 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Tokens See Equally: Perception-Grounded Policy Optimization for Large Vision-Language Models
Apr 02, 2026While Reinforcement Learning from Verifiable Rewards (RLVR) has advanced reasoning in Large Vision-Language Models (LVLMs), prevailing frameworks suffer from a foundational methodological flaw: by distributing identical advantages across all generated tokens, these methods inherently dilute the learning signals essential for optimizing the critical, visually-grounded steps of multimodal reasoning. To bridge this gap, we formulate \textit{Token Visual Dependency}, quantifying the causal information gain of visual inputs via the Kullback-Leibler (KL) divergence between visual-conditioned and text-only predictive distributions. Revealing that this dependency is highly sparse and semantically pivotal, we introduce Perception-Grounded Policy Optimization (PGPO), which is a novel fine-grained credit assignment framework that dynamically reshapes advantages at the token level. Through a threshold-gated, mass-conserving mechanism, PGPO actively amplifies learning signals for visually-dependent tokens while suppressing gradient noise from linguistic priors. Extensive experiments based on the Qwen2.5-VL series across seven challenging multimodal reasoning benchmarks demonstrate that PGPO boosts models by 18.7% on average. Both theoretical and empirical analyses confirm that PGPO effectively reduces gradient variance, prevents training collapse, and acts as a potent regularizer for robust, perception-grounded multimodal reasoning. Code will be published on https://github.com/Yzk1114/PGPO.
Causal Tracing of Object Representations in Large Vision Language Models: Mechanistic Interpretability and Hallucination Mitigation
Nov 19, 2025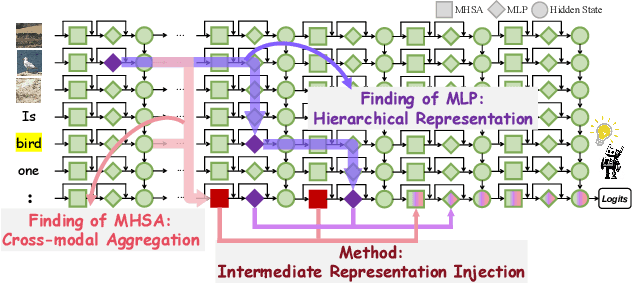

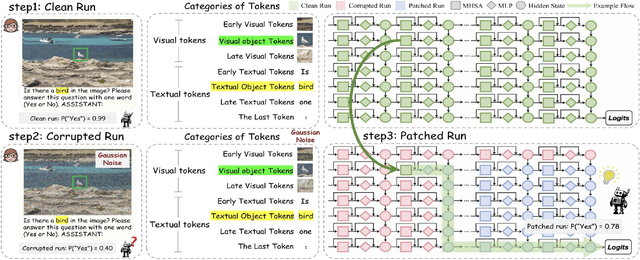
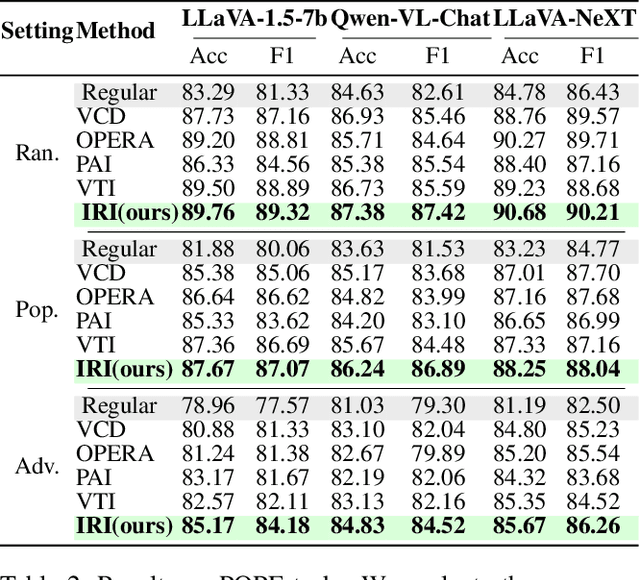
Despite the remarkable advancements of Large Vision-Language Models (LVLMs), the mechanistic interpretability remains underexplored. Existing analyses are insufficiently comprehensive and lack examination covering visual and textual tokens, model components, and the full range of layers. This limitation restricts actionable insights to improve the faithfulness of model output and the development of downstream tasks, such as hallucination mitigation. To address this limitation, we introduce Fine-grained Cross-modal Causal Tracing (FCCT) framework, which systematically quantifies the causal effects on visual object perception. FCCT conducts fine-grained analysis covering the full range of visual and textual tokens, three core model components including multi-head self-attention (MHSA), feed-forward networks (FFNs), and hidden states, across all decoder layers. Our analysis is the first to demonstrate that MHSAs of the last token in middle layers play a critical role in aggregating cross-modal information, while FFNs exhibit a three-stage hierarchical progression for the storage and transfer of visual object representations. Building on these insights, we propose Intermediate Representation Injection (IRI), a training-free inference-time technique that reinforces visual object information flow by precisely intervening on cross-modal representations at specific components and layers, thereby enhancing perception and mitigating hallucination. Consistent improvements across five widely used benchmarks and LVLMs demonstrate IRI achieves state-of-the-art performance, while preserving inference speed and other foundational performance.
GMFL-Net: A Global Multi-geometric Feature Learning Network for Repetitive Action Counting
Aug 31, 2024



With the continuous development of deep learning, the field of repetitive action counting is gradually gaining notice from many researchers. Extraction of pose keypoints using human pose estimation networks is proven to be an effective pose-level method. However, existing pose-level methods suffer from the shortcomings that the single coordinate is not stable enough to handle action distortions due to changes in camera viewpoints, thus failing to accurately identify salient poses, and is vulnerable to misdetection during the transition from the exception to the actual action. To overcome these problems, we propose a simple but efficient Global Multi-geometric Feature Learning Network (GMFL-Net). Specifically, we design a MIA-Module that aims to improve information representation by fusing multi-geometric features, and learning the semantic similarity among the input multi-geometric features. Then, to improve the feature representation from a global perspective, we also design a GBFL-Module that enhances the inter-dependencies between point-wise and channel-wise elements and combines them with the rich local information generated by the MIA-Module to synthesise a comprehensive and most representative global feature representation. In addition, considering the insufficient existing dataset, we collect a new dataset called Countix-Fitness-pose (https://github.com/Wantong66/Countix-Fitness) which contains different cycle lengths and exceptions, a test set with longer duration, and annotate it with fine-grained annotations at the pose-level. We also add two new action classes, namely lunge and rope push-down. Finally, extensive experiments on the challenging RepCount-pose, UCFRep-pose, and Countix-Fitness-pose benchmarks show that our proposed GMFL-Net achieves state-of-the-art performance.
Investigating and Mitigating the Multimodal Hallucination Snowballing in Large Vision-Language Models
Jun 30, 2024
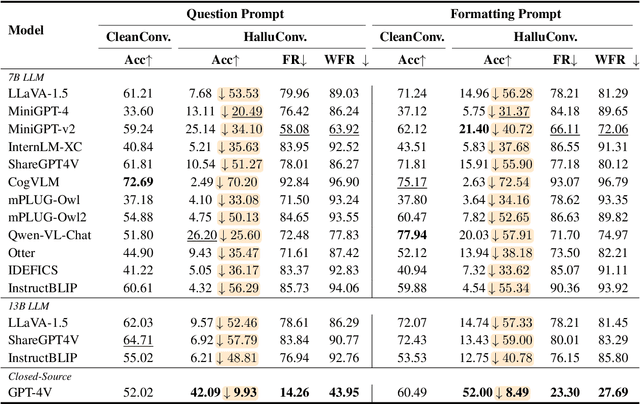
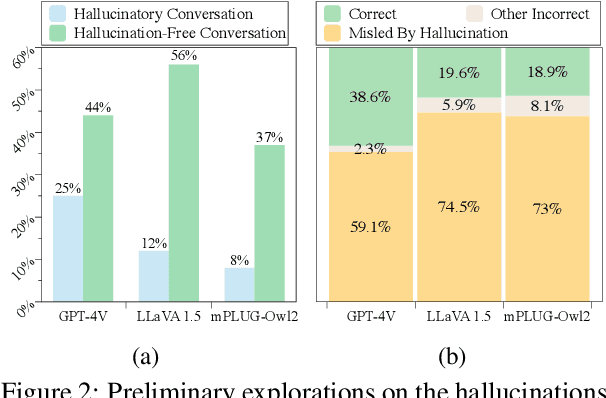
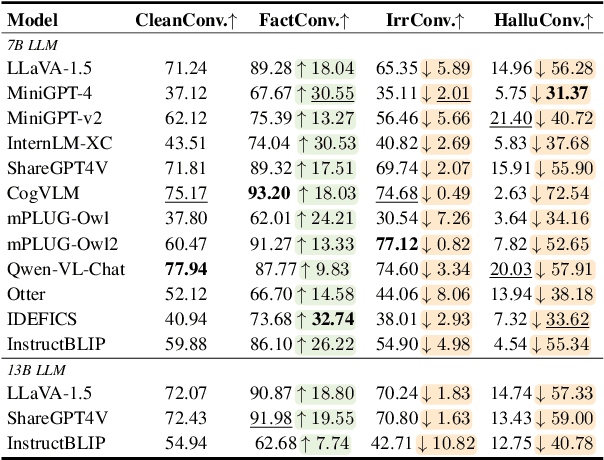
Though advanced in understanding visual information with human languages, Large Vision-Language Models (LVLMs) still suffer from multimodal hallucinations. A natural concern is that during multimodal interaction, the generated hallucinations could influence the LVLMs' subsequent generation. Thus, we raise a question: When presented with a query relevant to the previously generated hallucination, will LVLMs be misled and respond incorrectly, even though the ground visual information exists? To answer this, we propose a framework called MMHalSnowball to evaluate LVLMs' behaviors when encountering generated hallucinations, where LVLMs are required to answer specific visual questions within a curated hallucinatory conversation. Crucially, our experiment shows that the performance of open-source LVLMs drops by at least $31\%$, indicating that LVLMs are prone to accept the generated hallucinations and make false claims that they would not have supported without distractions. We term this phenomenon Multimodal Hallucination Snowballing. To mitigate this, we further propose a training-free method called Residual Visual Decoding, where we revise the output distribution of LVLMs with the one derived from the residual visual input, providing models with direct access to the visual information. Experiments show that our method can mitigate more than $24\%$ of the snowballed multimodal hallucination while maintaining capabilities.