 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Preference Representations: A Multi-Dimensional Evaluation and Analysis Method for Reward Models
Nov 16, 2025Previous methods evaluate reward models by testing them on a fixed pairwise ranking test set, but they typically do not provide performance information on each preference dimension. In this work, we address the evaluation challenge of reward models by probing preference representations. To confirm the effectiveness of this evaluation method, we construct a Multi-dimensional Reward Model Benchmark (MRMBench), a collection of six probing tasks for different preference dimensions. We design it to favor and encourage reward models that better capture preferences across different dimensions. Furthermore, we introduce an analysis method, inference-time probing, which identifies the dimensions used during the reward prediction and enhances its interpretability. Through extensive experiments, we find that MRMBench strongly correlates with the alignment performance of large language models (LLMs), making it a reliable reference for developing advanced reward models. Our analysis of MRMBench evaluation results reveals that reward models often struggle to capture preferences across multiple dimensions, highlighting the potential of multi-objective optimization in reward modeling. Additionally, our findings show that the proposed inference-time probing method offers a reliable metric for assessing the confidence of reward predictions, which ultimately improves the alignment of LLMs.
One Size Does Not Fit All: A Distribution-Aware Sparsification for More Precise Model Merging
Aug 08, 2025Model merging has emerged as a compelling data-free paradigm for multi-task learning, enabling the fusion of multiple fine-tuned models into a single, powerful entity. A key technique in merging methods is sparsification, which prunes redundant parameters from task vectors to mitigate interference. However, prevailing approaches employ a ``one-size-fits-all'' strategy, applying a uniform sparsity ratio that overlooks the inherent structural and statistical heterogeneity of model parameters. This often leads to a suboptimal trade-off, where critical parameters are inadvertently pruned while less useful ones are retained. To address this limitation, we introduce \textbf{TADrop} (\textbf{T}ensor-wise \textbf{A}daptive \textbf{Drop}), an adaptive sparsification strategy that respects this heterogeneity. Instead of a global ratio, TADrop assigns a tailored sparsity level to each parameter tensor based on its distributional properties. The core intuition is that tensors with denser, more redundant distributions can be pruned aggressively, while sparser, more critical ones are preserved. As a simple and plug-and-play module, we validate TADrop by integrating it with foundational, classic, and SOTA merging methods. Extensive experiments across diverse tasks (vision, language, and multimodal) and models (ViT, BEiT) demonstrate that TADrop consistently and significantly boosts their performance. For instance, when enhancing a leading merging method, it achieves an average performance gain of 2.0\% across 8 ViT-B/32 tasks. TADrop provides a more effective way to mitigate parameter interference by tailoring sparsification to the model's structure, offering a new baseline for high-performance model merging.
CTC-based Non-autoregressive Speech Translation
May 27, 2023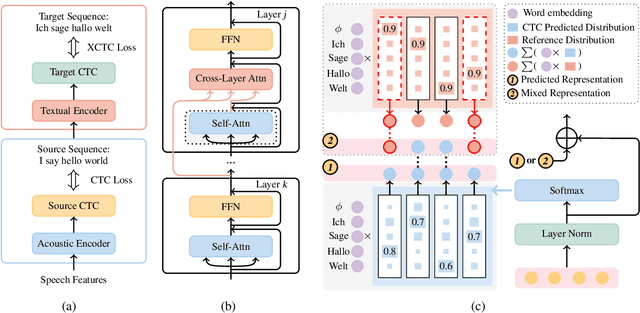
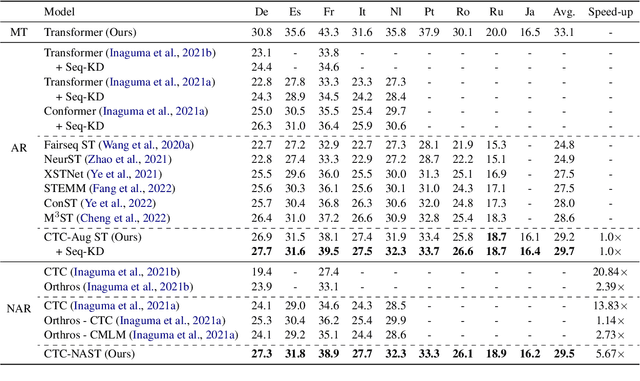
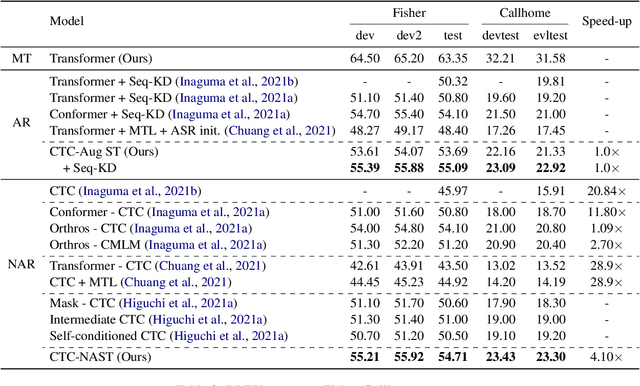
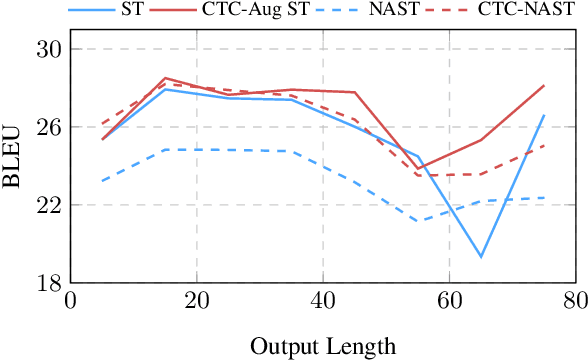
Combining end-to-end speech translation (ST) and non-autoregressive (NAR) generation is promising in language and speech processing for their advantages of less error propagation and low latency. In this paper, we investigate the potential of connectionist temporal classification (CTC) for non-autoregressive speech translation (NAST). In particular, we develop a model consisting of two encoders that are guided by CTC to predict the source and target texts, respectively. Introducing CTC into NAST on both language sides has obvious challenges: 1) the conditional independent generation somewhat breaks the interdependency among tokens, and 2) the monotonic alignment assumption in standard CTC does not hold in translation tasks. In response, we develop a prediction-aware encoding approach and a cross-layer attention approach to address these issues. We also use curriculum learning to improve convergence of training. Experiments on the MuST-C ST benchmarks show that our NAST model achieves an average BLEU score of 29.5 with a speed-up of 5.67$\times$, which is comparable to the autoregressive counterpart and even outperforms the previous best result of 0.9 BLEU points.
Bridging the Granularity Gap for Acoustic Modeling
May 27, 2023



While Transformer has become the de-facto standard for speech, modeling upon the fine-grained frame-level features remains an open challenge of capturing long-distance dependencies and distributing the attention weights. We propose \textit{Progressive Down-Sampling} (PDS) which gradually compresses the acoustic features into coarser-grained units containing more complete semantic information, like text-level representation. In addition, we develop a representation fusion method to alleviate information loss that occurs inevitably during high compression. In this way, we compress the acoustic features into 1/32 of the initial length while achieving better or comparable performances on the speech recognition task. And as a bonus, it yields inference speedups ranging from 1.20$\times$ to 1.47$\times$. By reducing the modeling burden, we also achieve competitive results when training on the more challenging speech translation task.
Multi-Path Transformer is Better: A Case Study on Neural Machine Translation
May 10, 2023



For years the model performance in machine learning obeyed a power-law relationship with the model size. For the consideration of parameter efficiency, recent studies focus on increasing model depth rather than width to achieve better performance. In this paper, we study how model width affects the Transformer model through a parameter-efficient multi-path structure. To better fuse features extracted from different paths, we add three additional operations to each sublayer: a normalization at the end of each path, a cheap operation to produce more features, and a learnable weighted mechanism to fuse all features flexibly. Extensive experiments on 12 WMT machine translation tasks show that, with the same number of parameters, the shallower multi-path model can achieve similar or even better performance than the deeper model. It reveals that we should pay more attention to the multi-path structure, and there should be a balance between the model depth and width to train a better large-scale Transformer.
On Vision Features in Multimodal Machine Translation
Mar 17, 2022
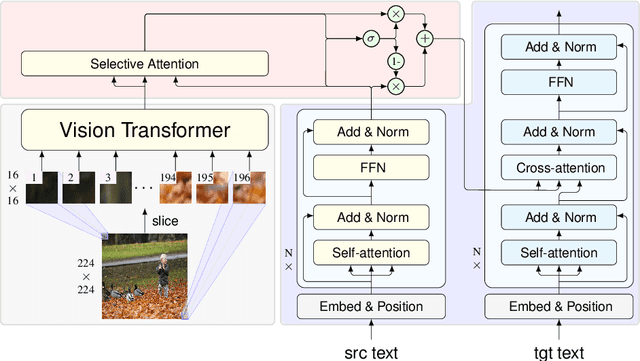
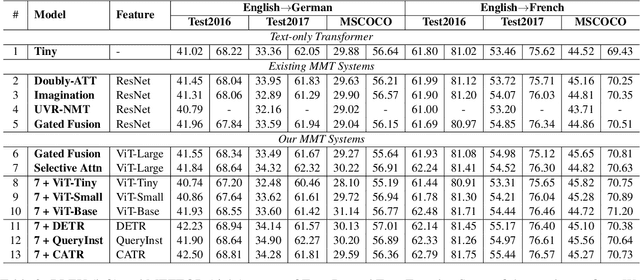
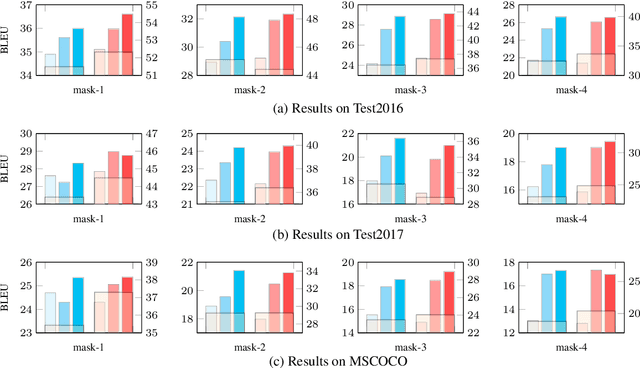
Previous work on multimodal machine translation (MMT) has focused on the way of incorporating vision features into translation but little attention is on the quality of vision models. In this work, we investigate the impact of vision models on MMT. Given the fact that Transformer is becoming popular in computer vision, we experiment with various strong models (such as Vision Transformer) and enhanced features (such as object-detection and image captioning). We develop a selective attention model to study the patch-level contribution of an image in MMT. On detailed probing tasks, we find that stronger vision models are helpful for learning translation from the visual modality. Our results also suggest the need of carefully examining MMT models, especially when current benchmarks are small-scale and biased. Our code could be found at \url{https://github.com/libeineu/fairseq_mmt}.