 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFullStack-Agent: Enhancing Agentic Full-Stack Web Coding via Development-Oriented Testing and Repository Back-Translation
Feb 03, 2026Assisting non-expert users to develop complex interactive websites has become a popular task for LLM-powered code agents. However, existing code agents tend to only generate frontend web pages, masking the lack of real full-stack data processing and storage with fancy visual effects. Notably, constructing production-level full-stack web applications is far more challenging than only generating frontend web pages, demanding careful control of data flow, comprehensive understanding of constantly updating packages and dependencies, and accurate localization of obscure bugs in the codebase. To address these difficulties, we introduce FullStack-Agent, a unified agent system for full-stack agentic coding that consists of three parts: (1) FullStack-Dev, a multi-agent framework with strong planning, code editing, codebase navigation, and bug localization abilities. (2) FullStack-Learn, an innovative data-scaling and self-improving method that back-translates crawled and synthesized website repositories to improve the backbone LLM of FullStack-Dev. (3) FullStack-Bench, a comprehensive benchmark that systematically tests the frontend, backend and database functionalities of the generated website. Our FullStack-Dev outperforms the previous state-of-the-art method by 8.7%, 38.2%, and 15.9% on the frontend, backend, and database test cases respectively. Additionally, FullStack-Learn raises the performance of a 30B model by 9.7%, 9.5%, and 2.8% on the three sets of test cases through self-improvement, demonstrating the effectiveness of our approach. The code is released at https://github.com/mnluzimu/FullStack-Agent.
SlidesGen-Bench: Evaluating Slides Generation via Computational and Quantitative Metrics
Jan 14, 2026The rapid evolution of Large Language Models (LLMs) has fostered diverse paradigms for automated slide generation, ranging from code-driven layouts to image-centric synthesis. However, evaluating these heterogeneous systems remains challenging, as existing protocols often struggle to provide comparable scores across architectures or rely on uncalibrated judgments. In this paper, we introduce SlidesGen-Bench, a benchmark designed to evaluate slide generation through a lens of three core principles: universality, quantification, and reliability. First, to establish a unified evaluation framework, we ground our analysis in the visual domain, treating terminal outputs as renderings to remain agnostic to the underlying generation method. Second, we propose a computational approach that quantitatively assesses slides across three distinct dimensions - Content, Aesthetics, and Editability - offering reproducible metrics where prior works relied on subjective or reference-dependent proxies. Finally, to ensure high correlation with human preference, we construct the Slides-Align1.5k dataset, a human preference aligned dataset covering slides from nine mainstream generation systems across seven scenarios. Our experiments demonstrate that SlidesGen-Bench achieves a higher degree of alignment with human judgment than existing evaluation pipelines. Our code and data are available at https://github.com/YunqiaoYang/SlidesGen-Bench.
MathCanvas: Intrinsic Visual Chain-of-Thought for Multimodal Mathematical Reasoning
Oct 16, 2025While Large Language Models (LLMs) have excelled in textual reasoning, they struggle with mathematical domains like geometry that intrinsically rely on visual aids. Existing approaches to Visual Chain-of-Thought (VCoT) are often limited by rigid external tools or fail to generate the high-fidelity, strategically-timed diagrams necessary for complex problem-solving. To bridge this gap, we introduce MathCanvas, a comprehensive framework designed to endow unified Large Multimodal Models (LMMs) with intrinsic VCoT capabilities for mathematics. Our approach consists of two phases. First, a Visual Manipulation stage pre-trains the model on a novel 15.2M-pair corpus, comprising 10M caption-to-diagram pairs (MathCanvas-Imagen) and 5.2M step-by-step editing trajectories (MathCanvas-Edit), to master diagram generation and editing. Second, a Strategic Visual-Aided Reasoning stage fine-tunes the model on MathCanvas-Instruct, a new 219K-example dataset of interleaved visual-textual reasoning paths, teaching it when and how to leverage visual aids. To facilitate rigorous evaluation, we introduce MathCanvas-Bench, a challenging benchmark with 3K problems that require models to produce interleaved visual-textual solutions. Our model, BAGEL-Canvas, trained under this framework, achieves an 86% relative improvement over strong LMM baselines on MathCanvas-Bench, demonstrating excellent generalization to other public math benchmarks. Our work provides a complete toolkit-framework, datasets, and benchmark-to unlock complex, human-like visual-aided reasoning in LMMs. Project Page: https://mathcanvas.github.io/
VoiceAssistant-Eval: Benchmarking AI Assistants across Listening, Speaking, and Viewing
Sep 26, 2025The growing capabilities of large language models and multimodal systems have spurred interest in voice-first AI assistants, yet existing benchmarks are inadequate for evaluating the full range of these systems' capabilities. We introduce VoiceAssistant-Eval, a comprehensive benchmark designed to assess AI assistants across listening, speaking, and viewing. VoiceAssistant-Eval comprises 10,497 curated examples spanning 13 task categories. These tasks include natural sounds, music, and spoken dialogue for listening; multi-turn dialogue, role-play imitation, and various scenarios for speaking; and highly heterogeneous images for viewing. To demonstrate its utility, we evaluate 21 open-source models and GPT-4o-Audio, measuring the quality of the response content and speech, as well as their consistency. The results reveal three key findings: (1) proprietary models do not universally outperform open-source models; (2) most models excel at speaking tasks but lag in audio understanding; and (3) well-designed smaller models can rival much larger ones. Notably, the mid-sized Step-Audio-2-mini (7B) achieves more than double the listening accuracy of LLaMA-Omni2-32B-Bilingual. However, challenges remain: multimodal (audio plus visual) input and role-play voice imitation tasks are difficult for current models, and significant gaps persist in robustness and safety alignment. VoiceAssistant-Eval identifies these gaps and establishes a rigorous framework for evaluating and guiding the development of next-generation AI assistants. Code and data will be released at https://mathllm.github.io/VoiceAssistantEval/ .
WebGen-Agent: Enhancing Interactive Website Generation with Multi-Level Feedback and Step-Level Reinforcement Learning
Sep 26, 2025Agent systems powered by large language models (LLMs) have demonstrated impressive performance on repository-level code-generation tasks. However, for tasks such as website codebase generation, which depend heavily on visual effects and user-interaction feedback, current code agents rely only on simple code execution for feedback and verification. This approach fails to capture the actual quality of the generated code. In this paper, we propose WebGen-Agent, a novel website-generation agent that leverages comprehensive and multi-level visual feedback to iteratively generate and refine the website codebase. Detailed and expressive text descriptions and suggestions regarding the screenshots and GUI-agent testing of the websites are generated by a visual language model (VLM), together with scores that quantify their quality. The screenshot and GUI-agent scores are further integrated with a backtracking and select-best mechanism, enhancing the performance of the agent. Utilizing the accurate visual scores inherent in the WebGen-Agent workflow, we further introduce \textit{Step-GRPO with Screenshot and GUI-agent Feedback} to improve the ability of LLMs to act as the reasoning engine of WebGen-Agent. By using the screenshot and GUI-agent scores at each step as the reward in Step-GRPO, we provide a dense and reliable process supervision signal, which effectively improves the model's website-generation ability. On the WebGen-Bench dataset, WebGen-Agent increases the accuracy of Claude-3.5-Sonnet from 26.4% to 51.9% and its appearance score from 3.0 to 3.9, outperforming the previous state-of-the-art agent system. Additionally, our Step-GRPO training approach increases the accuracy of Qwen2.5-Coder-7B-Instruct from 38.9% to 45.4% and raises the appearance score from 3.4 to 3.7.
Alignment with Fill-In-the-Middle for Enhancing Code Generation
Aug 27, 2025The code generation capabilities of Large Language Models (LLMs) have advanced applications like tool invocation and problem-solving. However, improving performance in code-related tasks remains challenging due to limited training data that is verifiable with accurate test cases. While Direct Preference Optimization (DPO) has shown promise, existing methods for generating test cases still face limitations. In this paper, we propose a novel approach that splits code snippets into smaller, granular blocks, creating more diverse DPO pairs from the same test cases. Additionally, we introduce the Abstract Syntax Tree (AST) splitting and curriculum training method to enhance the DPO training. Our approach demonstrates significant improvements in code generation tasks, as validated by experiments on benchmark datasets such as HumanEval (+), MBPP (+), APPS, LiveCodeBench, and BigCodeBench. Code and data are available at https://github.com/SenseLLM/StructureCoder.
Probability-Consistent Preference Optimization for Enhanced LLM Reasoning
May 29, 2025Recent advances in preference optimization have demonstrated significant potential for improving mathematical reasoning capabilities in large language models (LLMs). While current approaches leverage high-quality pairwise preference data through outcome-based criteria like answer correctness or consistency, they fundamentally neglect the internal logical coherence of responses. To overcome this, we propose Probability-Consistent Preference Optimization (PCPO), a novel framework that establishes dual quantitative metrics for preference selection: (1) surface-level answer correctness and (2) intrinsic token-level probability consistency across responses. Extensive experiments show that our PCPO consistently outperforms existing outcome-only criterion approaches across a diverse range of LLMs and benchmarks. Our code is publicly available at https://github.com/YunqiaoYang/PCPO.
UI-Genie: A Self-Improving Approach for Iteratively Boosting MLLM-based Mobile GUI Agents
May 27, 2025In this paper, we introduce UI-Genie, a self-improving framework addressing two key challenges in GUI agents: verification of trajectory outcome is challenging and high-quality training data are not scalable. These challenges are addressed by a reward model and a self-improving pipeline, respectively. The reward model, UI-Genie-RM, features an image-text interleaved architecture that efficiently pro- cesses historical context and unifies action-level and task-level rewards. To sup- port the training of UI-Genie-RM, we develop deliberately-designed data genera- tion strategies including rule-based verification, controlled trajectory corruption, and hard negative mining. To address the second challenge, a self-improvement pipeline progressively expands solvable complex GUI tasks by enhancing both the agent and reward models through reward-guided exploration and outcome verification in dynamic environments. For training the model, we generate UI- Genie-RM-517k and UI-Genie-Agent-16k, establishing the first reward-specific dataset for GUI agents while demonstrating high-quality synthetic trajectory gen- eration without manual annotation. Experimental results show that UI-Genie achieves state-of-the-art performance across multiple GUI agent benchmarks with three generations of data-model self-improvement. We open-source our complete framework implementation and generated datasets to facilitate further research in https://github.com/Euphoria16/UI-Genie.
MathCoder-VL: Bridging Vision and Code for Enhanced Multimodal Mathematical Reasoning
May 15, 2025Natural language image-caption datasets, widely used for training Large Multimodal Models, mainly focus on natural scenarios and overlook the intricate details of mathematical figures that are critical for problem-solving, hindering the advancement of current LMMs in multimodal mathematical reasoning. To this end, we propose leveraging code as supervision for cross-modal alignment, since code inherently encodes all information needed to generate corresponding figures, establishing a precise connection between the two modalities. Specifically, we co-develop our image-to-code model and dataset with model-in-the-loop approach, resulting in an image-to-code model, FigCodifier and ImgCode-8.6M dataset, the largest image-code dataset to date. Furthermore, we utilize FigCodifier to synthesize novel mathematical figures and then construct MM-MathInstruct-3M, a high-quality multimodal math instruction fine-tuning dataset. Finally, we present MathCoder-VL, trained with ImgCode-8.6M for cross-modal alignment and subsequently fine-tuned on MM-MathInstruct-3M for multimodal math problem solving. Our model achieves a new open-source SOTA across all six metrics. Notably, it surpasses GPT-4o and Claude 3.5 Sonnet in the geometry problem-solving subset of MathVista, achieving improvements of 8.9% and 9.2%. The dataset and models will be released at https://github.com/mathllm/MathCoder.
WebGen-Bench: Evaluating LLMs on Generating Interactive and Functional Websites from Scratch
May 06, 2025
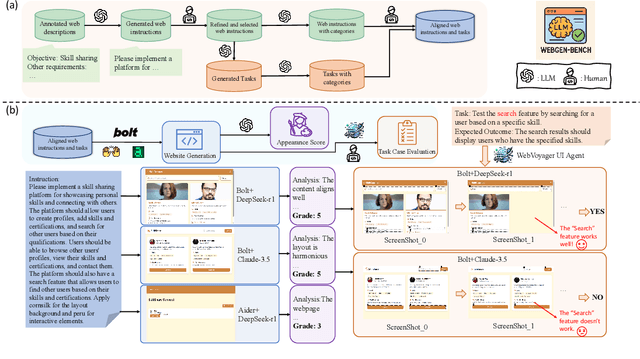
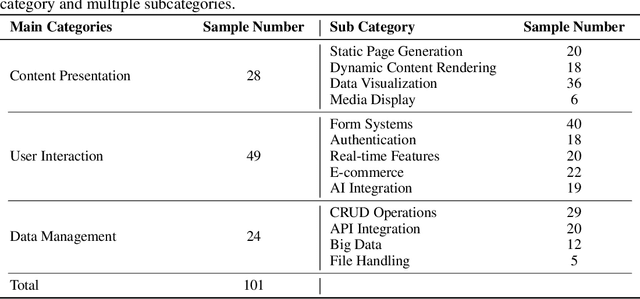
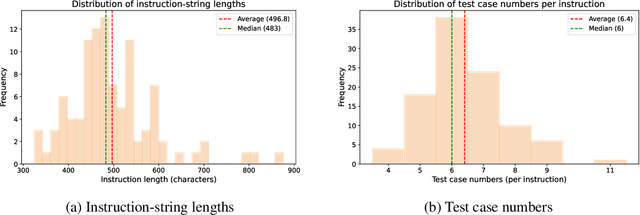
LLM-based agents have demonstrated great potential in generating and managing code within complex codebases. In this paper, we introduce WebGen-Bench, a novel benchmark designed to measure an LLM-based agent's ability to create multi-file website codebases from scratch. It contains diverse instructions for website generation, created through the combined efforts of human annotators and GPT-4o. These instructions span three major categories and thirteen minor categories, encompassing nearly all important types of web applications. To assess the quality of the generated websites, we use GPT-4o to generate test cases targeting each functionality described in the instructions, and then manually filter, adjust, and organize them to ensure accuracy, resulting in 647 test cases. Each test case specifies an operation to be performed on the website and the expected result after the operation. To automate testing and improve reproducibility, we employ a powerful web-navigation agent to execute tests on the generated websites and determine whether the observed responses align with the expected results. We evaluate three high-performance code-agent frameworks, Bolt.diy, OpenHands, and Aider, using multiple proprietary and open-source LLMs as engines. The best-performing combination, Bolt.diy powered by DeepSeek-R1, achieves only 27.8\% accuracy on the test cases, highlighting the challenging nature of our benchmark. Additionally, we construct WebGen-Instruct, a training set consisting of 6,667 website-generation instructions. Training Qwen2.5-Coder-32B-Instruct on Bolt.diy trajectories generated from a subset of this training set achieves an accuracy of 38.2\%, surpassing the performance of the best proprietary model.