 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogics-STEM: Empowering LLM Reasoning via Failure-Driven Post-Training and Document Knowledge Enhancement
Jan 08, 2026We present Logics-STEM, a state-of-the-art reasoning model fine-tuned on Logics-STEM-SFT-Dataset, a high-quality and diverse dataset at 10M scale that represents one of the largest-scale open-source long chain-of-thought corpora. Logics-STEM targets reasoning tasks in the domains of Science, Technology, Engineering, and Mathematics (STEM), and exhibits exceptional performance on STEM-related benchmarks with an average improvement of 4.68% over the next-best model at 8B scale. We attribute the gains to our data-algorithm co-design engine, where they are jointly optimized to fit a gold-standard distribution behind reasoning. Data-wise, the Logics-STEM-SFT-Dataset is constructed from a meticulously designed data curation engine with 5 stages to ensure the quality, diversity, and scalability, including annotation, deduplication, decontamination, distillation, and stratified sampling. Algorithm-wise, our failure-driven post-training framework leverages targeted knowledge retrieval and data synthesis around model failure regions in the Supervised Fine-tuning (SFT) stage to effectively guide the second-stage SFT or the reinforcement learning (RL) for better fitting the target distribution. The superior empirical performance of Logics-STEM reveals the vast potential of combining large-scale open-source data with carefully designed synthetic data, underscoring the critical role of data-algorithm co-design in enhancing reasoning capabilities through post-training. We make both the Logics-STEM models (8B and 32B) and the Logics-STEM-SFT-Dataset (10M and downsampled 2.2M versions) publicly available to support future research in the open-source community.
SURGEON: Memory-Adaptive Fully Test-Time Adaptation via Dynamic Activation Sparsity
Mar 26, 2025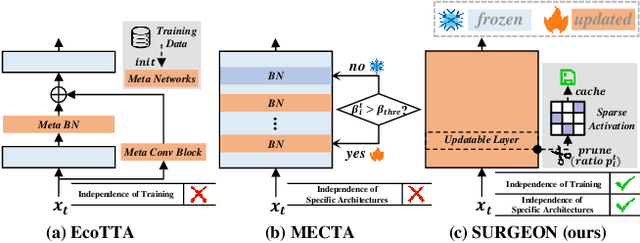
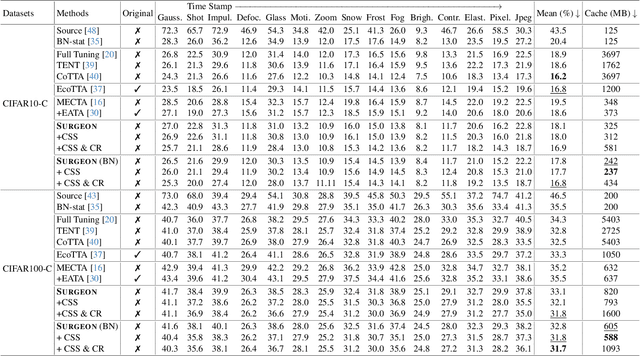
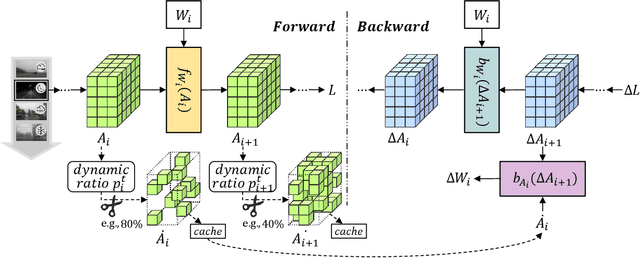
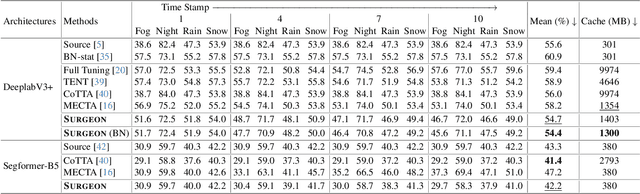
Despite the growing integration of deep models into mobile terminals, the accuracy of these models declines significantly due to various deployment interferences. Test-time adaptation (TTA) has emerged to improve the performance of deep models by adapting them to unlabeled target data online. Yet, the significant memory cost, particularly in resource-constrained terminals, impedes the effective deployment of most backward-propagation-based TTA methods. To tackle memory constraints, we introduce SURGEON, a method that substantially reduces memory cost while preserving comparable accuracy improvements during fully test-time adaptation (FTTA) without relying on specific network architectures or modifications to the original training procedure. Specifically, we propose a novel dynamic activation sparsity strategy that directly prunes activations at layer-specific dynamic ratios during adaptation, allowing for flexible control of learning ability and memory cost in a data-sensitive manner. Among this, two metrics, Gradient Importance and Layer Activation Memory, are considered to determine the layer-wise pruning ratios, reflecting accuracy contribution and memory efficiency, respectively. Experimentally, our method surpasses the baselines by not only reducing memory usage but also achieving superior accuracy, delivering SOTA performance across diverse datasets, architectures, and tasks.
CrowdHMTware: A Cross-level Co-adaptation Middleware for Context-aware Mobile DL Deployment
Mar 06, 2025There are many deep learning (DL) powered mobile and wearable applications today continuously and unobtrusively sensing the ambient surroundings to enhance all aspects of human lives.To enable robust and private mobile sensing, DL models are often deployed locally on resource-constrained mobile devices using techniques such as model compression or offloading.However, existing methods, either front-end algorithm level (i.e. DL model compression/partitioning) or back-end scheduling level (i.e. operator/resource scheduling), cannot be locally online because they require offline retraining to ensure accuracy or rely on manually pre-defined strategies, struggle with dynamic adaptability.The primary challenge lies in feeding back runtime performance from the back-end level to the front-end level optimization decision. Moreover, the adaptive mobile DL model porting middleware with cross-level co-adaptation is less explored, particularly in mobile environments with diversity and dynamics. In response, we introduce CrowdHMTware, a dynamic context-adaptive DL model deployment middleware for heterogeneous mobile devices. It establishes an automated adaptation loop between cross-level functional components, i.e. elastic inference, scalable offloading, and model-adaptive engine, enhancing scalability and adaptability. Experiments with four typical tasks across 15 platforms and a real-world case study demonstrate that CrowdHMTware can effectively scale DL model, offloading, and engine actions across diverse platforms and tasks. It hides run-time system issues from developers, reducing the required developer expertise.
RESIST: Resilient Decentralized Learning Using Consensus Gradient Descent
Feb 11, 2025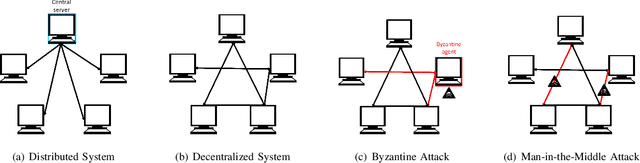
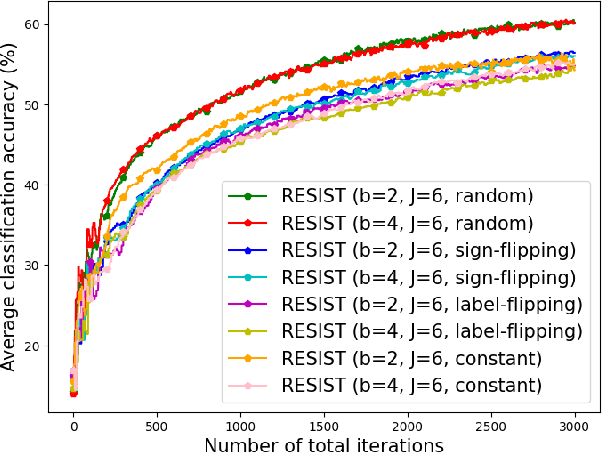
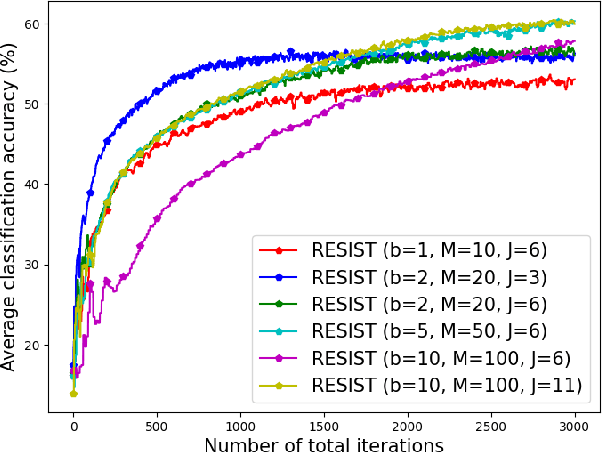
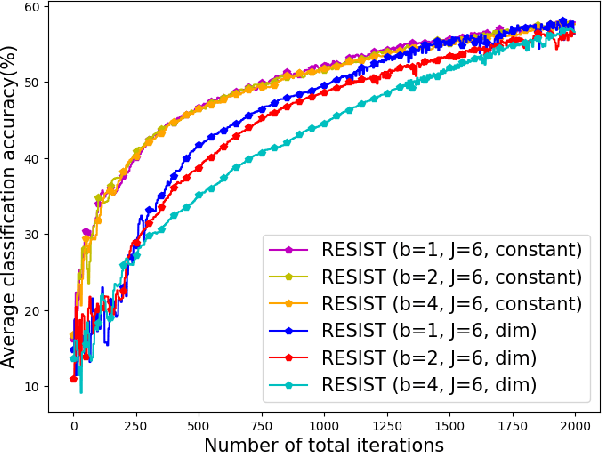
Empirical risk minimization (ERM) is a cornerstone of modern machine learning (ML), supported by advances in optimization theory that ensure efficient solutions with provable algorithmic convergence rates, which measure the speed at which optimization algorithms approach a solution, and statistical learning rates, which characterize how well the solution generalizes to unseen data. Privacy, memory, computational, and communications constraints increasingly necessitate data collection, processing, and storage across network-connected devices. In many applications, these networks operate in decentralized settings where a central server cannot be assumed, requiring decentralized ML algorithms that are both efficient and resilient. Decentralized learning, however, faces significant challenges, including an increased attack surface for adversarial interference during decentralized learning processes. This paper focuses on the man-in-the-middle (MITM) attack, which can cause models to deviate significantly from their intended ERM solutions. To address this challenge, we propose RESIST (Resilient dEcentralized learning using conSensus gradIent deScenT), an optimization algorithm designed to be robust against adversarially compromised communication links. RESIST achieves algorithmic and statistical convergence for strongly convex, Polyak-Lojasiewicz, and nonconvex ERM problems. Experimental results demonstrate the robustness and scalability of RESIST for real-world decentralized learning in adversarial environments.
AdaShadow: Responsive Test-time Model Adaptation in Non-stationary Mobile Environments
Oct 10, 2024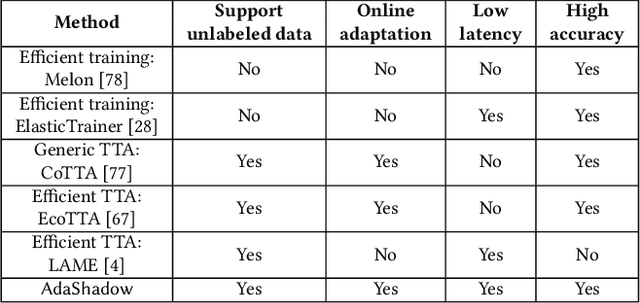
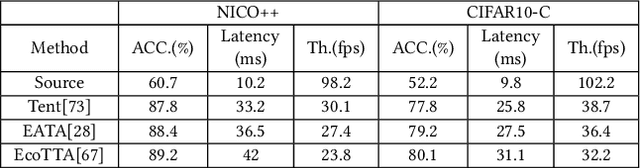
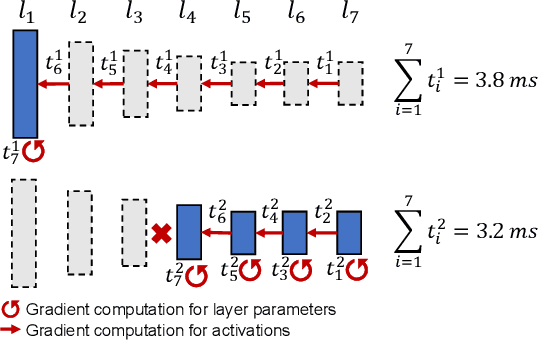
On-device adapting to continual, unpredictable domain shifts is essential for mobile applications like autonomous driving and augmented reality to deliver seamless user experiences in evolving environments. Test-time adaptation (TTA) emerges as a promising solution by tuning model parameters with unlabeled live data immediately before prediction. However, TTA's unique forward-backward-reforward pipeline notably increases the latency over standard inference, undermining the responsiveness in time-sensitive mobile applications. This paper presents AdaShadow, a responsive test-time adaptation framework for non-stationary mobile data distribution and resource dynamics via selective updates of adaptation-critical layers. Although the tactic is recognized in generic on-device training, TTA's unsupervised and online context presents unique challenges in estimating layer importance and latency, as well as scheduling the optimal layer update plan. AdaShadow addresses these challenges with a backpropagation-free assessor to rapidly identify critical layers, a unit-based runtime predictor to account for resource dynamics in latency estimation, and an online scheduler for prompt layer update planning. Also, AdaShadow incorporates a memory I/O-aware computation reuse scheme to further reduce latency in the reforward pass. Results show that AdaShadow achieves the best accuracy-latency balance under continual shifts. At low memory and energy costs, Adashadow provides a 2x to 3.5x speedup (ms-level) over state-of-the-art TTA methods with comparable accuracy and a 14.8% to 25.4% accuracy boost over efficient supervised methods with similar latency.
* This paper is accepted by SenSys 2024. Copyright may be transferred without notice
Hawk: Learning to Understand Open-World Video Anomalies
May 27, 2024



Video Anomaly Detection (VAD) systems can autonomously monitor and identify disturbances, reducing the need for manual labor and associated costs. However, current VAD systems are often limited by their superficial semantic understanding of scenes and minimal user interaction. Additionally, the prevalent data scarcity in existing datasets restricts their applicability in open-world scenarios. In this paper, we introduce Hawk, a novel framework that leverages interactive large Visual Language Models (VLM) to interpret video anomalies precisely. Recognizing the difference in motion information between abnormal and normal videos, Hawk explicitly integrates motion modality to enhance anomaly identification. To reinforce motion attention, we construct an auxiliary consistency loss within the motion and video space, guiding the video branch to focus on the motion modality. Moreover, to improve the interpretation of motion-to-language, we establish a clear supervisory relationship between motion and its linguistic representation. Furthermore, we have annotated over 8,000 anomaly videos with language descriptions, enabling effective training across diverse open-world scenarios, and also created 8,000 question-answering pairs for users' open-world questions. The final results demonstrate that Hawk achieves SOTA performance, surpassing existing baselines in both video description generation and question-answering. Our codes/dataset/demo will be released at https://github.com/jqtangust/hawk.
Deep Learning Inference on Heterogeneous Mobile Processors: Potentials and Pitfalls
May 03, 2024



There is a growing demand to deploy computation-intensive deep learning (DL) models on resource-constrained mobile devices for real-time intelligent applications. Equipped with a variety of processing units such as CPUs, GPUs, and NPUs, the mobile devices hold potential to accelerate DL inference via parallel execution across heterogeneous processors. Various efficient parallel methods have been explored to optimize computation distribution, achieve load balance, and minimize communication cost across processors. Yet their practical effectiveness in the dynamic and diverse real-world mobile environment is less explored. This paper presents a holistic empirical study to assess the capabilities and challenges associated with parallel DL inference on heterogeneous mobile processors. Through carefully designed experiments covering various DL models, mobile software/hardware environments, workload patterns, and resource availability, we identify limitations of existing techniques and highlight opportunities for cross-level optimization.
Stochastic parameter reduced-order model based on hybrid machine learning approaches
Mar 24, 2024
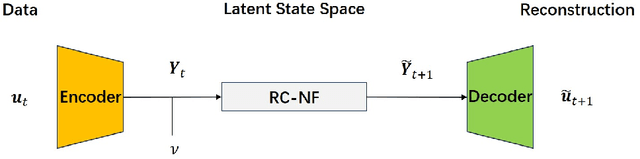

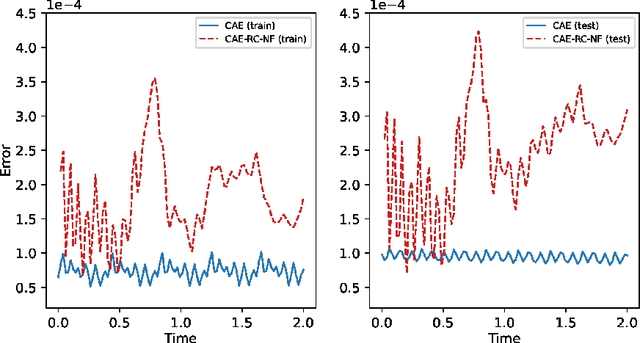
Establishing appropriate mathematical models for complex systems in natural phenomena not only helps deepen our understanding of nature but can also be used for state estimation and prediction. However, the extreme complexity of natural phenomena makes it extremely challenging to develop full-order models (FOMs) and apply them to studying many quantities of interest. In contrast, appropriate reduced-order models (ROMs) are favored due to their high computational efficiency and ability to describe the key dynamics and statistical characteristics of natural phenomena. Taking the viscous Burgers equation as an example, this paper constructs a Convolutional Autoencoder-Reservoir Computing-Normalizing Flow algorithm framework, where the Convolutional Autoencoder is used to construct latent space representations, and the Reservoir Computing-Normalizing Flow framework is used to characterize the evolution of latent state variables. In this way, a data-driven stochastic parameter reduced-order model is constructed to describe the complex system and its dynamic behavior.
A Fingertip Sensor and Algorithms for Pre-touch Distance Ranging and Material Detection in Robotic Grasping
Nov 17, 2023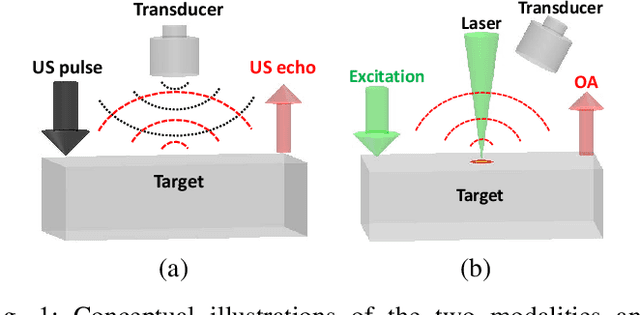
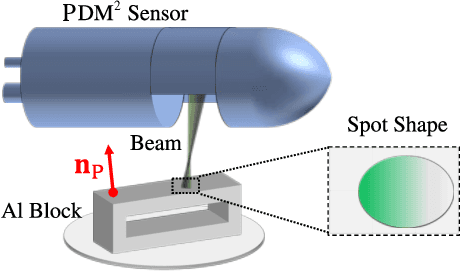
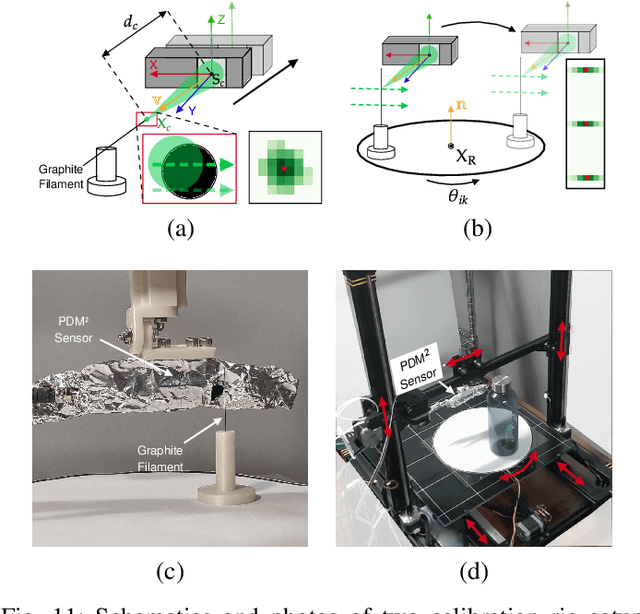
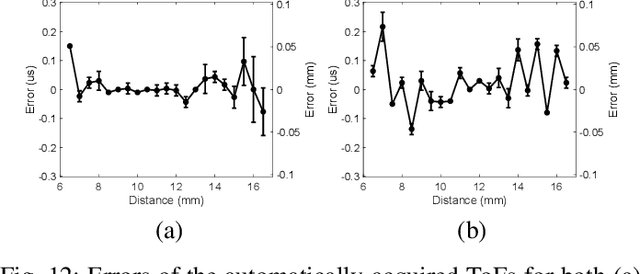
To enhance robotic grasping capabilities, we are developing new contactless fingertip sensors to measure distance in close proximity and simultaneously detect the type of material and the interior structure. These sensors are referred to as pre-touch dual-modal and dual-mechanism (PDM$^2$) sensors, and they operate using both pulse-echo ultrasound (US) and optoacoustic (OA) modalities. We present the design of a PDM$^2$ sensor that utilizes a pulsed laser beam and a customized ultrasound transceiver with a wide acoustic bandwidth for ranging and sensing. Both US and OA signals are collected simultaneously, triggered by the same laser pulse. To validate our design, we have fabricated a prototype of the PDM$^2$ sensor and integrated it into an object scanning system. We have also developed algorithms to enable the sensor, including time-of-flight (ToF) auto estimation, ranging rectification, sensor and system calibration, distance ranging, material/structure detection, and object contour detection and reconstruction. The experimental results demonstrate that the new PDM$^2$ sensor and its algorithms effectively enable the object scanning system to achieve satisfactory ranging and contour reconstruction performances, along with satisfying material/structure detection capabilities. In conclusion, the PDM$^2$ sensor offers a practical and powerful solution to improve grasping of unknown objects with the robotic gripper by providing advanced perception capabilities.
Dual Radar: A Multi-modal Dataset with Dual 4D Radar for Autonomous Driving
Oct 23, 2023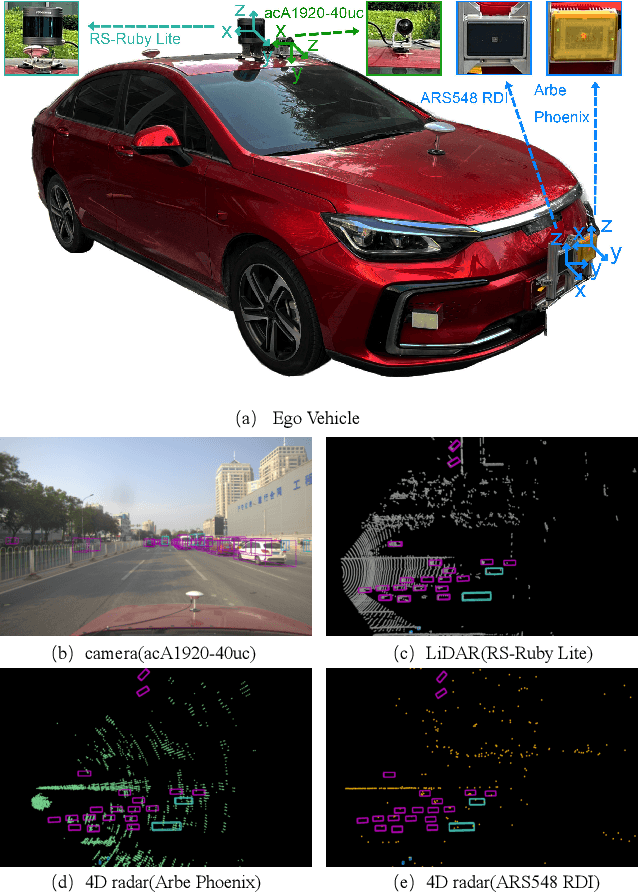
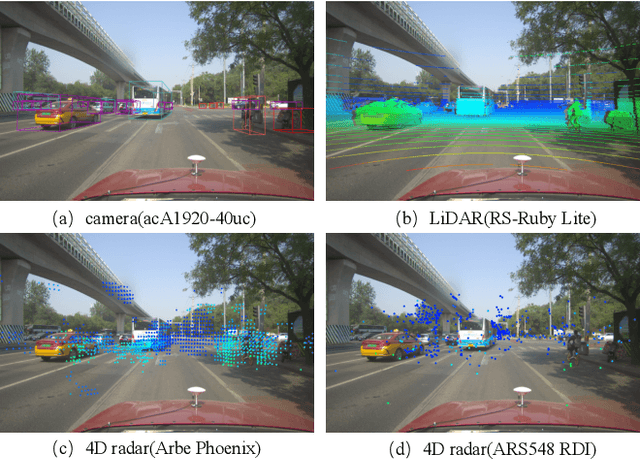
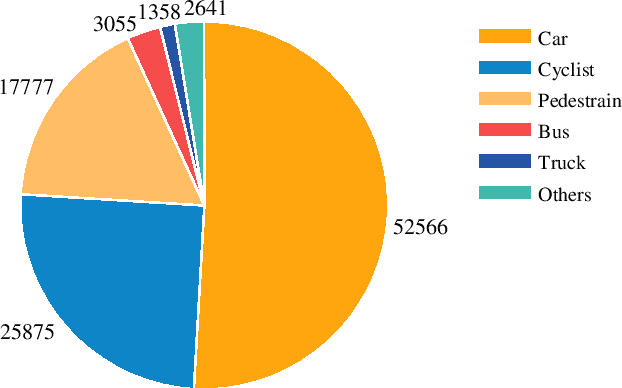
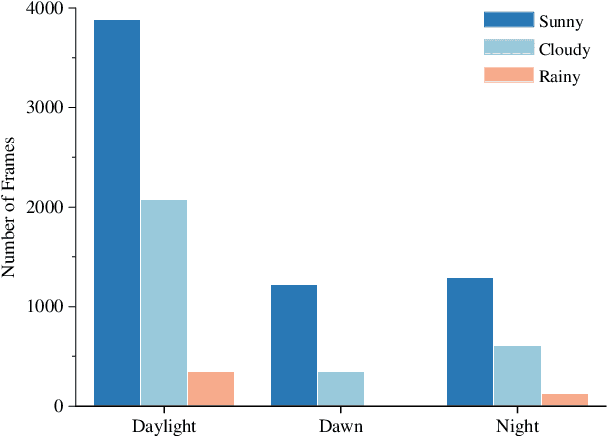
Radar has stronger adaptability in adverse scenarios for autonomous driving environmental perception compared to widely adopted cameras and LiDARs. Compared with commonly used 3D radars, the latest 4D radars have precise vertical resolution and higher point cloud density, making it a highly promising sensor for autonomous driving in complex environmental perception. However, due to the much higher noise than LiDAR, manufacturers choose different filtering strategies, resulting in an inverse ratio between noise level and point cloud density. There is still a lack of comparative analysis on which method is beneficial for deep learning-based perception algorithms in autonomous driving. One of the main reasons is that current datasets only adopt one type of 4D radar, making it difficult to compare different 4D radars in the same scene. Therefore, in this paper, we introduce a novel large-scale multi-modal dataset featuring, for the first time, two types of 4D radars captured simultaneously. This dataset enables further research into effective 4D radar perception algorithms.Our dataset consists of 151 consecutive series, most of which last 20 seconds and contain 10,007 meticulously synchronized and annotated frames. Moreover, our dataset captures a variety of challenging driving scenarios, including many road conditions, weather conditions, nighttime and daytime with different lighting intensities and periods. Our dataset annotates consecutive frames, which can be applied to 3D object detection and tracking, and also supports the study of multi-modal tasks. We experimentally validate our dataset, providing valuable results for studying different types of 4D radars. This dataset is released on https://github.com/adept-thu/Dual-Radar.