 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKLIPA: A Knowledge Graph and LLM-Driven QA Framework for IP Analysis
Sep 09, 2025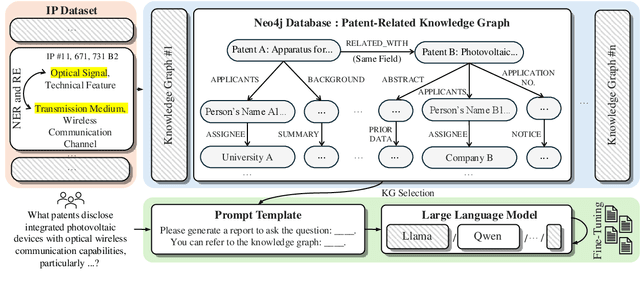
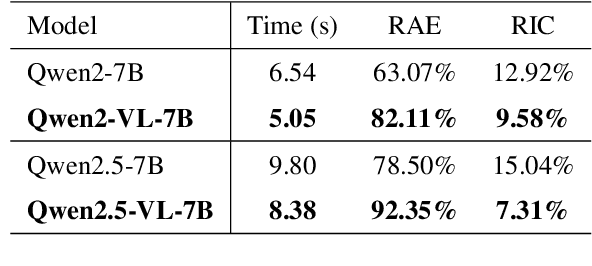
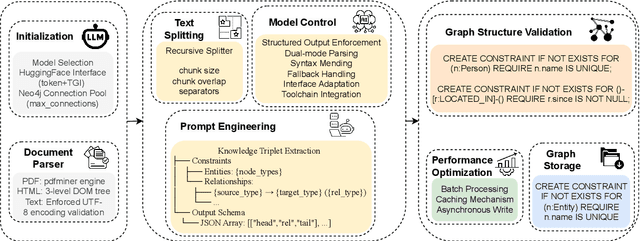
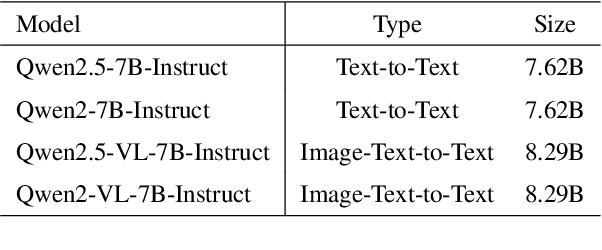
Effectively managing intellectual property is a significant challenge. Traditional methods for patent analysis depend on labor-intensive manual searches and rigid keyword matching. These approaches are often inefficient and struggle to reveal the complex relationships hidden within large patent datasets, hindering strategic decision-making. To overcome these limitations, we introduce KLIPA, a novel framework that leverages a knowledge graph and a large language model (LLM) to significantly advance patent analysis. Our approach integrates three key components: a structured knowledge graph to map explicit relationships between patents, a retrieval-augmented generation(RAG) system to uncover contextual connections, and an intelligent agent that dynamically determines the optimal strategy for resolving user queries. We validated KLIPA on a comprehensive, real-world patent database, where it demonstrated substantial improvements in knowledge extraction, discovery of novel connections, and overall operational efficiency. This combination of technologies enhances retrieval accuracy, reduces reliance on domain experts, and provides a scalable, automated solution for any organization managing intellectual property, including technology corporations and legal firms, allowing them to better navigate the complexities of strategic innovation and competitive intelligence.
DrugMCTS: a drug repurposing framework combining multi-agent, RAG and Monte Carlo Tree Search
Jul 10, 2025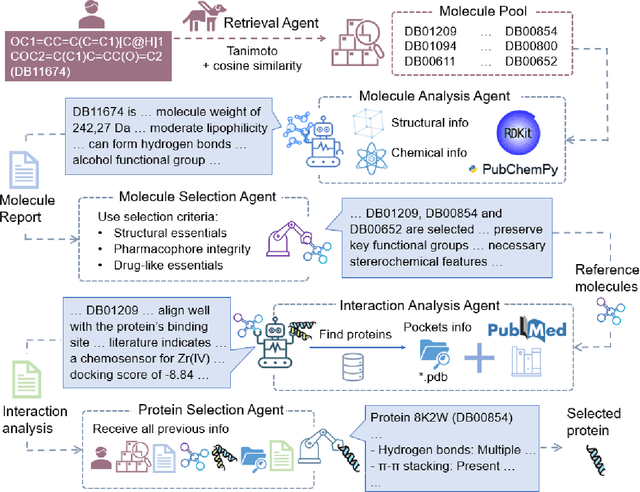
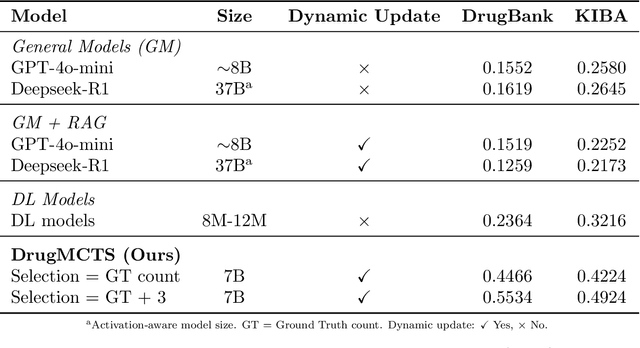

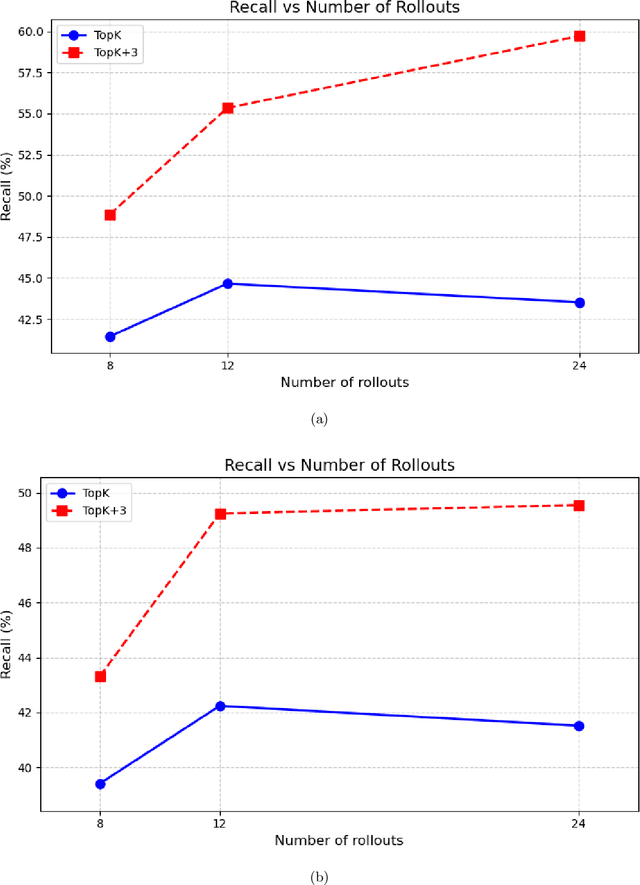
Recent advances in large language models have demonstrated considerable potential in scientific domains such as drug discovery. However, their effectiveness remains constrained when reasoning extends beyond the knowledge acquired during pretraining. Conventional approaches, such as fine-tuning or retrieval-augmented generation, face limitations in either imposing high computational overhead or failing to fully exploit structured scientific data. To overcome these challenges, we propose DrugMCTS, a novel framework that synergistically integrates RAG, multi-agent collaboration, and Monte Carlo Tree Search for drug repurposing. The framework employs five specialized agents tasked with retrieving and analyzing molecular and protein information, thereby enabling structured and iterative reasoning. Without requiring domain-specific fine-tuning, DrugMCTS empowers Qwen2.5-7B-Instruct to outperform Deepseek-R1 by over 20\%. Extensive experiments on the DrugBank and KIBA datasets demonstrate that DrugMCTS achieves substantially higher recall and robustness compared to both general-purpose LLMs and deep learning baselines. Our results highlight the importance of structured reasoning, agent-based collaboration, and feedback-driven search mechanisms in advancing LLM applications for drug discovery.
NDP: Next Distribution Prediction as a More Broad Target
Aug 30, 2024


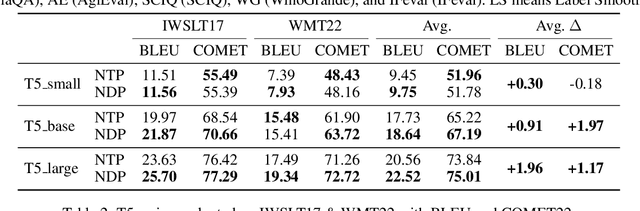
Large language models (LLMs) trained on next-token prediction (NTP) paradigm have demonstrated powerful capabilities. However, the existing NTP paradigm contains several limitations, particularly related to planned task complications and error propagation during inference. In our work, we extend the critique of NTP, highlighting its limitation also due to training with a narrow objective: the prediction of a sub-optimal one-hot distribution. To support this critique, we conducted a pre-experiment treating the output distribution from powerful LLMs as efficient world data compression. By evaluating the similarity between the $n$-gram distribution and the one-hot distribution with LLMs, we observed that the $n$-gram distributions align more closely with the output distribution of LLMs. Based on this insight, we introduce Next Distribution Prediction (NDP), which uses $n$-gram distributions to replace the one-hot targets, enhancing learning without extra online training time. We conducted experiments across translation, general task, language transfer, and medical domain adaptation. Compared to NTP, NDP can achieve up to +2.97 COMET improvement in translation tasks, +0.61 average improvement in general tasks, and incredible +10.75 average improvement in the medical domain. This demonstrates the concrete benefits of addressing the target narrowing problem, pointing to a new direction for future work on improving NTP.
Augmenting Large Language Model Translators via Translation Memories
May 27, 2023Using translation memories (TMs) as prompts is a promising approach to in-context learning of machine translation models. In this work, we take a step towards prompting large language models (LLMs) with TMs and making them better translators. We find that the ability of LLMs to ``understand'' prompts is indeed helpful for making better use of TMs. Experiments show that the results of a pre-trained LLM translator can be greatly improved by using high-quality TM-based prompts. These results are even comparable to those of the state-of-the-art NMT systems which have access to large-scale in-domain bilingual data and are well tuned on the downstream tasks.
RankNAS: Efficient Neural Architecture Search by Pairwise Ranking
Sep 17, 2021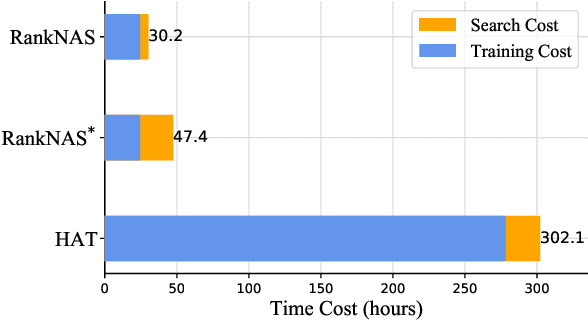

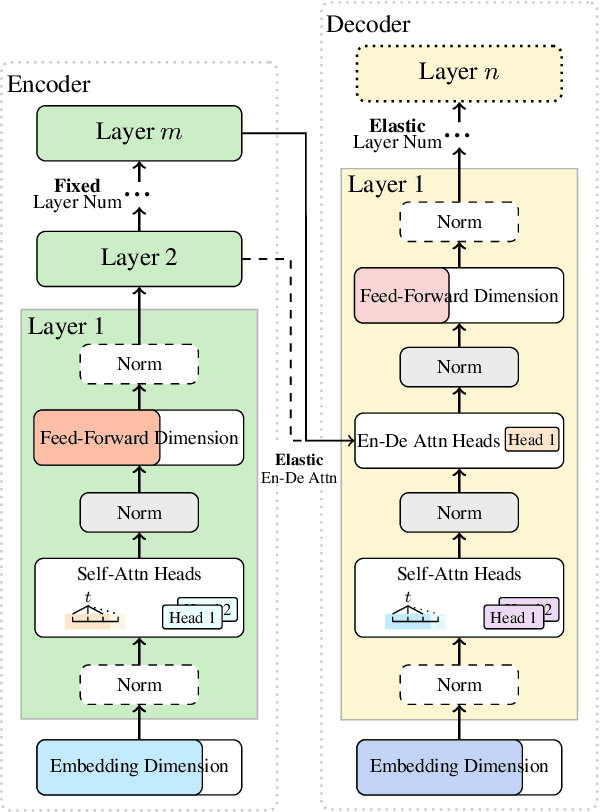
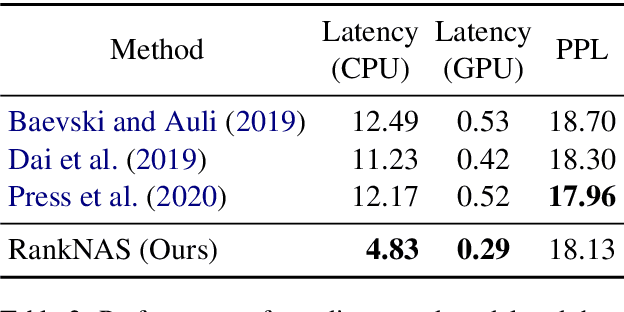
This paper addresses the efficiency challenge of Neural Architecture Search (NAS) by formulating the task as a ranking problem. Previous methods require numerous training examples to estimate the accurate performance of architectures, although the actual goal is to find the distinction between "good" and "bad" candidates. Here we do not resort to performance predictors. Instead, we propose a performance ranking method (RankNAS) via pairwise ranking. It enables efficient architecture search using much fewer training examples. Moreover, we develop an architecture selection method to prune the search space and concentrate on more promising candidates. Extensive experiments on machine translation and language modeling tasks show that RankNAS can design high-performance architectures while being orders of magnitude faster than state-of-the-art NAS systems.
The NiuTrans System for WNGT 2020 Efficiency Task
Sep 16, 2021

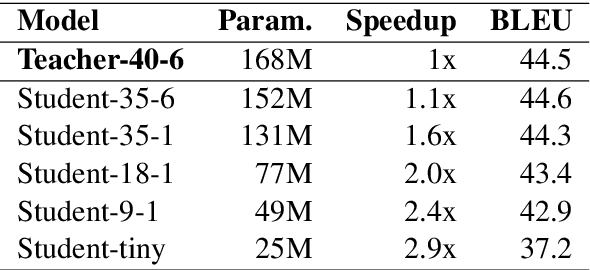
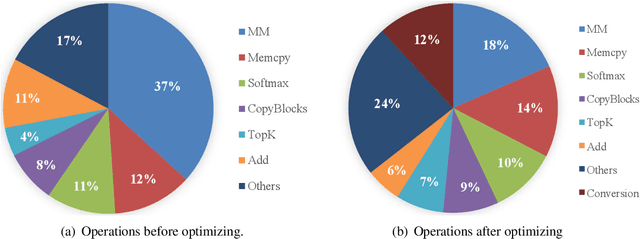
This paper describes the submissions of the NiuTrans Team to the WNGT 2020 Efficiency Shared Task. We focus on the efficient implementation of deep Transformer models \cite{wang-etal-2019-learning, li-etal-2019-niutrans} using NiuTensor (https://github.com/NiuTrans/NiuTensor), a flexible toolkit for NLP tasks. We explored the combination of deep encoder and shallow decoder in Transformer models via model compression and knowledge distillation. The neural machine translation decoding also benefits from FP16 inference, attention caching, dynamic batching, and batch pruning. Our systems achieve promising results in both translation quality and efficiency, e.g., our fastest system can translate more than 40,000 tokens per second with an RTX 2080 Ti while maintaining 42.9 BLEU on \textit{newstest2018}. The code, models, and docker images are available at NiuTrans.NMT (https://github.com/NiuTrans/NiuTrans.NMT).
Learning Architectures from an Extended Search Space for Language Modeling
Jun 05, 2020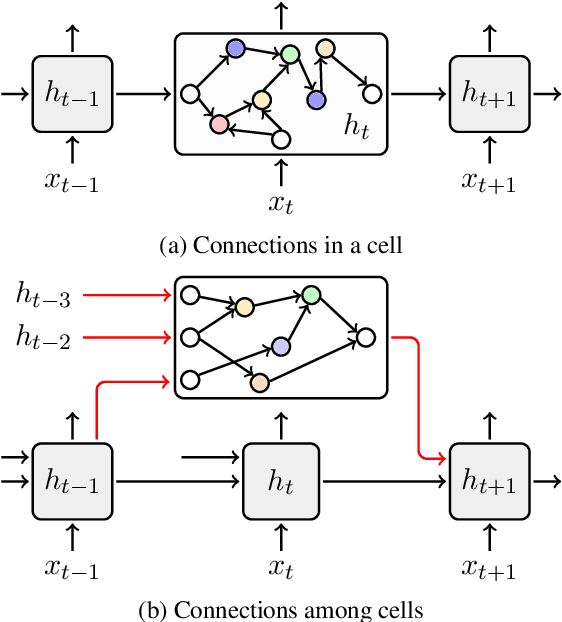


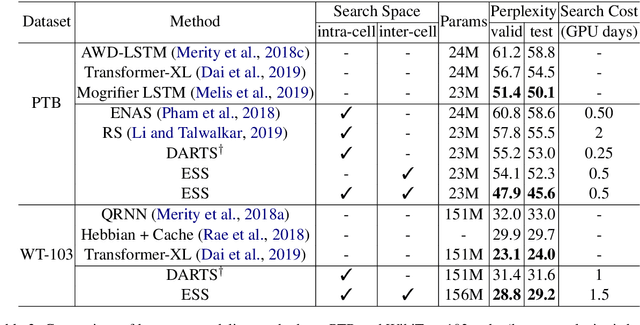
Neural architecture search (NAS) has advanced significantly in recent years but most NAS systems restrict search to learning architectures of a recurrent or convolutional cell. In this paper, we extend the search space of NAS. In particular, we present a general approach to learn both intra-cell and inter-cell architectures (call it ESS). For a better search result, we design a joint learning method to perform intra-cell and inter-cell NAS simultaneously. We implement our model in a differentiable architecture search system. For recurrent neural language modeling, it outperforms a strong baseline significantly on the PTB and WikiText data, with a new state-of-the-art on PTB. Moreover, the learned architectures show good transferability to other systems. E.g., they improve state-of-the-art systems on the CoNLL and WNUT named entity recognition (NER) tasks and CoNLL chunking task, indicating a promising line of research on large-scale pre-learned architectures.
Multi-layer Representation Fusion for Neural Machine Translation
Feb 16, 2020



Neural machine translation systems require a number of stacked layers for deep models. But the prediction depends on the sentence representation of the top-most layer with no access to low-level representations. This makes it more difficult to train the model and poses a risk of information loss to prediction. In this paper, we propose a multi-layer representation fusion (MLRF) approach to fusing stacked layers. In particular, we design three fusion functions to learn a better representation from the stack. Experimental results show that our approach yields improvements of 0.92 and 0.56 BLEU points over the strong Transformer baseline on IWSLT German-English and NIST Chinese-English MT tasks respectively. The result is new state-of-the-art in German-English translation.
Sharing Attention Weights for Fast Transformer
Jun 26, 2019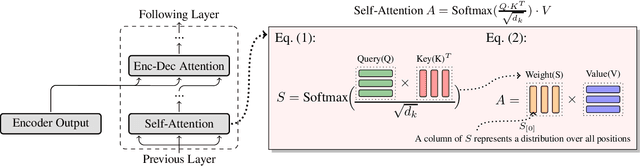



Recently, the Transformer machine translation system has shown strong results by stacking attention layers on both the source and target-language sides. But the inference of this model is slow due to the heavy use of dot-product attention in auto-regressive decoding. In this paper we speed up Transformer via a fast and lightweight attention model. More specifically, we share attention weights in adjacent layers and enable the efficient re-use of hidden states in a vertical manner. Moreover, the sharing policy can be jointly learned with the MT model. We test our approach on ten WMT and NIST OpenMT tasks. Experimental results show that it yields an average of 1.3X speed-up (with almost no decrease in BLEU) on top of a state-of-the-art implementation that has already adopted a cache for fast inference. Also, our approach obtains a 1.8X speed-up when it works with the \textsc{Aan} model. This is even 16 times faster than the baseline with no use of the attention cache.