 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpanNorm: Reconciling Training Stability and Performance in Deep Transformers
Jan 30, 2026The success of Large Language Models (LLMs) hinges on the stable training of deep Transformer architectures. A critical design choice is the placement of normalization layers, leading to a fundamental trade-off: the ``PreNorm'' architecture ensures training stability at the cost of potential performance degradation in deep models, while the ``PostNorm'' architecture offers strong performance but suffers from severe training instability. In this work, we propose SpanNorm, a novel technique designed to resolve this dilemma by integrating the strengths of both paradigms. Structurally, SpanNorm establishes a clean residual connection that spans the entire transformer block to stabilize signal propagation, while employing a PostNorm-style computation that normalizes the aggregated output to enhance model performance. We provide a theoretical analysis demonstrating that SpanNorm, combined with a principled scaling strategy, maintains bounded signal variance throughout the network, preventing the gradient issues that plague PostNorm models, and also alleviating the representation collapse of PreNorm. Empirically, SpanNorm consistently outperforms standard normalization schemes in both dense and Mixture-of-Experts (MoE) scenarios, paving the way for more powerful and stable Transformer architectures.
ClueAnchor: Clue-Anchored Knowledge Reasoning Exploration and Optimization for Retrieval-Augmented Generation
May 30, 2025Retrieval-Augmented Generation (RAG) augments Large Language Models (LLMs) with external knowledge to improve factuality. However, existing RAG systems frequently underutilize the retrieved documents, failing to extract and integrate the key clues needed to support faithful and interpretable reasoning, especially in cases where relevant evidence is implicit, scattered, or obscured by noise. To address this issue, we propose ClueAnchor, a novel framework for enhancing RAG via clue-anchored reasoning exploration and optimization. ClueAnchor extracts key clues from retrieved content and generates multiple reasoning paths based on different knowledge configurations, optimizing the model by selecting the most effective one through reward-based preference optimization. Experiments show that ClueAnchor significantly outperforms prior RAG baselines in reasoning completeness and robustness. Further analysis confirms its strong resilience to noisy or partially relevant retrieved content, as well as its capability to identify supporting evidence even in the absence of explicit clue supervision during inference.
SLAM: Towards Efficient Multilingual Reasoning via Selective Language Alignment
Jan 07, 2025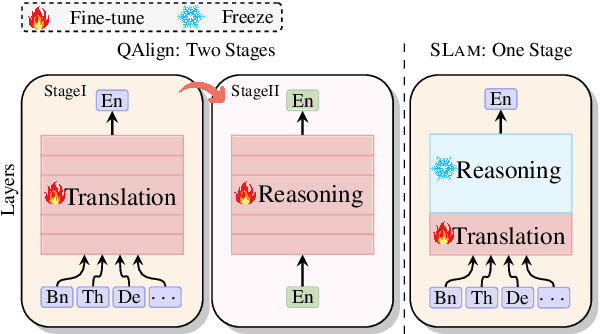


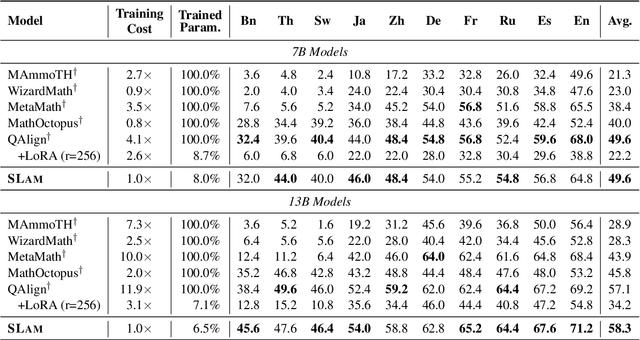
Despite the significant improvements achieved by large language models (LLMs) in English reasoning tasks, these models continue to struggle with multilingual reasoning. Recent studies leverage a full-parameter and two-stage training paradigm to teach models to first understand non-English questions and then reason. However, this method suffers from both substantial computational resource computing and catastrophic forgetting. The fundamental cause is that, with the primary goal of enhancing multilingual comprehension, an excessive number of irrelevant layers and parameters are tuned during the first stage. Given our findings that the representation learning of languages is merely conducted in lower-level layers, we propose an efficient multilingual reasoning alignment approach that precisely identifies and fine-tunes the layers responsible for handling multilingualism. Experimental results show that our method, SLAM, only tunes 6 layers' feed-forward sub-layers including 6.5-8% of all parameters within 7B and 13B LLMs, achieving superior average performance than all strong baselines across 10 languages. Meanwhile, SLAM only involves one training stage, reducing training time by 4.1-11.9 compared to the two-stage method.
Advancing Large Language Model Attribution through Self-Improving
Oct 17, 2024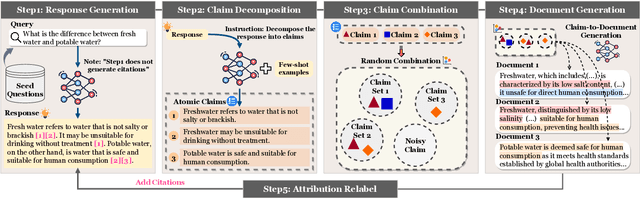
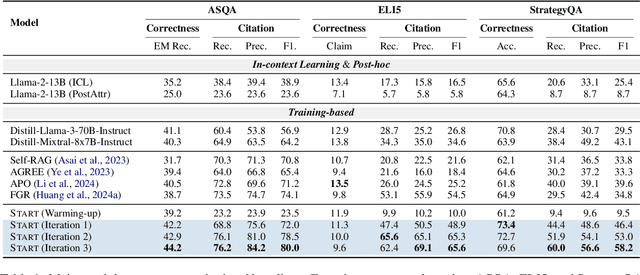
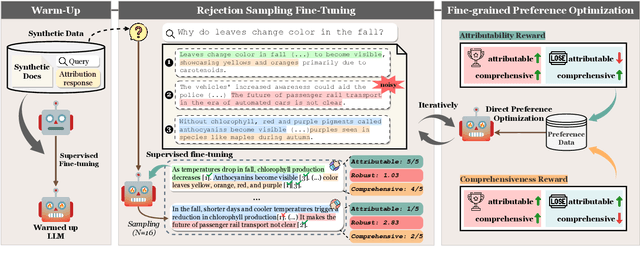
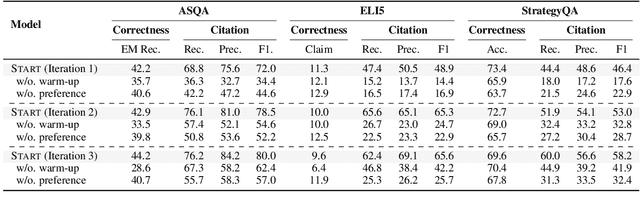
Teaching large language models (LLMs) to generate text with citations to evidence sources can mitigate hallucinations and enhance verifiability in information-seeking systems. However, improving this capability requires high-quality attribution data, which is costly and labor-intensive. Inspired by recent advances in self-improvement that enhance LLMs without manual annotation, we present START, a Self-Taught AttRibuTion framework for iteratively improving the attribution capability of LLMs. First, to prevent models from stagnating due to initially insufficient supervision signals, START leverages the model to self-construct synthetic training data for warming up. To further self-improve the model's attribution ability, START iteratively utilizes fine-grained preference supervision signals constructed from its sampled responses to encourage robust, comprehensive, and attributable generation. Experiments on three open-domain question-answering datasets, covering long-form QA and multi-step reasoning, demonstrate significant performance gains of 25.13% on average without relying on human annotations and more advanced models. Further analysis reveals that START excels in aggregating information across multiple sources.
NDP: Next Distribution Prediction as a More Broad Target
Aug 30, 2024


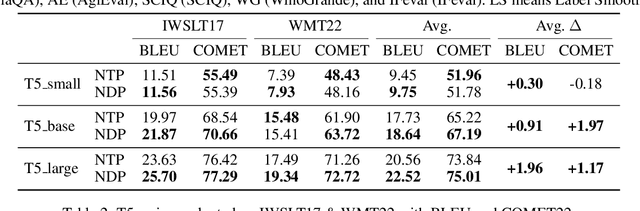
Large language models (LLMs) trained on next-token prediction (NTP) paradigm have demonstrated powerful capabilities. However, the existing NTP paradigm contains several limitations, particularly related to planned task complications and error propagation during inference. In our work, we extend the critique of NTP, highlighting its limitation also due to training with a narrow objective: the prediction of a sub-optimal one-hot distribution. To support this critique, we conducted a pre-experiment treating the output distribution from powerful LLMs as efficient world data compression. By evaluating the similarity between the $n$-gram distribution and the one-hot distribution with LLMs, we observed that the $n$-gram distributions align more closely with the output distribution of LLMs. Based on this insight, we introduce Next Distribution Prediction (NDP), which uses $n$-gram distributions to replace the one-hot targets, enhancing learning without extra online training time. We conducted experiments across translation, general task, language transfer, and medical domain adaptation. Compared to NTP, NDP can achieve up to +2.97 COMET improvement in translation tasks, +0.61 average improvement in general tasks, and incredible +10.75 average improvement in the medical domain. This demonstrates the concrete benefits of addressing the target narrowing problem, pointing to a new direction for future work on improving NTP.
Cross-layer Attention Sharing for Large Language Models
Aug 04, 2024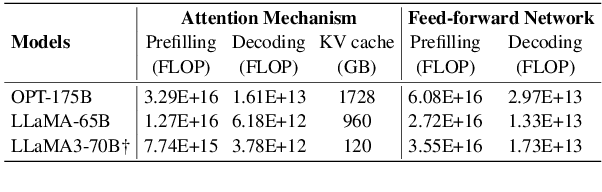
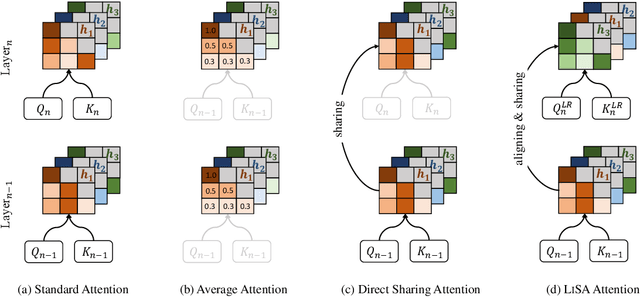
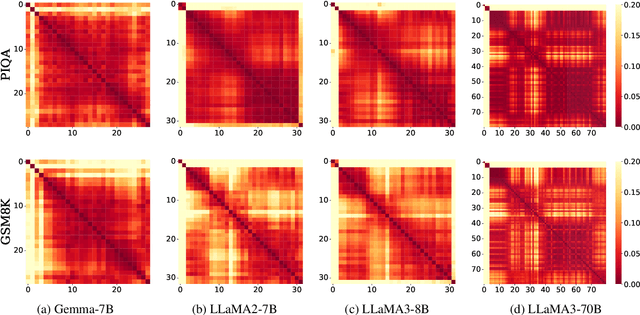
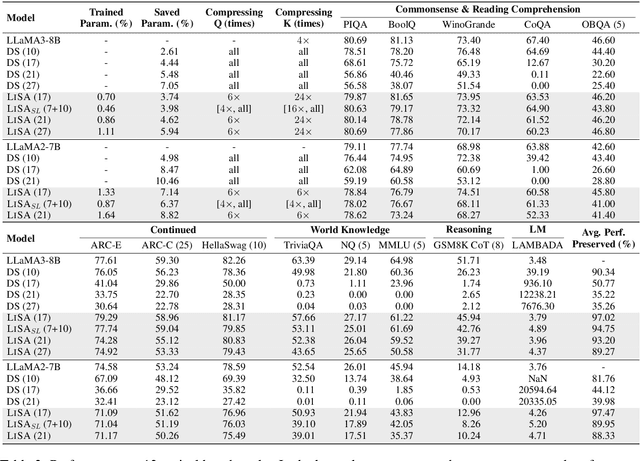
As large language models (LLMs) evolve, the increase in model depth and parameter number leads to substantial redundancy. To enhance the efficiency of the attention mechanism, previous works primarily compress the KV cache or group attention heads, while largely overlooking redundancy between layers. Our comprehensive analyses across various LLMs show that highly similar attention patterns persist within most layers. It's intuitive to save the computation by sharing attention weights across layers. However, further analysis reveals two challenges: (1) Directly sharing the weight matrix without carefully rearranging the attention heads proves to be ineffective; (2) Shallow layers are vulnerable to small deviations in attention weights. Driven by these insights, we introduce LiSA, a lightweight substitute for self-attention in well-trained LLMs. LiSA employs tiny feed-forward networks to align attention heads between adjacent layers and low-rank matrices to approximate differences in layer-wise attention weights. Evaluations encompassing 13 typical benchmarks demonstrate that LiSA maintains high response quality in terms of accuracy and perplexity while reducing redundant attention calculations within 53-84% of the total layers. Our implementations of LiSA achieve a 6X compression of Q and K, with maximum throughput improvements of 19.5% for LLaMA3-8B and 32.3% for LLaMA2-7B.
Augmenting Large Language Model Translators via Translation Memories
May 27, 2023Using translation memories (TMs) as prompts is a promising approach to in-context learning of machine translation models. In this work, we take a step towards prompting large language models (LLMs) with TMs and making them better translators. We find that the ability of LLMs to ``understand'' prompts is indeed helpful for making better use of TMs. Experiments show that the results of a pre-trained LLM translator can be greatly improved by using high-quality TM-based prompts. These results are even comparable to those of the state-of-the-art NMT systems which have access to large-scale in-domain bilingual data and are well tuned on the downstream tasks.