 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClarifyMT-Bench: Benchmarking and Improving Multi-Turn Clarification for Conversational Large Language Models
Dec 24, 2025Large language models (LLMs) are increasingly deployed as conversational assistants in open-domain, multi-turn settings, where users often provide incomplete or ambiguous information. However, existing LLM-focused clarification benchmarks primarily assume single-turn interactions or cooperative users, limiting their ability to evaluate clarification behavior in realistic settings. We introduce \textbf{ClarifyMT-Bench}, a benchmark for multi-turn clarification grounded in a five-dimensional ambiguity taxonomy and a set of six behaviorally diverse simulated user personas. Through a hybrid LLM-human pipeline, we construct 6,120 multi-turn dialogues capturing diverse ambiguity sources and interaction patterns. Evaluating ten representative LLMs uncovers a consistent under-clarification bias: LLMs tend to answer prematurely, and performance degrades as dialogue depth increases. To mitigate this, we propose \textbf{ClarifyAgent}, an agentic approach that decomposes clarification into perception, forecasting, tracking, and planning, substantially improving robustness across ambiguity conditions. ClarifyMT-Bench establishes a reproducible foundation for studying when LLMs should ask, when they should answer, and how to navigate ambiguity in real-world human-LLM interactions.
Reasoning Meets Personalization: Unleashing the Potential of Large Reasoning Model for Personalized Generation
May 23, 2025Personalization is a critical task in modern intelligent systems, with applications spanning diverse domains, including interactions with large language models (LLMs). Recent advances in reasoning capabilities have significantly enhanced LLMs, enabling unprecedented performance in tasks such as mathematics and coding. However, their potential for personalization tasks remains underexplored. In this paper, we present the first systematic evaluation of large reasoning models (LRMs) for personalization tasks. Surprisingly, despite generating more tokens, LRMs do not consistently outperform general-purpose LLMs, especially in retrieval-intensive scenarios where their advantages diminish. Our analysis identifies three key limitations: divergent thinking, misalignment of response formats, and ineffective use of retrieved information. To address these challenges, we propose Reinforced Reasoning for Personalization (\model), a novel framework that incorporates a hierarchical reasoning thought template to guide LRMs in generating structured outputs. Additionally, we introduce a reasoning process intervention method to enforce adherence to designed reasoning patterns, enhancing alignment. We also propose a cross-referencing mechanism to ensure consistency. Extensive experiments demonstrate that our approach significantly outperforms existing techniques.
RALLRec+: Retrieval Augmented Large Language Model Recommendation with Reasoning
Mar 26, 2025



Large Language Models (LLMs) have been integrated into recommender systems to enhance user behavior comprehension. The Retrieval Augmented Generation (RAG) technique is further incorporated into these systems to retrieve more relevant items and improve system performance. However, existing RAG methods have two shortcomings. \textit{(i)} In the \textit{retrieval} stage, they rely primarily on textual semantics and often fail to incorporate the most relevant items, thus constraining system effectiveness. \textit{(ii)} In the \textit{generation} stage, they lack explicit chain-of-thought reasoning, further limiting their potential. In this paper, we propose Representation learning and \textbf{R}easoning empowered retrieval-\textbf{A}ugmented \textbf{L}arge \textbf{L}anguage model \textbf{Rec}ommendation (RALLRec+). Specifically, for the retrieval stage, we prompt LLMs to generate detailed item descriptions and perform joint representation learning, combining textual and collaborative signals extracted from the LLM and recommendation models, respectively. To account for the time-varying nature of user interests, we propose a simple yet effective reranking method to capture preference dynamics. For the generation phase, we first evaluate reasoning LLMs on recommendation tasks, uncovering valuable insights. Then we introduce knowledge-injected prompting and consistency-based merging approach to integrate reasoning LLMs with general-purpose LLMs, enhancing overall performance. Extensive experiments on three real world datasets validate our method's effectiveness.
RALLRec: Improving Retrieval Augmented Large Language Model Recommendation with Representation Learning
Feb 10, 2025Large Language Models (LLMs) have been integrated into recommendation systems to enhance user behavior comprehension. The Retrieval Augmented Generation (RAG) technique is further incorporated into these systems to retrieve more relevant items and improve system performance. However, existing RAG methods rely primarily on textual semantics and often fail to incorporate the most relevant items, limiting the effectiveness of the systems. In this paper, we propose Representation learning for retrieval-Augmented Large Language model Recommendation (RALLRec). Specifically, we enhance textual semantics by prompting LLMs to generate more detailed item descriptions, followed by joint representation learning of textual and collaborative semantics, which are extracted by the LLM and recommendation models, respectively. Considering the potential time-varying characteristics of user interest, a simple yet effective reranking method is further introduced to capture the dynamics of user preference. We conducted extensive experiments on three real-world datasets, and the evaluation results validated the effectiveness of our method. Code is made public at https://github.com/JianXu95/RALLRec.
Determine-Then-Ensemble: Necessity of Top-k Union for Large Language Model Ensembling
Oct 03, 2024



Large language models (LLMs) exhibit varying strengths and weaknesses across different tasks, prompting recent studies to explore the benefits of ensembling models to leverage their complementary advantages. However, existing LLM ensembling methods often overlook model compatibility and struggle with inefficient alignment of probabilities across the entire vocabulary. In this study, we empirically investigate the factors influencing ensemble performance, identifying model performance, vocabulary size, and response style as key determinants, revealing that compatibility among models is essential for effective ensembling. This analysis leads to the development of a simple yet effective model selection strategy that identifies compatible models. Additionally, we introduce the \textsc{Uni}on \textsc{T}op-$k$ \textsc{E}nsembling (\textsc{UniTE}), a novel approach that efficiently combines models by focusing on the union of the top-k tokens from each model, thereby avoiding the need for full vocabulary alignment and reducing computational overhead. Extensive evaluations across multiple benchmarks demonstrate that \textsc{UniTE} significantly enhances performance compared to existing methods, offering a more efficient framework for LLM ensembling.
Privacy in LLM-based Recommendation: Recent Advances and Future Directions
Jun 03, 2024Nowadays, large language models (LLMs) have been integrated with conventional recommendation models to improve recommendation performance. However, while most of the existing works have focused on improving the model performance, the privacy issue has only received comparatively less attention. In this paper, we review recent advancements in privacy within LLM-based recommendation, categorizing them into privacy attacks and protection mechanisms. Additionally, we highlight several challenges and propose future directions for the community to address these critical problems.
Learning From Correctness Without Prompting Makes LLM Efficient Reasoner
Mar 28, 2024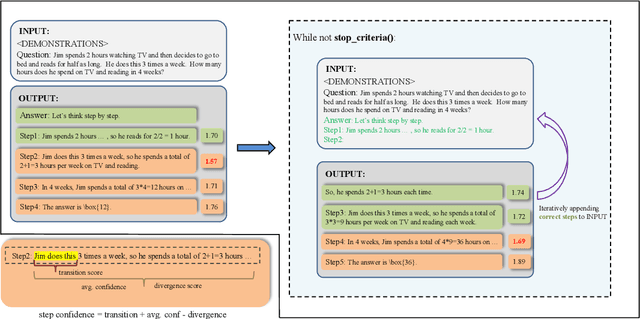



Large language models (LLMs) have demonstrated outstanding performance across various tasks, yet they still exhibit limitations such as hallucination, unfaithful reasoning, and toxic content. One potential approach to mitigate these issues is learning from human or external feedback (e.g. tools). In this paper, we introduce an intrinsic self-correct reasoning framework for LLMs that eliminates the need for human feedback, external tools, and handcraft prompts. The proposed framework, based on a multi-step reasoning paradigm \textbf{Le}arning from \textbf{Co}rrectness (\textsc{LeCo}), improves reasoning performance without needing to learn from errors. This paradigm prioritizes learning from correct reasoning steps, and a unique method to measure confidence for each reasoning step based on generation logits. Experimental results across various multi-step reasoning tasks demonstrate the effectiveness of the framework in improving reasoning performance with reduced token consumption.
Can LLM Substitute Human Labeling? A Case Study of Fine-grained Chinese Address Entity Recognition Dataset for UAV Delivery
Mar 19, 2024



We present CNER-UAV, a fine-grained \textbf{C}hinese \textbf{N}ame \textbf{E}ntity \textbf{R}ecognition dataset specifically designed for the task of address resolution in \textbf{U}nmanned \textbf{A}erial \textbf{V}ehicle delivery systems. The dataset encompasses a diverse range of five categories, enabling comprehensive training and evaluation of NER models. To construct this dataset, we sourced the data from a real-world UAV delivery system and conducted a rigorous data cleaning and desensitization process to ensure privacy and data integrity. The resulting dataset, consisting of around 12,000 annotated samples, underwent human experts and \textbf{L}arge \textbf{L}anguage \textbf{M}odel annotation. We evaluated classical NER models on our dataset and provided in-depth analysis. The dataset and models are publicly available at \url{https://github.com/zhhvvv/CNER-UAV}.
Integrating Large Language Models into Recommendation via Mutual Augmentation and Adaptive Aggregation
Jan 25, 2024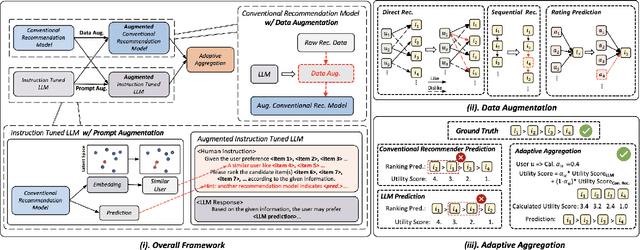
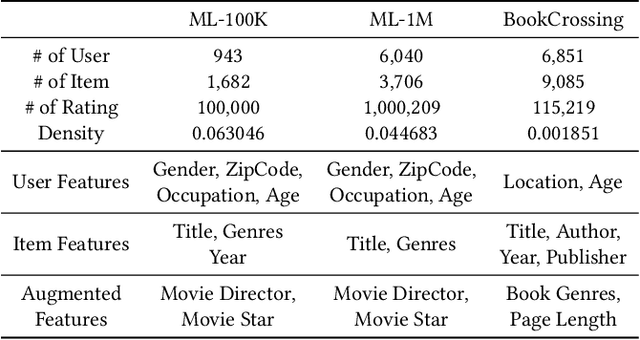
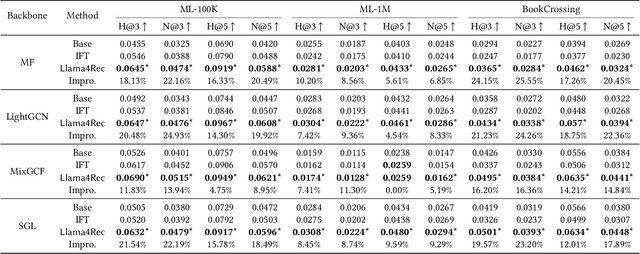
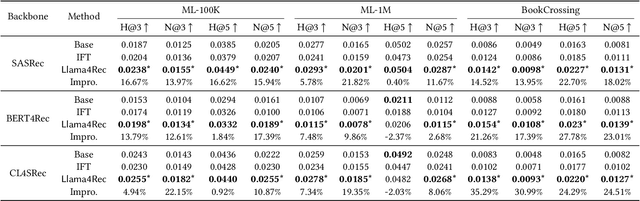
Conventional recommendation methods have achieved notable advancements by harnessing collaborative or sequential information from user behavior. Recently, large language models (LLMs) have gained prominence for their capabilities in understanding and reasoning over textual semantics, and have found utility in various domains, including recommendation. Conventional recommendation methods and LLMs each have their strengths and weaknesses. While conventional methods excel at mining collaborative information and modeling sequential behavior, they struggle with data sparsity and the long-tail problem. LLMs, on the other hand, are proficient at utilizing rich textual contexts but face challenges in mining collaborative or sequential information. Despite their individual successes, there is a significant gap in leveraging their combined potential to enhance recommendation performance. In this paper, we introduce a general and model-agnostic framework known as \textbf{L}arge \textbf{la}nguage model with \textbf{m}utual augmentation and \textbf{a}daptive aggregation for \textbf{Rec}ommendation (\textbf{Llama4Rec}). Llama4Rec synergistically combines conventional and LLM-based recommendation models. Llama4Rec proposes data augmentation and prompt augmentation strategies tailored to enhance the conventional model and LLM respectively. An adaptive aggregation module is adopted to combine the predictions of both kinds of models to refine the final recommendation results. Empirical studies on three real-world datasets validate the superiority of Llama4Rec, demonstrating its consistent outperformance of baseline methods and significant improvements in recommendation performance.
RecRanker: Instruction Tuning Large Language Model as Ranker for Top-k Recommendation
Jan 15, 2024



Large language models (LLMs) have demonstrated remarkable capabilities and have been extensively deployed across various domains, including recommender systems. Numerous studies have employed specialized \textit{prompts} to harness the in-context learning capabilities intrinsic to LLMs. For example, LLMs are prompted to act as zero-shot rankers for listwise ranking, evaluating candidate items generated by a retrieval model for recommendation. Recent research further uses instruction tuning techniques to align LLM with human preference for more promising recommendations. Despite its potential, current research overlooks the integration of multiple ranking tasks to enhance model performance. Moreover, the signal from the conventional recommendation model is not integrated into the LLM, limiting the current system performance. In this paper, we introduce RecRanker, tailored for instruction tuning LLM to serve as the \textbf{Ranker} for top-\textit{k} \textbf{Rec}ommendations. Specifically, we introduce importance-aware sampling, clustering-based sampling, and penalty for repetitive sampling for sampling high-quality, representative, and diverse training data. To enhance the prompt, we introduce position shifting strategy to mitigate position bias and augment the prompt with auxiliary information from conventional recommendation models, thereby enriching the contextual understanding of the LLM. Subsequently, we utilize the sampled data to assemble an instruction-tuning dataset with the augmented prompt comprising three distinct ranking tasks: pointwise, pairwise, and listwise rankings. We further propose a hybrid ranking method to enhance the model performance by ensembling these ranking tasks. Our empirical evaluations demonstrate the effectiveness of our proposed RecRanker in both direct and sequential recommendation scenarios.