 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacter, Word, or Both? Revisiting the Segmentation Granularity for Chinese Pre-trained Language Models
Mar 22, 2023Pretrained language models (PLMs) have shown marvelous improvements across various NLP tasks. Most Chinese PLMs simply treat an input text as a sequence of characters, and completely ignore word information. Although Whole Word Masking can alleviate this, the semantics in words is still not well represented. In this paper, we revisit the segmentation granularity of Chinese PLMs. We propose a mixed-granularity Chinese BERT (MigBERT) by considering both characters and words. To achieve this, we design objective functions for learning both character and word-level representations. We conduct extensive experiments on various Chinese NLP tasks to evaluate existing PLMs as well as the proposed MigBERT. Experimental results show that MigBERT achieves new SOTA performance on all these tasks. Further analysis demonstrates that words are semantically richer than characters. More interestingly, we show that MigBERT also works with Japanese. Our code and model have been released here~\footnote{https://github.com/xnliang98/MigBERT}.
On Vision Features in Multimodal Machine Translation
Mar 17, 2022
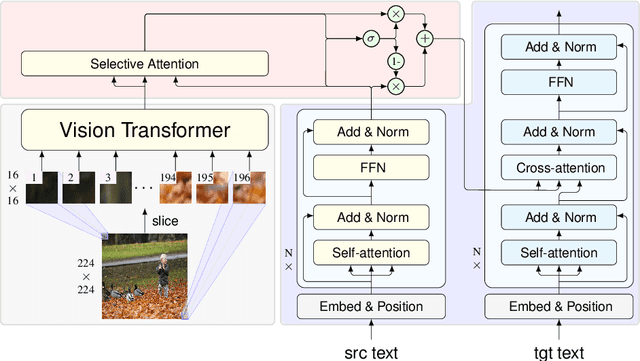
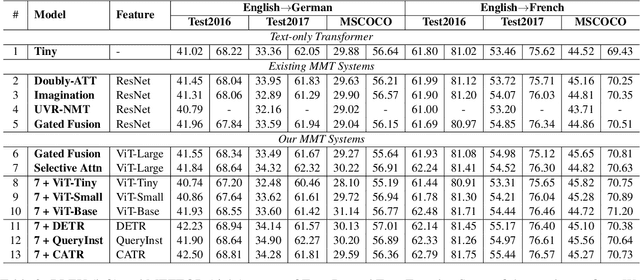
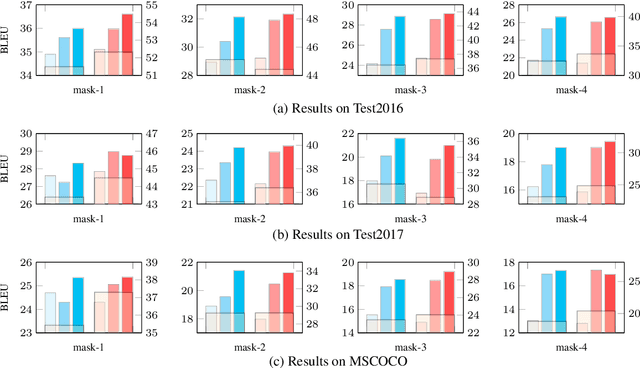
Previous work on multimodal machine translation (MMT) has focused on the way of incorporating vision features into translation but little attention is on the quality of vision models. In this work, we investigate the impact of vision models on MMT. Given the fact that Transformer is becoming popular in computer vision, we experiment with various strong models (such as Vision Transformer) and enhanced features (such as object-detection and image captioning). We develop a selective attention model to study the patch-level contribution of an image in MMT. On detailed probing tasks, we find that stronger vision models are helpful for learning translation from the visual modality. Our results also suggest the need of carefully examining MMT models, especially when current benchmarks are small-scale and biased. Our code could be found at \url{https://github.com/libeineu/fairseq_mmt}.
The NiuTrans Machine Translation Systems for WMT21
Sep 22, 2021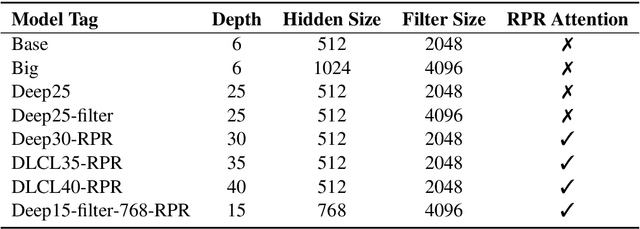
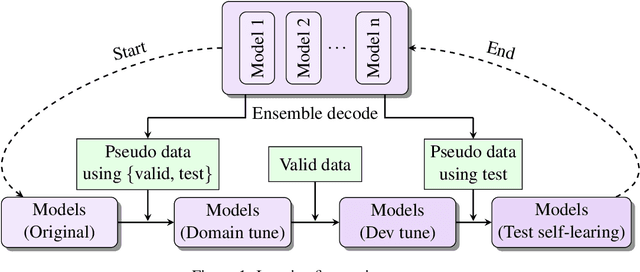
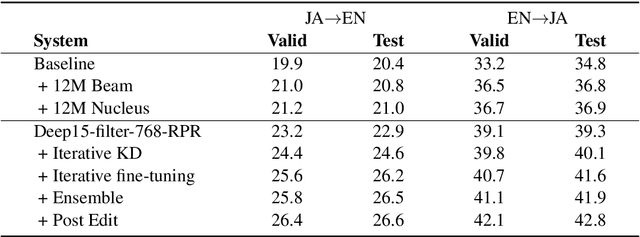
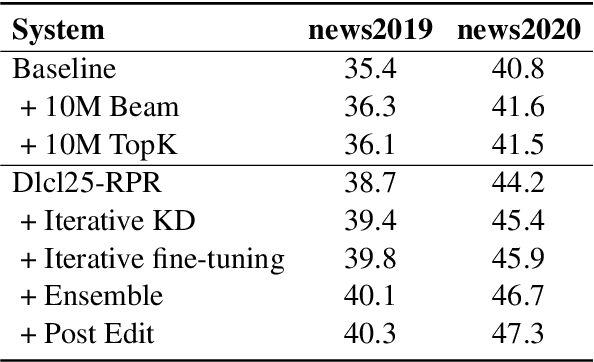
This paper describes NiuTrans neural machine translation systems of the WMT 2021 news translation tasks. We made submissions to 9 language directions, including English$\leftrightarrow$$\{$Chinese, Japanese, Russian, Icelandic$\}$ and English$\rightarrow$Hausa tasks. Our primary systems are built on several effective variants of Transformer, e.g., Transformer-DLCL, ODE-Transformer. We also utilize back-translation, knowledge distillation, post-ensemble, and iterative fine-tuning techniques to enhance the model performance further.