 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSilence the Judge: Reinforcement Learning with Self-Verifier via Latent Geometric Clustering
Jan 13, 2026Group Relative Policy Optimization (GRPO) significantly enhances the reasoning performance of Large Language Models (LLMs). However, this success heavily relies on expensive external verifiers or human rules. Such dependency not only leads to significant computational costs and training latency, but also yields sparse rewards that hinder optimization efficiency. To address these challenges, we propose Latent-GRPO, a framework that derives intrinsic rewards directly from latent space geometry. Crucially, our empirical analysis reveals a compelling geometric property: terminal token representations of correct reasoning trajectories form dense clusters with high intra-class similarity, whereas incorrect trajectories remain scattered as outliers. In light of this discovery, we introduce the Iterative Robust Centroid Estimation (IRCE) algorithm, which generates dense, continuous rewards by mitigating magnitude fluctuations via spherical projection and estimating a robust ``truth centroid'' through iterative aggregation. Experimental results on multiple datasets show that our method maintains model performance while achieving a training speedup of over 2x compared to baselines. Furthermore, extensive results demonstrate strong generalization ability and robustness. The code will be released soon.
Fine-Mem: Fine-Grained Feedback Alignment for Long-Horizon Memory Management
Jan 13, 2026Effective memory management is essential for large language model agents to navigate long-horizon tasks. Recent research has explored using Reinforcement Learning to develop specialized memory manager agents. However, existing approaches rely on final task performance as the primary reward, which results in severe reward sparsity and ineffective credit assignment, providing insufficient guidance for individual memory operations. To this end, we propose Fine-Mem, a unified framework designed for fine-grained feedback alignment. First, we introduce a Chunk-level Step Reward to provide immediate step-level supervision via auxiliary chunk-specific question answering tasks. Second, we devise Evidence-Anchored Reward Attribution to redistribute global rewards by anchoring credit to key memory operations, based on the specific memory items utilized as evidence in reasoning. Together, these components enable stable policy optimization and align local memory operations with the long-term utility of memory. Experiments on Memalpha and MemoryAgentBench demonstrate that Fine-Mem consistently outperforms strong baselines, achieving superior success rates across various sub-tasks. Further analysis reveals its adaptability and strong generalization capabilities across diverse model configurations and backbones.
Causal Tracing of Object Representations in Large Vision Language Models: Mechanistic Interpretability and Hallucination Mitigation
Nov 19, 2025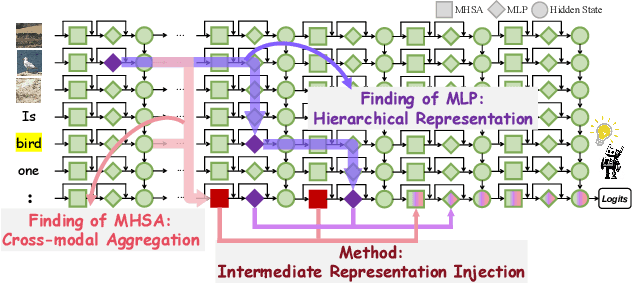

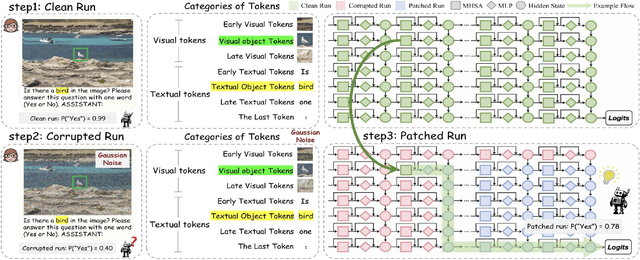
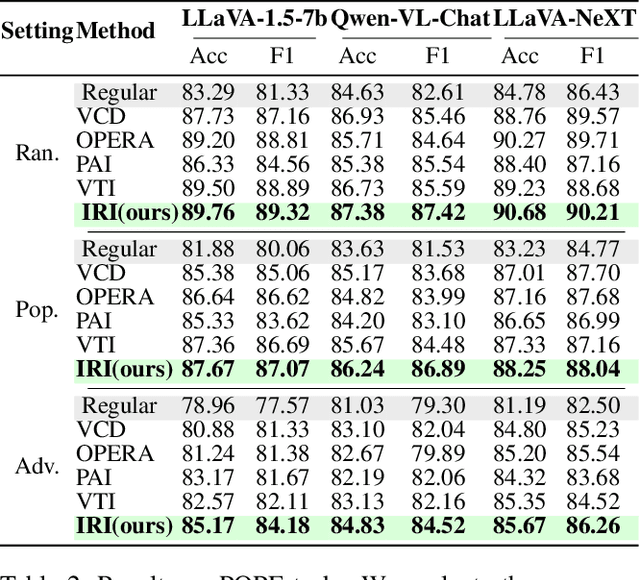
Despite the remarkable advancements of Large Vision-Language Models (LVLMs), the mechanistic interpretability remains underexplored. Existing analyses are insufficiently comprehensive and lack examination covering visual and textual tokens, model components, and the full range of layers. This limitation restricts actionable insights to improve the faithfulness of model output and the development of downstream tasks, such as hallucination mitigation. To address this limitation, we introduce Fine-grained Cross-modal Causal Tracing (FCCT) framework, which systematically quantifies the causal effects on visual object perception. FCCT conducts fine-grained analysis covering the full range of visual and textual tokens, three core model components including multi-head self-attention (MHSA), feed-forward networks (FFNs), and hidden states, across all decoder layers. Our analysis is the first to demonstrate that MHSAs of the last token in middle layers play a critical role in aggregating cross-modal information, while FFNs exhibit a three-stage hierarchical progression for the storage and transfer of visual object representations. Building on these insights, we propose Intermediate Representation Injection (IRI), a training-free inference-time technique that reinforces visual object information flow by precisely intervening on cross-modal representations at specific components and layers, thereby enhancing perception and mitigating hallucination. Consistent improvements across five widely used benchmarks and LVLMs demonstrate IRI achieves state-of-the-art performance, while preserving inference speed and other foundational performance.
LangGPS: Language Separability Guided Data Pre-Selection for Joint Multilingual Instruction Tuning
Nov 13, 2025Joint multilingual instruction tuning is a widely adopted approach to improve the multilingual instruction-following ability and downstream performance of large language models (LLMs), but the resulting multilingual capability remains highly sensitive to the composition and selection of the training data. Existing selection methods, often based on features like text quality, diversity, or task relevance, typically overlook the intrinsic linguistic structure of multilingual data. In this paper, we propose LangGPS, a lightweight two-stage pre-selection framework guided by language separability which quantifies how well samples in different languages can be distinguished in the model's representation space. LangGPS first filters training data based on separability scores and then refines the subset using existing selection methods. Extensive experiments across six benchmarks and 22 languages demonstrate that applying LangGPS on top of existing selection methods improves their effectiveness and generalizability in multilingual training, especially for understanding tasks and low-resource languages. Further analysis reveals that highly separable samples facilitate the formation of clearer language boundaries and support faster adaptation, while low-separability samples tend to function as bridges for cross-lingual alignment. Besides, we also find that language separability can serve as an effective signal for multilingual curriculum learning, where interleaving samples with diverse separability levels yields stable and generalizable gains. Together, we hope our work offers a new perspective on data utility in multilingual contexts and support the development of more linguistically informed LLMs.
Adaptive Backtracking for Privacy Protection in Large Language Models
Aug 08, 2025The preservation of privacy has emerged as a critical topic in the era of artificial intelligence. However, current work focuses on user-oriented privacy, overlooking severe enterprise data leakage risks exacerbated by the Retrieval-Augmented Generation paradigm. To address this gap, our paper introduces a novel objective: enterprise-oriented privacy concerns. Achieving this objective requires overcoming two fundamental challenges: existing methods such as data sanitization severely degrade model performance, and the field lacks public datasets for evaluation. We address these challenges with several solutions. (1) To prevent performance degradation, we propose ABack, a training-free mechanism that leverages a Hidden State Model to pinpoint the origin of a leakage intention and rewrite the output safely. (2) To solve the lack of datasets, we construct PriGenQA, a new benchmark for enterprise privacy scenarios in healthcare and finance. To ensure a rigorous evaluation, we move beyond simple static attacks by developing a powerful adaptive attacker with Group Relative Policy Optimization. Experiments show that against this superior adversary, ABack improves the overall privacy utility score by up to 15\% over strong baselines, avoiding the performance trade-offs of prior methods.
From Hypothesis to Publication: A Comprehensive Survey of AI-Driven Research Support Systems
Mar 03, 2025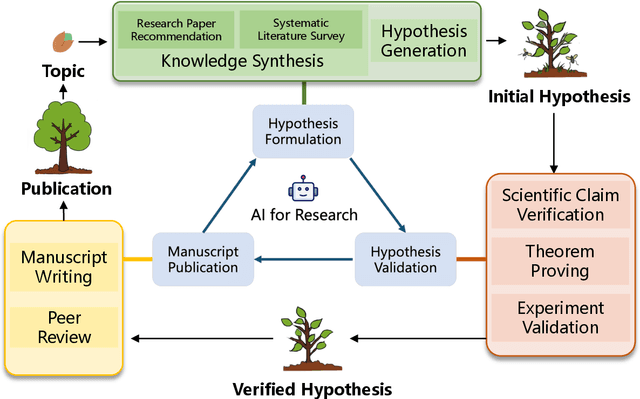
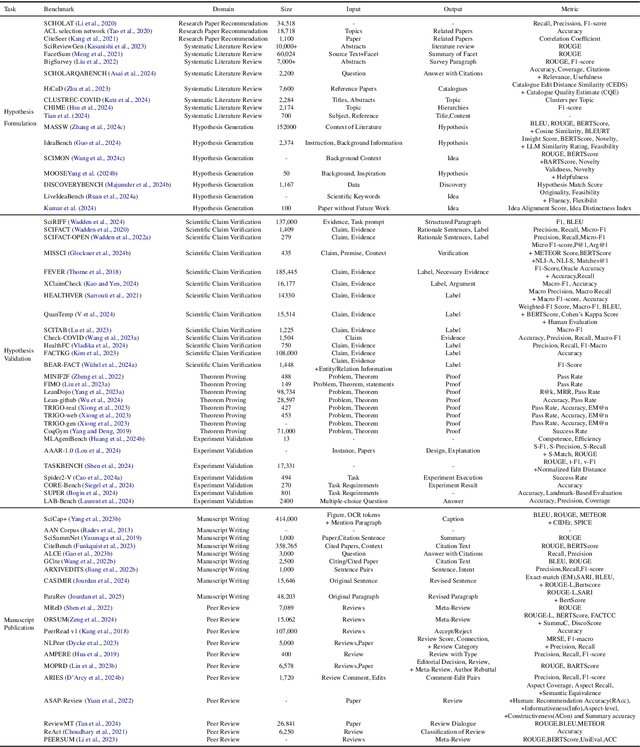

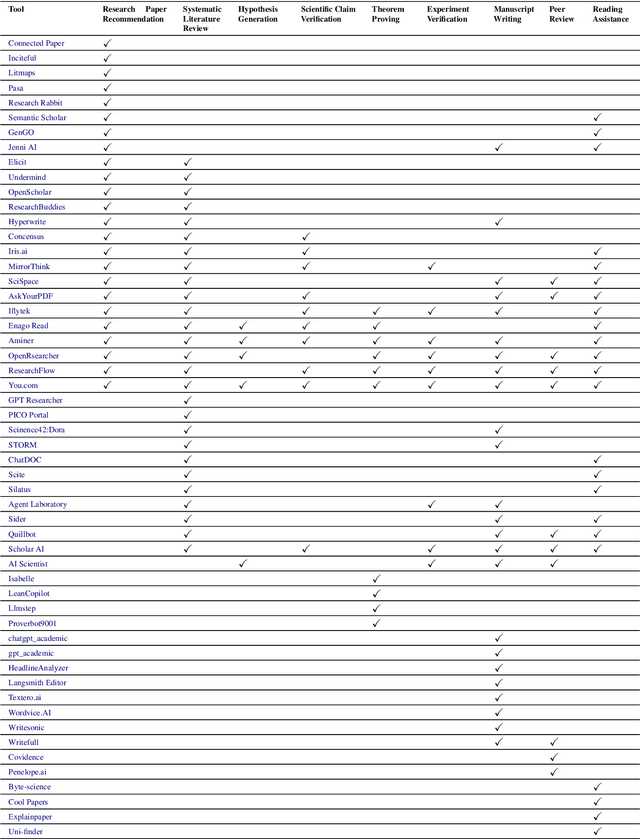
Research is a fundamental process driving the advancement of human civilization, yet it demands substantial time and effort from researchers. In recent years, the rapid development of artificial intelligence (AI) technologies has inspired researchers to explore how AI can accelerate and enhance research. To monitor relevant advancements, this paper presents a systematic review of the progress in this domain. Specifically, we organize the relevant studies into three main categories: hypothesis formulation, hypothesis validation, and manuscript publication. Hypothesis formulation involves knowledge synthesis and hypothesis generation. Hypothesis validation includes the verification of scientific claims, theorem proving, and experiment validation. Manuscript publication encompasses manuscript writing and the peer review process. Furthermore, we identify and discuss the current challenges faced in these areas, as well as potential future directions for research. Finally, we also offer a comprehensive overview of existing benchmarks and tools across various domains that support the integration of AI into the research process. We hope this paper serves as an introduction for beginners and fosters future research. Resources have been made publicly available at https://github.com/zkzhou126/AI-for-Research.
XTransplant: A Probe into the Upper Bound Performance of Multilingual Capability and Culture Adaptability in LLMs via Mutual Cross-lingual Feed-forward Transplantation
Dec 17, 2024Current large language models (LLMs) often exhibit imbalances in multilingual capabilities and cultural adaptability, largely due to their English-centric pretraining data. To address this imbalance, we propose a probing method named XTransplant that explores cross-lingual latent interactions via cross-lingual feed-forward transplantation during inference stage, with the hope of enabling the model to leverage the strengths of both English and non-English languages. Through extensive pilot experiments, we empirically prove that both the multilingual capabilities and cultural adaptability of LLMs hold the potential to be significantly improved by XTransplant, respectively from En -> non-En and non-En -> En, highlighting the underutilization of current LLMs' multilingual potential. And the patterns observed in these pilot experiments further motivate an offline scaling inference strategy, which demonstrates consistent performance improvements in multilingual and culture-aware tasks, sometimes even surpassing multilingual supervised fine-tuning. And we do hope our further analysis and discussion could help gain deeper insights into XTransplant mechanism.
Advancing Large Language Model Attribution through Self-Improving
Oct 17, 2024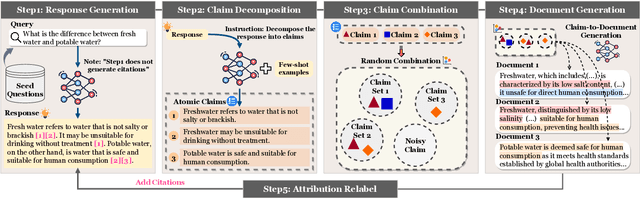
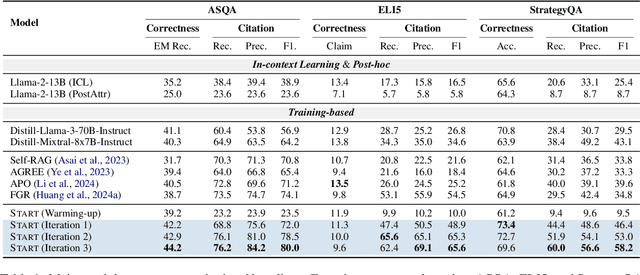
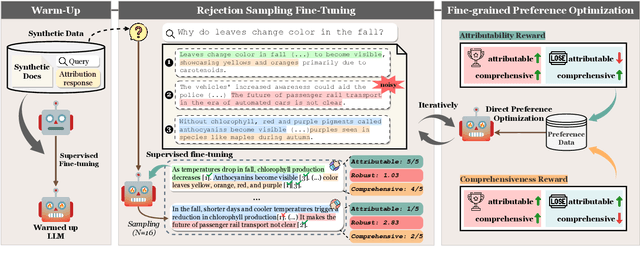
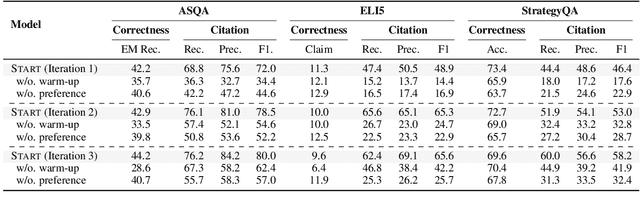
Teaching large language models (LLMs) to generate text with citations to evidence sources can mitigate hallucinations and enhance verifiability in information-seeking systems. However, improving this capability requires high-quality attribution data, which is costly and labor-intensive. Inspired by recent advances in self-improvement that enhance LLMs without manual annotation, we present START, a Self-Taught AttRibuTion framework for iteratively improving the attribution capability of LLMs. First, to prevent models from stagnating due to initially insufficient supervision signals, START leverages the model to self-construct synthetic training data for warming up. To further self-improve the model's attribution ability, START iteratively utilizes fine-grained preference supervision signals constructed from its sampled responses to encourage robust, comprehensive, and attributable generation. Experiments on three open-domain question-answering datasets, covering long-form QA and multi-step reasoning, demonstrate significant performance gains of 25.13% on average without relying on human annotations and more advanced models. Further analysis reveals that START excels in aggregating information across multiple sources.
GlobeSumm: A Challenging Benchmark Towards Unifying Multi-lingual, Cross-lingual and Multi-document News Summarization
Oct 05, 2024



News summarization in today's global scene can be daunting with its flood of multilingual content and varied viewpoints from different sources. However, current studies often neglect such real-world scenarios as they tend to focus solely on either single-language or single-document tasks. To bridge this gap, we aim to unify Multi-lingual, Cross-lingual and Multi-document Summarization into a novel task, i.e., MCMS, which encapsulates the real-world requirements all-in-one. Nevertheless, the lack of a benchmark inhibits researchers from adequately studying this invaluable problem. To tackle this, we have meticulously constructed the GLOBESUMM dataset by first collecting a wealth of multilingual news reports and restructuring them into event-centric format. Additionally, we introduce the method of protocol-guided prompting for high-quality and cost-effective reference annotation. In MCMS, we also highlight the challenge of conflicts between news reports, in addition to the issues of redundancies and omissions, further enhancing the complexity of GLOBESUMM. Through extensive experimental analysis, we validate the quality of our dataset and elucidate the inherent challenges of the task. We firmly believe that GLOBESUMM, given its challenging nature, will greatly contribute to the multilingual communities and the evaluation of LLMs.
Learning Fine-Grained Grounded Citations for Attributed Large Language Models
Aug 08, 2024Despite the impressive performance on information-seeking tasks, large language models (LLMs) still struggle with hallucinations. Attributed LLMs, which augment generated text with in-line citations, have shown potential in mitigating hallucinations and improving verifiability. However, current approaches suffer from suboptimal citation quality due to their reliance on in-context learning. Furthermore, the practice of citing only coarse document identifiers makes it challenging for users to perform fine-grained verification. In this work, we introduce FRONT, a training framework designed to teach LLMs to generate Fine-Grained Grounded Citations. By grounding model outputs in fine-grained supporting quotes, these quotes guide the generation of grounded and consistent responses, not only improving citation quality but also facilitating fine-grained verification. Experiments on the ALCE benchmark demonstrate the efficacy of FRONT in generating superior grounded responses and highly supportive citations. With LLaMA-2-7B, the framework significantly outperforms all the baselines, achieving an average of 14.21% improvement in citation quality across all datasets, even surpassing ChatGPT.