 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGazeVLA: Learning Human Intention for Robotic Manipulation
Apr 24, 2026Embodied foundation models have achieved significant breakthroughs in robotic manipulation, yet they still depend heavily on large-scale robot demonstrations. Although recent works have explored leveraging human data to alleviate this dependency, effectively extracting transferable knowledge remains a significant challenge due to the inherent embodiment gap between human and robot. We argue that the intention underlying human actions can serve as a powerful intermediate representation for bridging this gap. In this paper, we introduce a novel framework that explicitly learns and transfers human intention to facilitate robotic manipulation. Specifically, we model intention through gaze, as it naturally precedes physical actions and serves as an observable proxy for human intent. Our model is first pretrained on a large-scale egocentric human dataset to capture human intention and its synergy with action, followed by finetuning on a small set of robot and human data. During inference, the model adopts a Chain-of-Thought reasoning paradigm, sequentially predicting intention before executing the action. Extensive evaluations in simulation and real-world settings, across long-horizon and fine-grained tasks, and under few-shot and robustness benchmarks, show that our method consistently outperforms strong baselines, generalizes better, and achieves state-of-the-art performance.
EgoSelf: From Memory to Personalized Egocentric Assistant
Apr 22, 2026Egocentric assistants often rely on first-person view data to capture user behavior and context for personalized services. Since different users exhibit distinct habits, preferences, and routines, such personalization is essential for truly effective assistance. However, effectively integrating long-term user data for personalization remains a key challenge. To address this, we introduce EgoSelf, a system that includes a graph-based interaction memory constructed from past observations and a dedicated learning task for personalization. The memory captures temporal and semantic relationships among interaction events and entities, from which user-specific profiles are derived. The personalized learning task is formulated as a prediction problem where the model predicts possible future interactions from individual user's historical behavior recorded in the graph. Extensive experiments demonstrate the effectiveness of EgoSelf as a personalized egocentric assistant. Code is available at https://abie-e.github.io/EgoSelf/.
Adaptor: Advancing Assistive Teleoperation with Few-Shot Learning and Cross-Operator Generalization
Apr 10, 2026Assistive teleoperation enhances efficiency via shared control, yet inter-operator variability, stemming from diverse habits and expertise, induces highly heterogeneous trajectory distributions that undermine intent recognition stability. We present Adaptor, a few-shot framework for robust cross-operator intent recognition. The Adaptor bridges the domain gap through two stages: (i) preprocessing, which models intent uncertainty by synthesizing trajectory perturbations via noise injection and performs geometry-aware keyframe extraction; and (ii) policy learning, which encodes the processed trajectories with an Intention Expert and fuses them with the pre-trained vision-language model context to condition an Action Expert for action generation. Experiments on real-world and simulated benchmarks demonstrate that Adaptor achieves state-of-the-art performance, improving success rates and efficiency over baselines. Moreover, the method exhibits low variance across operators with varying expertise, demonstrating robust cross-operator generalization.
Multi-View Video Diffusion Policy: A 3D Spatio-Temporal-Aware Video Action Model
Apr 03, 2026Robotic manipulation requires understanding both the 3D spatial structure of the environment and its temporal evolution, yet most existing policies overlook one or both. They typically rely on 2D visual observations and backbones pretrained on static image--text pairs, resulting in high data requirements and limited understanding of environment dynamics. To address this, we introduce MV-VDP, a multi-view video diffusion policy that jointly models the 3D spatio-temporal state of the environment. The core idea is to simultaneously predict multi-view heatmap videos and RGB videos, which 1) align the representation format of video pretraining with action finetuning, and 2) specify not only what actions the robot should take, but also how the environment is expected to evolve in response to those actions. Extensive experiments show that MV-VDP enables data-efficient, robust, generalizable, and interpretable manipulation. With only ten demonstration trajectories and without additional pretraining, MV-VDP successfully performs complex real-world tasks, demonstrates strong robustness across a range of model hyperparameters, generalizes to out-of-distribution settings, and predicts realistic future videos. Experiments on Meta-World and real-world robotic platforms demonstrate that MV-VDP consistently outperforms video-prediction--based, 3D-based, and vision--language--action models, establishing a new state of the art in data-efficient multi-task manipulation.
RAGPerf: An End-to-End Benchmarking Framework for Retrieval-Augmented Generation Systems
Mar 11, 2026We present the design and implementation of a RAG-based AI system benchmarking (RAGPerf) framework for characterizing the system behaviors of RAG pipelines. To facilitate detailed profiling and fine-grained performance analysis, RAGPerf decouples the RAG workflow into several modular components - embedding, indexing, retrieval, reranking, and generation. RAGPerf offers the flexibility for users to configure the core parameters of each component and examine their impact on the end-to-end query performance and quality. RAGPerf has a workload generator to model real-world scenarios by supporting diverse datasets (e.g., text, pdf, code, and audio), different retrieval and update ratios, and query distributions. RAGPerf also supports different embedding models, major vector databases such as LanceDB, Milvus, Qdrant, Chroma, and Elasticsearch, as well as different LLMs for content generation. It automates the collection of performance metrics (i.e., end-to-end query throughput, host/GPU memory footprint, and CPU/GPU utilization) and accuracy metrics (i.e., context recall, query accuracy, and factual consistency). We demonstrate the capabilities of RAGPerf through a comprehensive set of experiments and open source its codebase at GitHub. Our evaluation shows that RAGPerf incurs negligible performance overhead.
How Do We Research Human-Robot Interaction in the Age of Large Language Models? A Systematic Review
Feb 13, 2026Advances in large language models (LLMs) are profoundly reshaping the field of human-robot interaction (HRI). While prior work has highlighted the technical potential of LLMs, few studies have systematically examined their human-centered impact (e.g., human-oriented understanding, user modeling, and levels of autonomy), making it difficult to consolidate emerging challenges in LLM-driven HRI systems. Therefore, we conducted a systematic literature search following the PRISMA guideline, identifying 86 articles that met our inclusion criteria. Our findings reveal that: (1) LLMs are transforming the fundamentals of HRI by reshaping how robots sense context, generate socially grounded interactions, and maintain continuous alignment with human needs in embodied settings; and (2) current research is largely exploratory, with different studies focusing on different facets of LLM-driven HRI, resulting in wide-ranging choices of experimental setups, study methods, and evaluation metrics. Finally, we identify key design considerations and challenges, offering a coherent overview and guidelines for future research at the intersection of LLMs and HRI.
BridgeV2W: Bridging Video Generation Models to Embodied World Models via Embodiment Masks
Feb 03, 2026Embodied world models have emerged as a promising paradigm in robotics, most of which leverage large-scale Internet videos or pretrained video generation models to enrich visual and motion priors. However, they still face key challenges: a misalignment between coordinate-space actions and pixel-space videos, sensitivity to camera viewpoint, and non-unified architectures across embodiments. To this end, we present BridgeV2W, which converts coordinate-space actions into pixel-aligned embodiment masks rendered from the URDF and camera parameters. These masks are then injected into a pretrained video generation model via a ControlNet-style pathway, which aligns the action control signals with predicted videos, adds view-specific conditioning to accommodate camera viewpoints, and yields a unified world model architecture across embodiments. To mitigate overfitting to static backgrounds, BridgeV2W further introduces a flow-based motion loss that focuses on learning dynamic and task-relevant regions. Experiments on single-arm (DROID) and dual-arm (AgiBot-G1) datasets, covering diverse and challenging conditions with unseen viewpoints and scenes, show that BridgeV2W improves video generation quality compared to prior state-of-the-art methods. We further demonstrate the potential of BridgeV2W on downstream real-world tasks, including policy evaluation and goal-conditioned planning. More results can be found on our project website at https://BridgeV2W.github.io .
One Size, Many Fits: Aligning Diverse Group-Wise Click Preferences in Large-Scale Advertising Image Generation
Feb 02, 2026Advertising image generation has increasingly focused on online metrics like Click-Through Rate (CTR), yet existing approaches adopt a ``one-size-fits-all" strategy that optimizes for overall CTR while neglecting preference diversity among user groups. This leads to suboptimal performance for specific groups, limiting targeted marketing effectiveness. To bridge this gap, we present \textit{One Size, Many Fits} (OSMF), a unified framework that aligns diverse group-wise click preferences in large-scale advertising image generation. OSMF begins with product-aware adaptive grouping, which dynamically organizes users based on their attributes and product characteristics, representing each group with rich collective preference features. Building on these groups, preference-conditioned image generation employs a Group-aware Multimodal Large Language Model (G-MLLM) to generate tailored images for each group. The G-MLLM is pre-trained to simultaneously comprehend group features and generate advertising images. Subsequently, we fine-tune the G-MLLM using our proposed Group-DPO for group-wise preference alignment, which effectively enhances each group's CTR on the generated images. To further advance this field, we introduce the Grouped Advertising Image Preference Dataset (GAIP), the first large-scale public dataset of group-wise image preferences, including around 600K groups built from 40M users. Extensive experiments demonstrate that our framework achieves the state-of-the-art performance in both offline and online settings. Our code and datasets will be released at https://github.com/JD-GenX/OSMF.
FrontierCS: Evolving Challenges for Evolving Intelligence
Dec 17, 2025



We introduce FrontierCS, a benchmark of 156 open-ended problems across diverse areas of computer science, designed and reviewed by experts, including CS PhDs and top-tier competitive programming participants and problem setters. Unlike existing benchmarks that focus on tasks with known optimal solutions, FrontierCS targets problems where the optimal solution is unknown, but the quality of a solution can be objectively evaluated. Models solve these tasks by implementing executable programs rather than outputting a direct answer. FrontierCS includes algorithmic problems, which are often NP-hard variants of competitive programming problems with objective partial scoring, and research problems with the same property. For each problem we provide an expert reference solution and an automatic evaluator. Combining open-ended design, measurable progress, and expert curation, FrontierCS provides a benchmark at the frontier of computer-science difficulty. Empirically, we find that frontier reasoning models still lag far behind human experts on both the algorithmic and research tracks, that increasing reasoning budgets alone does not close this gap, and that models often over-optimize for generating merely workable code instead of discovering high-quality algorithms and system designs.
EgoDemoGen: Novel Egocentric Demonstration Generation Enables Viewpoint-Robust Manipulation
Sep 26, 2025


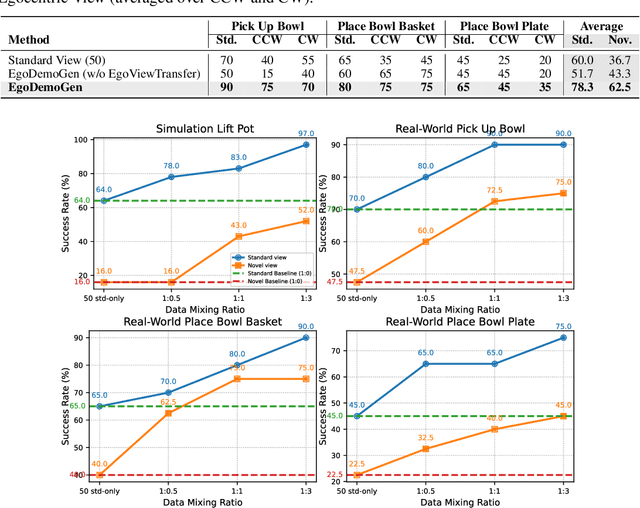
Imitation learning based policies perform well in robotic manipulation, but they often degrade under *egocentric viewpoint shifts* when trained from a single egocentric viewpoint. To address this issue, we present **EgoDemoGen**, a framework that generates *paired* novel egocentric demonstrations by retargeting actions in the novel egocentric frame and synthesizing the corresponding egocentric observation videos with proposed generative video repair model **EgoViewTransfer**, which is conditioned by a novel-viewpoint reprojected scene video and a robot-only video rendered from the retargeted joint actions. EgoViewTransfer is finetuned from a pretrained video generation model using self-supervised double reprojection strategy. We evaluate EgoDemoGen on both simulation (RoboTwin2.0) and real-world robot. After training with a mixture of EgoDemoGen-generated novel egocentric demonstrations and original standard egocentric demonstrations, policy success rate improves **absolutely** by **+17.0%** for standard egocentric viewpoint and by **+17.7%** for novel egocentric viewpoints in simulation. On real-world robot, the **absolute** improvements are **+18.3%** and **+25.8%**. Moreover, performance continues to improve as the proportion of EgoDemoGen-generated demonstrations increases, with diminishing returns. These results demonstrate that EgoDemoGen provides a practical route to egocentric viewpoint-robust robotic manipulation.