to Ordinary Differential Equations (ODE). This paper explores a deeper relationship between Transformer and numerical ODE methods. We first show that a residual block of layers in Transformer can be described as a higher-order solution to ODE. Inspired by this, we design a new architecture, {\it ODE Transformer}, which is analogous to the Runge-Kutta method that is well motivated in ODE. As a natural extension to Transformer, ODE Transformer is easy to implement and efficient to use. Experimental results on the large-scale machine translation, abstractive summarization, and grammar error correction tasks demonstrate the high genericity of ODE Transformer. It can gain large improvements in model performance over strong baselines (e.g., 30.77 and 44.11 BLEU scores on the WMT'14 English-German and English-French benchmarks) at a slight cost in inference efficiency.
The NiuTrans Machine Translation Systems for WMT21
Sep 22, 2021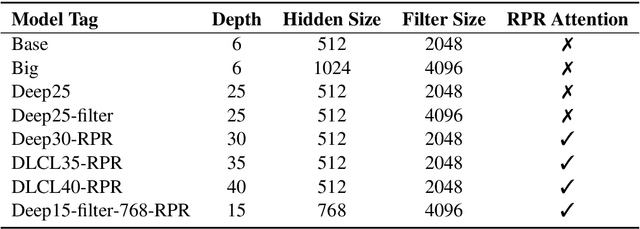
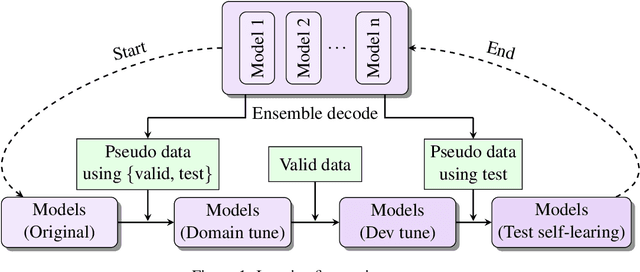
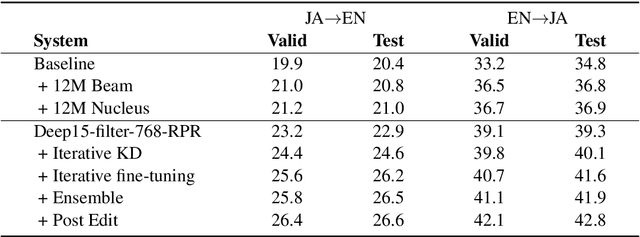
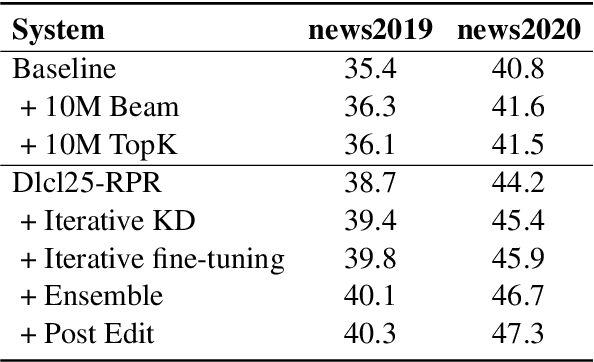
This paper describes NiuTrans neural machine translation systems of the WMT 2021 news translation tasks. We made submissions to 9 language directions, including English$\leftrightarrow$$\{$Chinese, Japanese, Russian, Icelandic$\}$ and English$\rightarrow$Hausa tasks. Our primary systems are built on several effective variants of Transformer, e.g., Transformer-DLCL, ODE-Transformer. We also utilize back-translation, knowledge distillation, post-ensemble, and iterative fine-tuning techniques to enhance the model performance further.
ODE Transformer: An Ordinary Differential Equation-Inspired Model for Neural Machine Translation
Apr 06, 2021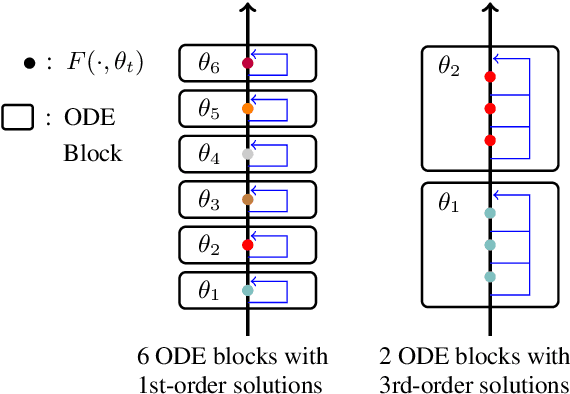
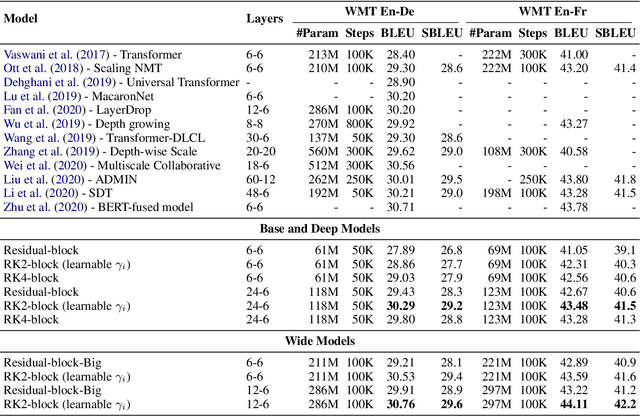
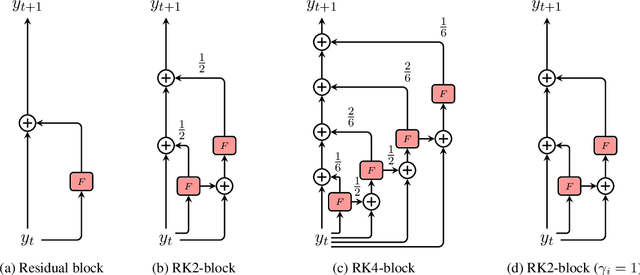
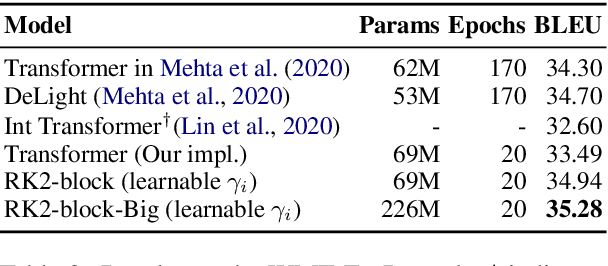
It has been found that residual networks are an Euler discretization of solutions to Ordinary Differential Equations (ODEs). In this paper, we explore a deeper relationship between Transformer and numerical methods of ODEs. We show that a residual block of layers in Transformer can be described as a higher-order solution to ODEs. This leads us to design a new architecture (call it ODE Transformer) analogous to the Runge-Kutta method that is well motivated in ODEs. As a natural extension to Transformer, ODE Transformer is easy to implement and parameter efficient. Our experiments on three WMT tasks demonstrate the genericity of this model, and large improvements in performance over several strong baselines. It achieves 30.76 and 44.11 BLEU scores on the WMT'14 En-De and En-Fr test data. This sets a new state-of-the-art on the WMT'14 En-Fr task.