 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagine Before You Draw: Visual Prompt Engineering for Image Generation
Jun 03, 2026Incorporating visual semantic representations as an intermediate step before image generation can reduce the modeling difficulty between text and images, thereby improving generation quality. Recent works such as X-Omni and BLIP3o-Next have explored this direction, but they typically use a two-stage external pipeline: a separate autoregressive model first generates semantic tokens, which are then fed as conditioning to an independent diffusion decoder. Since the decoder cannot jointly access the original input and the semantic plan, this design introduces an information bottleneck that limits detail preservation in downstream tasks such as editing. Internal architectures such as Transfusion, BAGEL, and Show-o2 avoid this bottleneck by enabling cross-modal interaction within a single model, but they still face the difficult text-to-pixel modeling gap without intermediate semantic guidance. We propose Visual Prompt Engineering (VPE), which can be seamlessly integrated into such internal frameworks. Specifically, the model first autoregressively generates visual semantic tokens (e.g., SigLIP 2) as "visual prompts" that capture the semantic layout, then generates the full image tokens conditioned on this plan. We validate VPE across class-conditional generation, text-to-image generation, and image editing, covering various token types and model architectures. Results show that VPE can accelerate convergence, raise quality ceilings, and through internal integration, achieve substantially better editing preservation (PSNR: 26.76 vs. 19.92) than external alternatives of the same parameter scale, while maintaining competitive editing responsiveness.
Reflect to Inform: Boosting Multimodal Reasoning via Information-Gain-Driven Verification
Mar 27, 2026Multimodal Large Language Models (MLLMs) achieve strong multimodal reasoning performance, yet we identify a recurring failure mode in long-form generation: as outputs grow longer, models progressively drift away from image evidence and fall back on textual priors, resulting in ungrounded reasoning and hallucinations. Interestingly, Based on attention analysis, we find that MLLMs have a latent capability for late-stage visual verification that is present but not consistently activated. Motivated by this observation, we propose Visual Re-Examination (VRE), a self-evolving training framework that enables MLLMs to autonomously perform visual introspection during reasoning without additional visual inputs. Rather than distilling visual capabilities from a stronger teacher, VRE promotes iterative self-improvement by leveraging the model itself to generate reflection traces, making visual information actionable through information gain. Extensive experiments across diverse multimodal benchmarks demonstrate that VRE consistently improves reasoning accuracy and perceptual reliability, while substantially reducing hallucinations, especially in long-chain settings. Code is available at https://github.com/Xiaobu-USTC/VRE.
From Solver to Tutor: Evaluating the Pedagogical Intelligence of LLMs with KMP-Bench
Mar 03, 2026Large Language Models (LLMs) show significant potential in AI mathematical tutoring, yet current evaluations often rely on simplistic metrics or narrow pedagogical scenarios, failing to assess comprehensive, multi-turn teaching effectiveness. In this paper, we introduce KMP-Bench, a comprehensive K-8 Mathematical Pedagogical Benchmark designed to assess LLMs from two complementary perspectives. The first module, KMP-Dialogue, evaluates holistic pedagogical capabilities against six core principles (e.g., Challenge, Explanation, Feedback), leveraging a novel multi-turn dialogue dataset constructed by weaving together diverse pedagogical components. The second module, KMP-Skills, provides a granular assessment of foundational tutoring abilities, including multi-turn problem-solving, error detection and correction, and problem generation. Our evaluations on KMP-Bench reveal a key disparity: while leading LLMs excel at tasks with verifiable solutions, they struggle with the nuanced application of pedagogical principles. Additionally, we present KMP-Pile, a large-scale (150K) dialogue dataset. Models fine-tuned on KMP-Pile show substantial improvement on KMP-Bench, underscoring the value of pedagogically-rich training data for developing more effective AI math tutors.
MathCanvas: Intrinsic Visual Chain-of-Thought for Multimodal Mathematical Reasoning
Oct 16, 2025While Large Language Models (LLMs) have excelled in textual reasoning, they struggle with mathematical domains like geometry that intrinsically rely on visual aids. Existing approaches to Visual Chain-of-Thought (VCoT) are often limited by rigid external tools or fail to generate the high-fidelity, strategically-timed diagrams necessary for complex problem-solving. To bridge this gap, we introduce MathCanvas, a comprehensive framework designed to endow unified Large Multimodal Models (LMMs) with intrinsic VCoT capabilities for mathematics. Our approach consists of two phases. First, a Visual Manipulation stage pre-trains the model on a novel 15.2M-pair corpus, comprising 10M caption-to-diagram pairs (MathCanvas-Imagen) and 5.2M step-by-step editing trajectories (MathCanvas-Edit), to master diagram generation and editing. Second, a Strategic Visual-Aided Reasoning stage fine-tunes the model on MathCanvas-Instruct, a new 219K-example dataset of interleaved visual-textual reasoning paths, teaching it when and how to leverage visual aids. To facilitate rigorous evaluation, we introduce MathCanvas-Bench, a challenging benchmark with 3K problems that require models to produce interleaved visual-textual solutions. Our model, BAGEL-Canvas, trained under this framework, achieves an 86% relative improvement over strong LMM baselines on MathCanvas-Bench, demonstrating excellent generalization to other public math benchmarks. Our work provides a complete toolkit-framework, datasets, and benchmark-to unlock complex, human-like visual-aided reasoning in LMMs. Project Page: https://mathcanvas.github.io/
Alignment with Fill-In-the-Middle for Enhancing Code Generation
Aug 27, 2025The code generation capabilities of Large Language Models (LLMs) have advanced applications like tool invocation and problem-solving. However, improving performance in code-related tasks remains challenging due to limited training data that is verifiable with accurate test cases. While Direct Preference Optimization (DPO) has shown promise, existing methods for generating test cases still face limitations. In this paper, we propose a novel approach that splits code snippets into smaller, granular blocks, creating more diverse DPO pairs from the same test cases. Additionally, we introduce the Abstract Syntax Tree (AST) splitting and curriculum training method to enhance the DPO training. Our approach demonstrates significant improvements in code generation tasks, as validated by experiments on benchmark datasets such as HumanEval (+), MBPP (+), APPS, LiveCodeBench, and BigCodeBench. Code and data are available at https://github.com/SenseLLM/StructureCoder.
MINT-CoT: Enabling Interleaved Visual Tokens in Mathematical Chain-of-Thought Reasoning
Jun 05, 2025Chain-of-Thought (CoT) has widely enhanced mathematical reasoning in Large Language Models (LLMs), but it still remains challenging for extending it to multimodal domains. Existing works either adopt a similar textual reasoning for image input, or seek to interleave visual signals into mathematical CoT. However, they face three key limitations for math problem-solving: reliance on coarse-grained box-shaped image regions, limited perception of vision encoders on math content, and dependence on external capabilities for visual modification. In this paper, we propose MINT-CoT, introducing Mathematical INterleaved Tokens for Chain-of-Thought visual reasoning. MINT-CoT adaptively interleaves relevant visual tokens into textual reasoning steps via an Interleave Token, which dynamically selects visual regions of any shapes within math figures. To empower this capability, we construct the MINT-CoT dataset, containing 54K mathematical problems aligning each reasoning step with visual regions at the token level, accompanied by a rigorous data generation pipeline. We further present a three-stage MINT-CoT training strategy, progressively combining text-only CoT SFT, interleaved CoT SFT, and interleaved CoT RL, which derives our MINT-CoT-7B model. Extensive experiments demonstrate the effectiveness of our method for effective visual interleaved reasoning in mathematical domains, where MINT-CoT-7B outperforms the baseline model by +34.08% on MathVista, +28.78% on GeoQA, and +23.2% on MMStar, respectively. Our code and data are available at https://github.com/xinyan-cxy/MINT-CoT
Probability-Consistent Preference Optimization for Enhanced LLM Reasoning
May 29, 2025Recent advances in preference optimization have demonstrated significant potential for improving mathematical reasoning capabilities in large language models (LLMs). While current approaches leverage high-quality pairwise preference data through outcome-based criteria like answer correctness or consistency, they fundamentally neglect the internal logical coherence of responses. To overcome this, we propose Probability-Consistent Preference Optimization (PCPO), a novel framework that establishes dual quantitative metrics for preference selection: (1) surface-level answer correctness and (2) intrinsic token-level probability consistency across responses. Extensive experiments show that our PCPO consistently outperforms existing outcome-only criterion approaches across a diverse range of LLMs and benchmarks. Our code is publicly available at https://github.com/YunqiaoYang/PCPO.
UI-Genie: A Self-Improving Approach for Iteratively Boosting MLLM-based Mobile GUI Agents
May 27, 2025In this paper, we introduce UI-Genie, a self-improving framework addressing two key challenges in GUI agents: verification of trajectory outcome is challenging and high-quality training data are not scalable. These challenges are addressed by a reward model and a self-improving pipeline, respectively. The reward model, UI-Genie-RM, features an image-text interleaved architecture that efficiently pro- cesses historical context and unifies action-level and task-level rewards. To sup- port the training of UI-Genie-RM, we develop deliberately-designed data genera- tion strategies including rule-based verification, controlled trajectory corruption, and hard negative mining. To address the second challenge, a self-improvement pipeline progressively expands solvable complex GUI tasks by enhancing both the agent and reward models through reward-guided exploration and outcome verification in dynamic environments. For training the model, we generate UI- Genie-RM-517k and UI-Genie-Agent-16k, establishing the first reward-specific dataset for GUI agents while demonstrating high-quality synthetic trajectory gen- eration without manual annotation. Experimental results show that UI-Genie achieves state-of-the-art performance across multiple GUI agent benchmarks with three generations of data-model self-improvement. We open-source our complete framework implementation and generated datasets to facilitate further research in https://github.com/Euphoria16/UI-Genie.
MathCoder-VL: Bridging Vision and Code for Enhanced Multimodal Mathematical Reasoning
May 15, 2025Natural language image-caption datasets, widely used for training Large Multimodal Models, mainly focus on natural scenarios and overlook the intricate details of mathematical figures that are critical for problem-solving, hindering the advancement of current LMMs in multimodal mathematical reasoning. To this end, we propose leveraging code as supervision for cross-modal alignment, since code inherently encodes all information needed to generate corresponding figures, establishing a precise connection between the two modalities. Specifically, we co-develop our image-to-code model and dataset with model-in-the-loop approach, resulting in an image-to-code model, FigCodifier and ImgCode-8.6M dataset, the largest image-code dataset to date. Furthermore, we utilize FigCodifier to synthesize novel mathematical figures and then construct MM-MathInstruct-3M, a high-quality multimodal math instruction fine-tuning dataset. Finally, we present MathCoder-VL, trained with ImgCode-8.6M for cross-modal alignment and subsequently fine-tuned on MM-MathInstruct-3M for multimodal math problem solving. Our model achieves a new open-source SOTA across all six metrics. Notably, it surpasses GPT-4o and Claude 3.5 Sonnet in the geometry problem-solving subset of MathVista, achieving improvements of 8.9% and 9.2%. The dataset and models will be released at https://github.com/mathllm/MathCoder.
Adaptive Markup Language Generation for Contextually-Grounded Visual Document Understanding
May 08, 2025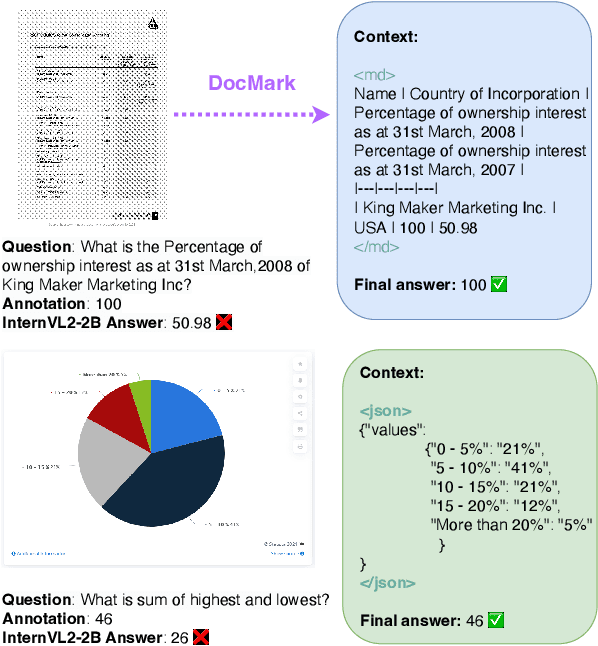
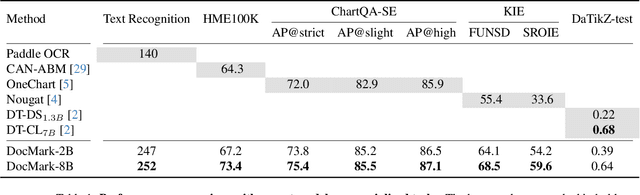
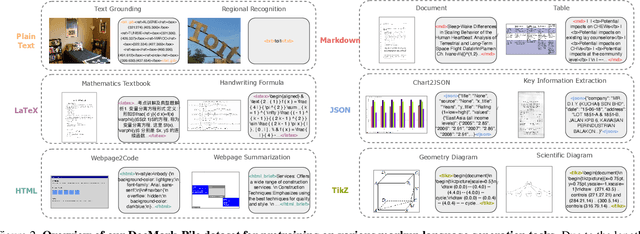
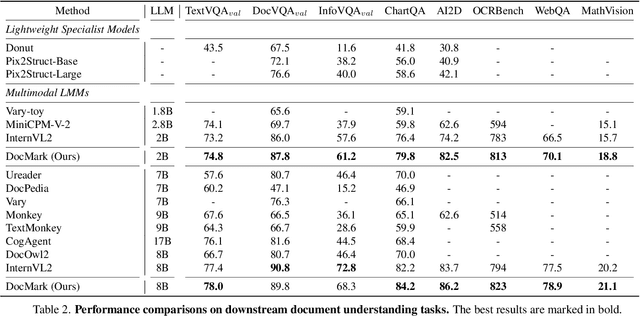
Visual Document Understanding has become essential with the increase of text-rich visual content. This field poses significant challenges due to the need for effective integration of visual perception and textual comprehension, particularly across diverse document types with complex layouts. Moreover, existing fine-tuning datasets for this domain often fall short in providing the detailed contextual information for robust understanding, leading to hallucinations and limited comprehension of spatial relationships among visual elements. To address these challenges, we propose an innovative pipeline that utilizes adaptive generation of markup languages, such as Markdown, JSON, HTML, and TiKZ, to build highly structured document representations and deliver contextually-grounded responses. We introduce two fine-grained structured datasets: DocMark-Pile, comprising approximately 3.8M pretraining data pairs for document parsing, and DocMark-Instruct, featuring 624k fine-tuning data annotations for grounded instruction following. Extensive experiments demonstrate that our proposed model significantly outperforms existing state-of-theart MLLMs across a range of visual document understanding benchmarks, facilitating advanced reasoning and comprehension capabilities in complex visual scenarios. Our code and models are released at https://github. com/Euphoria16/DocMark.