 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNDP: Next Distribution Prediction as a More Broad Target
Aug 30, 2024


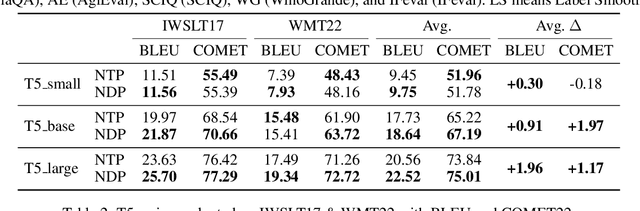
Large language models (LLMs) trained on next-token prediction (NTP) paradigm have demonstrated powerful capabilities. However, the existing NTP paradigm contains several limitations, particularly related to planned task complications and error propagation during inference. In our work, we extend the critique of NTP, highlighting its limitation also due to training with a narrow objective: the prediction of a sub-optimal one-hot distribution. To support this critique, we conducted a pre-experiment treating the output distribution from powerful LLMs as efficient world data compression. By evaluating the similarity between the $n$-gram distribution and the one-hot distribution with LLMs, we observed that the $n$-gram distributions align more closely with the output distribution of LLMs. Based on this insight, we introduce Next Distribution Prediction (NDP), which uses $n$-gram distributions to replace the one-hot targets, enhancing learning without extra online training time. We conducted experiments across translation, general task, language transfer, and medical domain adaptation. Compared to NTP, NDP can achieve up to +2.97 COMET improvement in translation tasks, +0.61 average improvement in general tasks, and incredible +10.75 average improvement in the medical domain. This demonstrates the concrete benefits of addressing the target narrowing problem, pointing to a new direction for future work on improving NTP.