 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJEPA-VLA: Video Predictive Embedding is Needed for VLA Models
Feb 12, 2026Recent vision-language-action (VLA) models built upon pretrained vision-language models (VLMs) have achieved significant improvements in robotic manipulation. However, current VLAs still suffer from low sample efficiency and limited generalization. This paper argues that these limitations are closely tied to an overlooked component, pretrained visual representation, which offers insufficient knowledge on both aspects of environment understanding and policy prior. Through an in-depth analysis, we find that commonly used visual representations in VLAs, whether pretrained via language-image contrastive learning or image-based self-supervised learning, remain inadequate at capturing crucial, task-relevant environment information and at inducing effective policy priors, i.e., anticipatory knowledge of how the environment evolves under successful task execution. In contrast, we discover that predictive embeddings pretrained on videos, in particular V-JEPA 2, are adept at flexibly discarding unpredictable environment factors and encoding task-relevant temporal dynamics, thereby effectively compensating for key shortcomings of existing visual representations in VLAs. Building on these observations, we introduce JEPA-VLA, a simple yet effective approach that adaptively integrates predictive embeddings into existing VLAs. Our experiments demonstrate that JEPA-VLA yields substantial performance gains across a range of benchmarks, including LIBERO, LIBERO-plus, RoboTwin2.0, and real-robot tasks.
A Scheduling Framework for Efficient MoE Inference on Edge GPU-NDP Systems
Jan 07, 2026Mixture-of-Experts (MoE) models facilitate edge deployment by decoupling model capacity from active computation, yet their large memory footprint drives the need for GPU systems with near-data processing (NDP) capabilities that offload experts to dedicated processing units. However, deploying MoE models on such edge-based GPU-NDP systems faces three critical challenges: 1) severe load imbalance across NDP units due to non-uniform expert selection and expert parallelism, 2) insufficient GPU utilization during expert computation within NDP units, and 3) extensive data pre-profiling necessitated by unpredictable expert activation patterns for pre-fetching. To address these challenges, this paper proposes an efficient inference framework featuring three key optimizations. First, the underexplored tensor parallelism in MoE inference is exploited to partition and compute large expert parameters across multiple NDP units simultaneously towards edge low-batch scenarios. Second, a load-balancing-aware scheduling algorithm distributes expert computations across NDP units and GPU to maximize resource utilization. Third, a dataset-free pre-fetching strategy proactively loads frequently accessed experts to minimize activation delays. Experimental results show that our framework enables GPU-NDP systems to achieve 2.41x on average and up to 2.56x speedup in end-to-end latency compared to state-of-the-art approaches, significantly enhancing MoE inference efficiency in resource-constrained environments.
RcAE: Recursive Reconstruction Framework for Unsupervised Industrial Anomaly Detection
Dec 12, 2025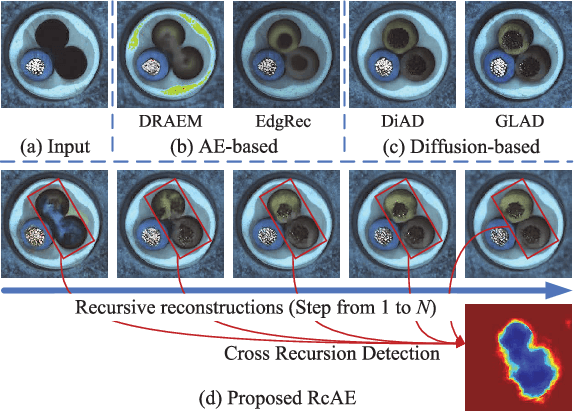
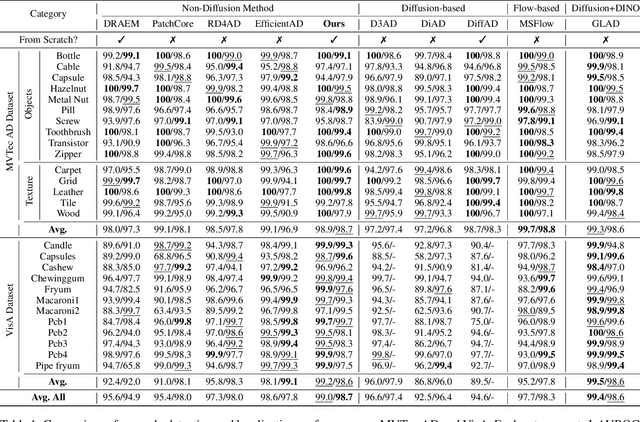
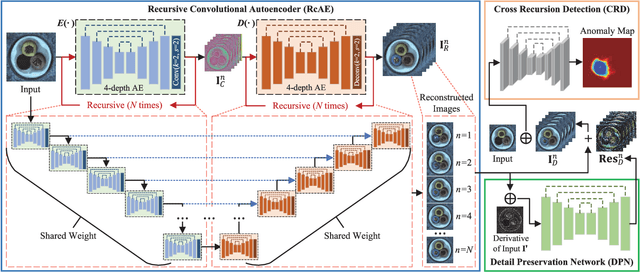
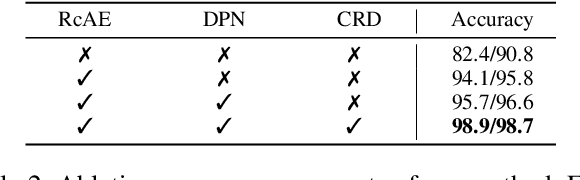
Unsupervised industrial anomaly detection requires accurately identifying defects without labeled data. Traditional autoencoder-based methods often struggle with incomplete anomaly suppression and loss of fine details, as their single-pass decoding fails to effectively handle anomalies with varying severity and scale. We propose a recursive architecture for autoencoder (RcAE), which performs reconstruction iteratively to progressively suppress anomalies while refining normal structures. Unlike traditional single-pass models, this recursive design naturally produces a sequence of reconstructions, progressively exposing suppressed abnormal patterns. To leverage this reconstruction dynamics, we introduce a Cross Recursion Detection (CRD) module that tracks inconsistencies across recursion steps, enhancing detection of both subtle and large-scale anomalies. Additionally, we incorporate a Detail Preservation Network (DPN) to recover high-frequency textures typically lost during reconstruction. Extensive experiments demonstrate that our method significantly outperforms existing non-diffusion methods, and achieves performance on par with recent diffusion models with only 10% of their parameters and offering substantially faster inference. These results highlight the practicality and efficiency of our approach for real-world applications.
Orthogonal greedy algorithm for linear operator learning with shallow neural network
Jan 06, 2025



Greedy algorithms, particularly the orthogonal greedy algorithm (OGA), have proven effective in training shallow neural networks for fitting functions and solving partial differential equations (PDEs). In this paper, we extend the application of OGA to the tasks of linear operator learning, which is equivalent to learning the kernel function through integral transforms. Firstly, a novel greedy algorithm is developed for kernel estimation rate in a new semi-inner product, which can be utilized to approximate the Green's function of linear PDEs from data. Secondly, we introduce the OGA for point-wise kernel estimation to further improve the approximation rate, achieving orders of accuracy improvement across various tasks and baseline models. In addition, we provide a theoretical analysis on the kernel estimation problem and the optimal approximation rates for both algorithms, establishing their efficacy and potential for future applications in PDEs and operator learning tasks.
Green Multigrid Network
Jul 04, 2024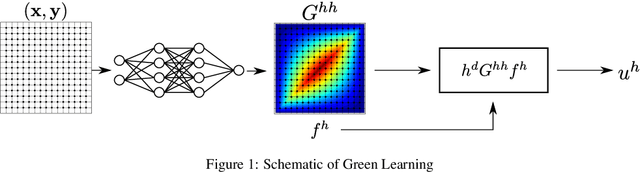

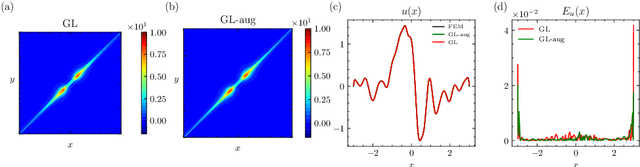
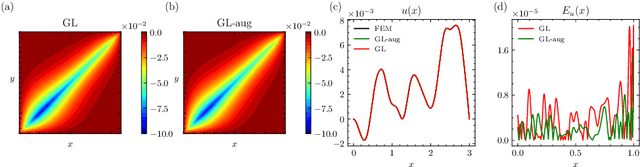
GreenLearning networks (GL) directly learn Green's function in physical space, making them an interpretable model for capturing unknown solution operators of partial differential equations (PDEs). For many PDEs, the corresponding Green's function exhibits asymptotic smoothness. In this paper, we propose a framework named Green Multigrid networks (GreenMGNet), an operator learning algorithm designed for a class of asymptotically smooth Green's functions. Compared with the pioneering GL, the new framework presents itself with better accuracy and efficiency, thereby achieving a significant improvement. GreenMGNet is composed of two technical novelties. First, Green's function is modeled as a piecewise function to take into account its singular behavior in some parts of the hyperplane. Such piecewise function is then approximated by a neural network with augmented output(AugNN) so that it can capture singularity accurately. Second, the asymptotic smoothness property of Green's function is used to leverage the Multi-Level Multi-Integration (MLMI) algorithm for both the training and inference stages. Several test cases of operator learning are presented to demonstrate the accuracy and effectiveness of the proposed method. On average, GreenMGNet achieves $3.8\%$ to $39.15\%$ accuracy improvement. To match the accuracy level of GL, GreenMGNet requires only about $10\%$ of the full grid data, resulting in a $55.9\%$ and $92.5\%$ reduction in training time and GPU memory cost for one-dimensional test problems, and a $37.7\%$ and $62.5\%$ reduction for two-dimensional test problems.
Understanding Parameter Sharing in Transformers
Jun 15, 2023

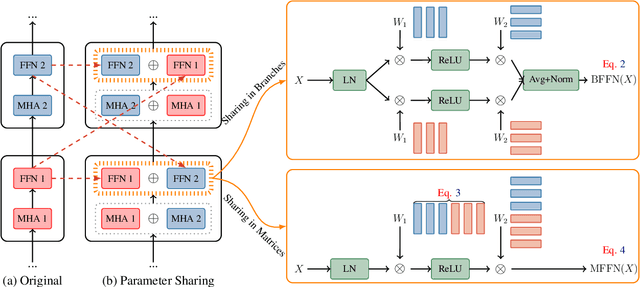

Parameter sharing has proven to be a parameter-efficient approach. Previous work on Transformers has focused on sharing parameters in different layers, which can improve the performance of models with limited parameters by increasing model depth. In this paper, we study why this approach works from two perspectives. First, increasing model depth makes the model more complex, and we hypothesize that the reason is related to model complexity (referring to FLOPs). Secondly, since each shared parameter will participate in the network computation several times in forward propagation, its corresponding gradient will have a different range of values from the original model, which will affect the model convergence. Based on this, we hypothesize that training convergence may also be one of the reasons. Through further analysis, we show that the success of this approach can be largely attributed to better convergence, with only a small part due to the increased model complexity. Inspired by this, we tune the training hyperparameters related to model convergence in a targeted manner. Experiments on 8 machine translation tasks show that our model achieves competitive performance with only half the model complexity of parameter sharing models.
MobileNMT: Enabling Translation in 15MB and 30ms
Jun 07, 2023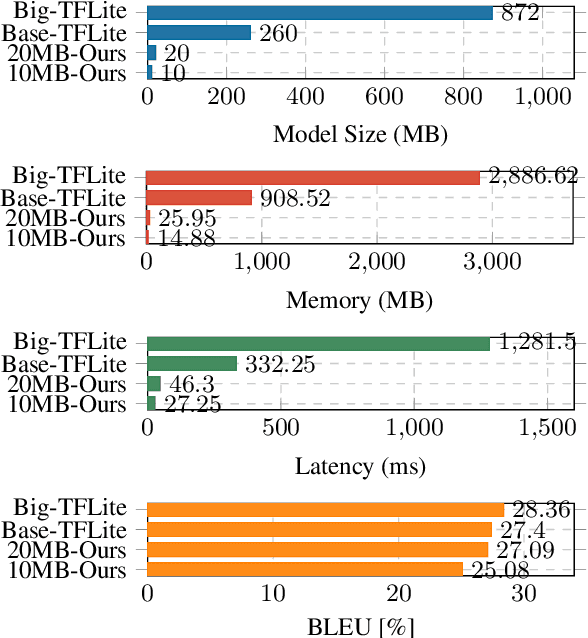
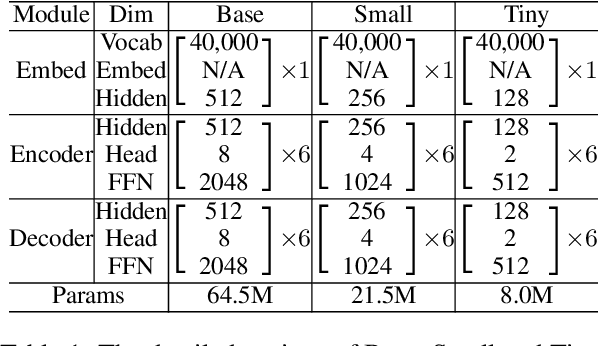
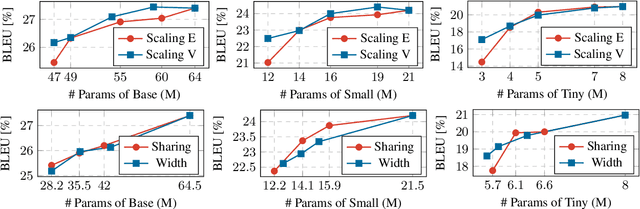
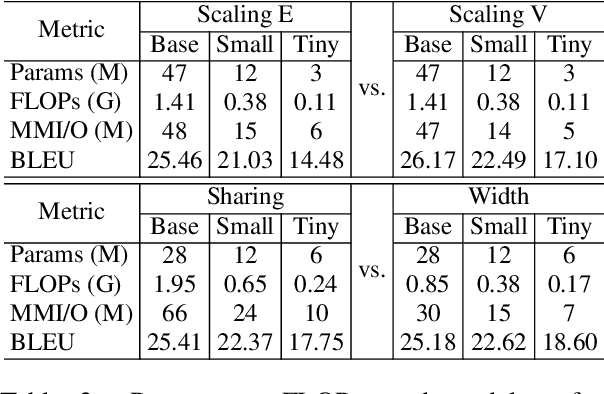
Deploying NMT models on mobile devices is essential for privacy, low latency, and offline scenarios. For high model capacity, NMT models are rather large. Running these models on devices is challenging with limited storage, memory, computation, and power consumption. Existing work either only focuses on a single metric such as FLOPs or general engine which is not good at auto-regressive decoding. In this paper, we present MobileNMT, a system that can translate in 15MB and 30ms on devices. We propose a series of principles for model compression when combined with quantization. Further, we implement an engine that is friendly to INT8 and decoding. With the co-design of model and engine, compared with the existing system, we speed up 47.0x and save 99.5% of memory with only 11.6% loss of BLEU. The code is publicly available at https://github.com/zjersey/Lightseq-ARM.
Multi-Path Transformer is Better: A Case Study on Neural Machine Translation
May 10, 2023



For years the model performance in machine learning obeyed a power-law relationship with the model size. For the consideration of parameter efficiency, recent studies focus on increasing model depth rather than width to achieve better performance. In this paper, we study how model width affects the Transformer model through a parameter-efficient multi-path structure. To better fuse features extracted from different paths, we add three additional operations to each sublayer: a normalization at the end of each path, a cheap operation to produce more features, and a learnable weighted mechanism to fuse all features flexibly. Extensive experiments on 12 WMT machine translation tasks show that, with the same number of parameters, the shallower multi-path model can achieve similar or even better performance than the deeper model. It reveals that we should pay more attention to the multi-path structure, and there should be a balance between the model depth and width to train a better large-scale Transformer.
The NiuTrans System for WNGT 2020 Efficiency Task
Sep 16, 2021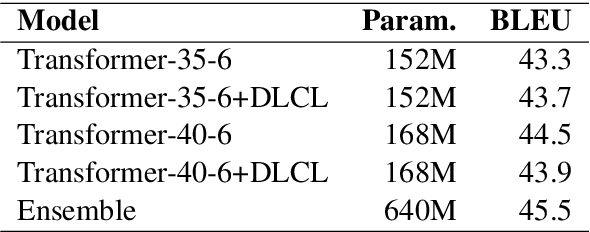

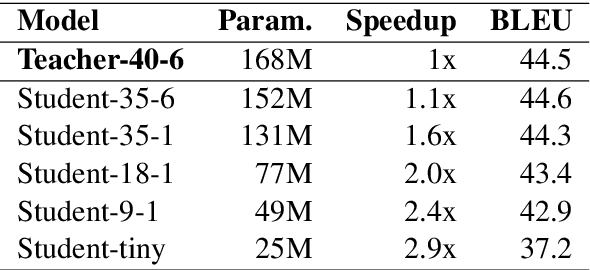
This paper describes the submissions of the NiuTrans Team to the WNGT 2020 Efficiency Shared Task. We focus on the efficient implementation of deep Transformer models \cite{wang-etal-2019-learning, li-etal-2019-niutrans} using NiuTensor (https://github.com/NiuTrans/NiuTensor), a flexible toolkit for NLP tasks. We explored the combination of deep encoder and shallow decoder in Transformer models via model compression and knowledge distillation. The neural machine translation decoding also benefits from FP16 inference, attention caching, dynamic batching, and batch pruning. Our systems achieve promising results in both translation quality and efficiency, e.g., our fastest system can translate more than 40,000 tokens per second with an RTX 2080 Ti while maintaining 42.9 BLEU on \textit{newstest2018}. The code, models, and docker images are available at NiuTrans.NMT (https://github.com/NiuTrans/NiuTrans.NMT).
The NiuTrans System for the WMT21 Efficiency Task
Sep 16, 2021
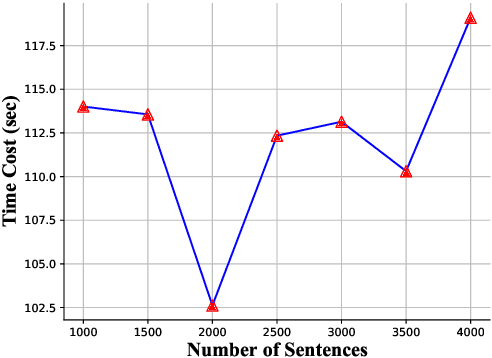

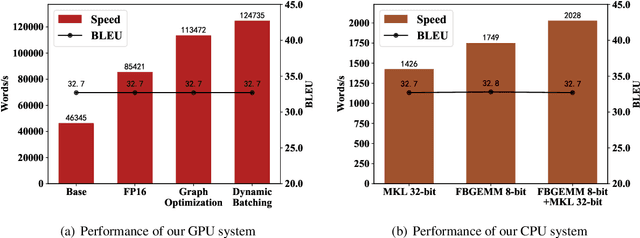
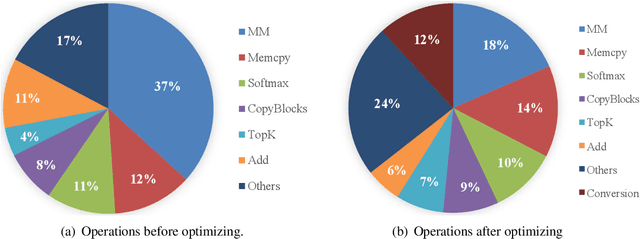
This paper describes the NiuTrans system for the WMT21 translation efficiency task (http://statmt.org/wmt21/efficiency-task.html). Following last year's work, we explore various techniques to improve efficiency while maintaining translation quality. We investigate the combinations of lightweight Transformer architectures and knowledge distillation strategies. Also, we improve the translation efficiency with graph optimization, low precision, dynamic batching, and parallel pre/post-processing. Our system can translate 247,000 words per second on an NVIDIA A100, being 3$\times$ faster than last year's system. Our system is the fastest and has the lowest memory consumption on the GPU-throughput track. The code, model, and pipeline will be available at NiuTrans.NMT (https://github.com/NiuTrans/NiuTrans.NMT).