 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShortCoder: Knowledge-Augmented Syntax Optimization for Token-Efficient Code Generation
Jan 14, 2026Code generation tasks aim to automate the conversion of user requirements into executable code, significantly reducing manual development efforts and enhancing software productivity. The emergence of large language models (LLMs) has significantly advanced code generation, though their efficiency is still impacted by certain inherent architectural constraints. Each token generation necessitates a complete inference pass, requiring persistent retention of contextual information in memory and escalating resource consumption. While existing research prioritizes inference-phase optimizations such as prompt compression and model quantization, the generation phase remains underexplored. To tackle these challenges, we propose a knowledge-infused framework named ShortCoder, which optimizes code generation efficiency while preserving semantic equivalence and readability. In particular, we introduce: (1) ten syntax-level simplification rules for Python, derived from AST-preserving transformations, achieving 18.1% token reduction without functional compromise; (2) a hybrid data synthesis pipeline integrating rule-based rewriting with LLM-guided refinement, producing ShorterCodeBench, a corpus of validated tuples of original code and simplified code with semantic consistency; (3) a fine-tuning strategy that injects conciseness awareness into the base LLMs. Extensive experimental results demonstrate that ShortCoder consistently outperforms state-of-the-art methods on HumanEval, achieving an improvement of 18.1%-37.8% in generation efficiency over previous methods while ensuring the performance of code generation.
Hunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
HunyuanWorld 1.0: Generating Immersive, Explorable, and Interactive 3D Worlds from Words or Pixels
Jul 29, 2025



Creating immersive and playable 3D worlds from texts or images remains a fundamental challenge in computer vision and graphics. Existing world generation approaches typically fall into two categories: video-based methods that offer rich diversity but lack 3D consistency and rendering efficiency, and 3D-based methods that provide geometric consistency but struggle with limited training data and memory-inefficient representations. To address these limitations, we present HunyuanWorld 1.0, a novel framework that combines the best of both worlds for generating immersive, explorable, and interactive 3D scenes from text and image conditions. Our approach features three key advantages: 1) 360{\deg} immersive experiences via panoramic world proxies; 2) mesh export capabilities for seamless compatibility with existing computer graphics pipelines; 3) disentangled object representations for augmented interactivity. The core of our framework is a semantically layered 3D mesh representation that leverages panoramic images as 360{\deg} world proxies for semantic-aware world decomposition and reconstruction, enabling the generation of diverse 3D worlds. Extensive experiments demonstrate that our method achieves state-of-the-art performance in generating coherent, explorable, and interactive 3D worlds while enabling versatile applications in virtual reality, physical simulation, game development, and interactive content creation.
Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material
Jun 18, 20253D AI-generated content (AIGC) is a passionate field that has significantly accelerated the creation of 3D models in gaming, film, and design. Despite the development of several groundbreaking models that have revolutionized 3D generation, the field remains largely accessible only to researchers, developers, and designers due to the complexities involved in collecting, processing, and training 3D models. To address these challenges, we introduce Hunyuan3D 2.1 as a case study in this tutorial. This tutorial offers a comprehensive, step-by-step guide on processing 3D data, training a 3D generative model, and evaluating its performance using Hunyuan3D 2.1, an advanced system for producing high-resolution, textured 3D assets. The system comprises two core components: the Hunyuan3D-DiT for shape generation and the Hunyuan3D-Paint for texture synthesis. We will explore the entire workflow, including data preparation, model architecture, training strategies, evaluation metrics, and deployment. By the conclusion of this tutorial, you will have the knowledge to finetune or develop a robust 3D generative model suitable for applications in gaming, virtual reality, and industrial design.
Learning Generalizable Skills from Offline Multi-Task Data for Multi-Agent Cooperation
Mar 27, 2025Learning cooperative multi-agent policy from offline multi-task data that can generalize to unseen tasks with varying numbers of agents and targets is an attractive problem in many scenarios. Although aggregating general behavior patterns among multiple tasks as skills to improve policy transfer is a promising approach, two primary challenges hinder the further advancement of skill learning in offline multi-task MARL. Firstly, extracting general cooperative behaviors from various action sequences as common skills lacks bringing cooperative temporal knowledge into them. Secondly, existing works only involve common skills and can not adaptively choose independent knowledge as task-specific skills in each task for fine-grained action execution. To tackle these challenges, we propose Hierarchical and Separate Skill Discovery (HiSSD), a novel approach for generalizable offline multi-task MARL through skill learning. HiSSD leverages a hierarchical framework that jointly learns common and task-specific skills. The common skills learn cooperative temporal knowledge and enable in-sample exploitation for offline multi-task MARL. The task-specific skills represent the priors of each task and achieve a task-guided fine-grained action execution. To verify the advancement of our method, we conduct experiments on multi-agent MuJoCo and SMAC benchmarks. After training the policy using HiSSD on offline multi-task data, the empirical results show that HiSSD assigns effective cooperative behaviors and obtains superior performance in unseen tasks.
SURGEON: Memory-Adaptive Fully Test-Time Adaptation via Dynamic Activation Sparsity
Mar 26, 2025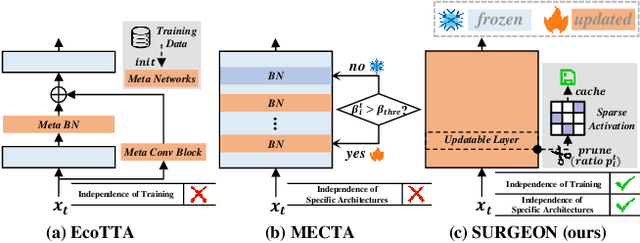
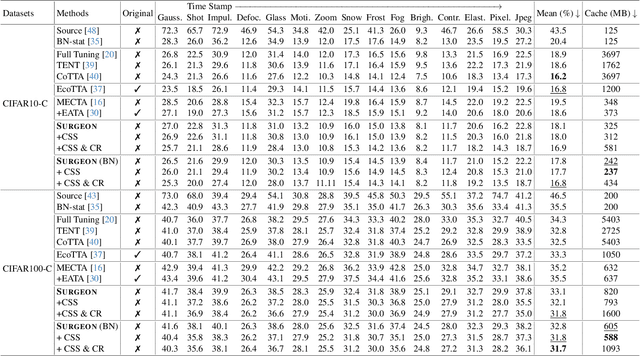
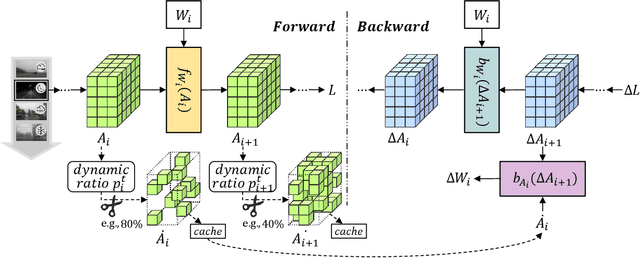
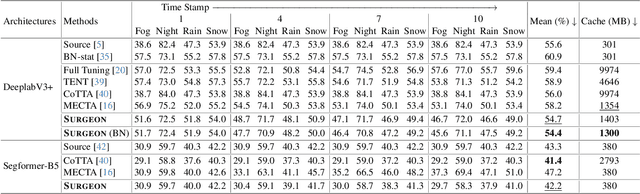
Despite the growing integration of deep models into mobile terminals, the accuracy of these models declines significantly due to various deployment interferences. Test-time adaptation (TTA) has emerged to improve the performance of deep models by adapting them to unlabeled target data online. Yet, the significant memory cost, particularly in resource-constrained terminals, impedes the effective deployment of most backward-propagation-based TTA methods. To tackle memory constraints, we introduce SURGEON, a method that substantially reduces memory cost while preserving comparable accuracy improvements during fully test-time adaptation (FTTA) without relying on specific network architectures or modifications to the original training procedure. Specifically, we propose a novel dynamic activation sparsity strategy that directly prunes activations at layer-specific dynamic ratios during adaptation, allowing for flexible control of learning ability and memory cost in a data-sensitive manner. Among this, two metrics, Gradient Importance and Layer Activation Memory, are considered to determine the layer-wise pruning ratios, reflecting accuracy contribution and memory efficiency, respectively. Experimentally, our method surpasses the baselines by not only reducing memory usage but also achieving superior accuracy, delivering SOTA performance across diverse datasets, architectures, and tasks.
RALLRec+: Retrieval Augmented Large Language Model Recommendation with Reasoning
Mar 26, 2025



Large Language Models (LLMs) have been integrated into recommender systems to enhance user behavior comprehension. The Retrieval Augmented Generation (RAG) technique is further incorporated into these systems to retrieve more relevant items and improve system performance. However, existing RAG methods have two shortcomings. \textit{(i)} In the \textit{retrieval} stage, they rely primarily on textual semantics and often fail to incorporate the most relevant items, thus constraining system effectiveness. \textit{(ii)} In the \textit{generation} stage, they lack explicit chain-of-thought reasoning, further limiting their potential. In this paper, we propose Representation learning and \textbf{R}easoning empowered retrieval-\textbf{A}ugmented \textbf{L}arge \textbf{L}anguage model \textbf{Rec}ommendation (RALLRec+). Specifically, for the retrieval stage, we prompt LLMs to generate detailed item descriptions and perform joint representation learning, combining textual and collaborative signals extracted from the LLM and recommendation models, respectively. To account for the time-varying nature of user interests, we propose a simple yet effective reranking method to capture preference dynamics. For the generation phase, we first evaluate reasoning LLMs on recommendation tasks, uncovering valuable insights. Then we introduce knowledge-injected prompting and consistency-based merging approach to integrate reasoning LLMs with general-purpose LLMs, enhancing overall performance. Extensive experiments on three real world datasets validate our method's effectiveness.
CrowdHMTware: A Cross-level Co-adaptation Middleware for Context-aware Mobile DL Deployment
Mar 06, 2025There are many deep learning (DL) powered mobile and wearable applications today continuously and unobtrusively sensing the ambient surroundings to enhance all aspects of human lives.To enable robust and private mobile sensing, DL models are often deployed locally on resource-constrained mobile devices using techniques such as model compression or offloading.However, existing methods, either front-end algorithm level (i.e. DL model compression/partitioning) or back-end scheduling level (i.e. operator/resource scheduling), cannot be locally online because they require offline retraining to ensure accuracy or rely on manually pre-defined strategies, struggle with dynamic adaptability.The primary challenge lies in feeding back runtime performance from the back-end level to the front-end level optimization decision. Moreover, the adaptive mobile DL model porting middleware with cross-level co-adaptation is less explored, particularly in mobile environments with diversity and dynamics. In response, we introduce CrowdHMTware, a dynamic context-adaptive DL model deployment middleware for heterogeneous mobile devices. It establishes an automated adaptation loop between cross-level functional components, i.e. elastic inference, scalable offloading, and model-adaptive engine, enhancing scalability and adaptability. Experiments with four typical tasks across 15 platforms and a real-world case study demonstrate that CrowdHMTware can effectively scale DL model, offloading, and engine actions across diverse platforms and tasks. It hides run-time system issues from developers, reducing the required developer expertise.
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Jan 21, 2025



We present Hunyuan3D 2.0, an advanced large-scale 3D synthesis system for generating high-resolution textured 3D assets. This system includes two foundation components: a large-scale shape generation model -- Hunyuan3D-DiT, and a large-scale texture synthesis model -- Hunyuan3D-Paint. The shape generative model, built on a scalable flow-based diffusion transformer, aims to create geometry that properly aligns with a given condition image, laying a solid foundation for downstream applications. The texture synthesis model, benefiting from strong geometric and diffusion priors, produces high-resolution and vibrant texture maps for either generated or hand-crafted meshes. Furthermore, we build Hunyuan3D-Studio -- a versatile, user-friendly production platform that simplifies the re-creation process of 3D assets. It allows both professional and amateur users to manipulate or even animate their meshes efficiently. We systematically evaluate our models, showing that Hunyuan3D 2.0 outperforms previous state-of-the-art models, including the open-source models and closed-source models in geometry details, condition alignment, texture quality, and etc. Hunyuan3D 2.0 is publicly released in order to fill the gaps in the open-source 3D community for large-scale foundation generative models. The code and pre-trained weights of our models are available at: https://github.com/Tencent/Hunyuan3D-2
Fine-grained Spatio-temporal Event Prediction with Self-adaptive Anchor Graph
Jan 15, 2025Event prediction tasks often handle spatio-temporal data distributed in a large spatial area. Different regions in the area exhibit different characteristics while having latent correlations. This spatial heterogeneity and correlations greatly affect the spatio-temporal distributions of event occurrences, which has not been addressed by state-of-the-art models. Learning spatial dependencies of events in a continuous space is challenging due to its fine granularity and a lack of prior knowledge. In this work, we propose a novel Graph Spatio-Temporal Point Process (GSTPP) model for fine-grained event prediction. It adopts an encoder-decoder architecture that jointly models the state dynamics of spatially localized regions using neural Ordinary Differential Equations (ODEs). The state evolution is built on the foundation of a novel Self-Adaptive Anchor Graph (SAAG) that captures spatial dependencies. By adaptively localizing the anchor nodes in the space and jointly constructing the correlation edges between them, the SAAG enhances the model's ability of learning complex spatial event patterns. The proposed GSTPP model greatly improves the accuracy of fine-grained event prediction. Extensive experimental results show that our method greatly improves the prediction accuracy over existing spatio-temporal event prediction approaches.