 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Generative Transformer Is What You Need for Image Editing
May 11, 2026Diffusion models dominate image editing, yet their global denoising mechanism entangles edited regions with surrounding context, causing modifications to propagate into areas that should remain intact. We propose a fundamentally different approach by leveraging Masked Generative Transformers (MGTs), whose localized token-prediction paradigm naturally confines changes to intended regions. We present EditMGT, an MGT-based editing framework that is the first of its kind. Our approach employs multi-layer attention consolidation to aggregate cross-attention maps into precise edit localization signals, and region-hold sampling to explicitly prevent token flipping in non-target areas. To support training, we construct CrispEdit-2M, a 2M-sample high-resolution (>1024) editing dataset spanning seven categories. With only 960M parameters, EditMGT achieves state-of-the-art image similarity on multiple benchmarks while delivering 6x faster editing, demonstrating that MGTs offer a compelling alternative to diffusion-based editing.
Edit-Based Refinement for Parallel Masked Diffusion Language Models
May 10, 2026Masked diffusion language models enable parallel token generation and offer improved decoding efficiency over autoregressive models. However, their performance degrades significantly when generating multiple tokens simultaneously, due to a mismatch between token-level training objectives and joint sequence consistency. In this paper, we propose ME-DLM, an edit-based refinement framework that augments diffusion generation with lightweight post-editing steps. After producing an initial complete response, the model refines it through minimal edit operations, including replacement, deletion, and insertion, conditioned on the full sequence. Training supervision is derived from edit distance, providing a deterministic signal under a fixed canonicalization scheme for learning minimal corrections. This approach encourages sequence-level consistency through globally conditioned edits while preserving the efficiency benefits of parallel diffusion decoding. Extensive experiments demonstrate that ME-DLM improves the quality and robustness of multi-token parallel generation. In particular, when built upon LLaDA, our method achieves consistent gains of 11.6 points on HumanEval and 33.6 points on GSM8K while using one-eighth of the total diffusion steps. Code is available at https://github.com/renhouxing/ME-DLM.
From Solver to Tutor: Evaluating the Pedagogical Intelligence of LLMs with KMP-Bench
Mar 03, 2026Large Language Models (LLMs) show significant potential in AI mathematical tutoring, yet current evaluations often rely on simplistic metrics or narrow pedagogical scenarios, failing to assess comprehensive, multi-turn teaching effectiveness. In this paper, we introduce KMP-Bench, a comprehensive K-8 Mathematical Pedagogical Benchmark designed to assess LLMs from two complementary perspectives. The first module, KMP-Dialogue, evaluates holistic pedagogical capabilities against six core principles (e.g., Challenge, Explanation, Feedback), leveraging a novel multi-turn dialogue dataset constructed by weaving together diverse pedagogical components. The second module, KMP-Skills, provides a granular assessment of foundational tutoring abilities, including multi-turn problem-solving, error detection and correction, and problem generation. Our evaluations on KMP-Bench reveal a key disparity: while leading LLMs excel at tasks with verifiable solutions, they struggle with the nuanced application of pedagogical principles. Additionally, we present KMP-Pile, a large-scale (150K) dialogue dataset. Models fine-tuned on KMP-Pile show substantial improvement on KMP-Bench, underscoring the value of pedagogically-rich training data for developing more effective AI math tutors.
EditMGT: Unleashing Potentials of Masked Generative Transformers in Image Editing
Dec 12, 2025Recent advances in diffusion models (DMs) have achieved exceptional visual quality in image editing tasks. However, the global denoising dynamics of DMs inherently conflate local editing targets with the full-image context, leading to unintended modifications in non-target regions. In this paper, we shift our attention beyond DMs and turn to Masked Generative Transformers (MGTs) as an alternative approach to tackle this challenge. By predicting multiple masked tokens rather than holistic refinement, MGTs exhibit a localized decoding paradigm that endows them with the inherent capacity to explicitly preserve non-relevant regions during the editing process. Building upon this insight, we introduce the first MGT-based image editing framework, termed EditMGT. We first demonstrate that MGT's cross-attention maps provide informative localization signals for localizing edit-relevant regions and devise a multi-layer attention consolidation scheme that refines these maps to achieve fine-grained and precise localization. On top of these adaptive localization results, we introduce region-hold sampling, which restricts token flipping within low-attention areas to suppress spurious edits, thereby confining modifications to the intended target regions and preserving the integrity of surrounding non-target areas. To train EditMGT, we construct CrispEdit-2M, a high-resolution dataset spanning seven diverse editing categories. Without introducing additional parameters, we adapt a pre-trained text-to-image MGT into an image editing model through attention injection. Extensive experiments across four standard benchmarks demonstrate that, with fewer than 1B parameters, our model achieves similarity performance while enabling 6 times faster editing. Moreover, it delivers comparable or superior editing quality, with improvements of 3.6% and 17.6% on style change and style transfer tasks, respectively.
WebGen-Agent: Enhancing Interactive Website Generation with Multi-Level Feedback and Step-Level Reinforcement Learning
Sep 26, 2025Agent systems powered by large language models (LLMs) have demonstrated impressive performance on repository-level code-generation tasks. However, for tasks such as website codebase generation, which depend heavily on visual effects and user-interaction feedback, current code agents rely only on simple code execution for feedback and verification. This approach fails to capture the actual quality of the generated code. In this paper, we propose WebGen-Agent, a novel website-generation agent that leverages comprehensive and multi-level visual feedback to iteratively generate and refine the website codebase. Detailed and expressive text descriptions and suggestions regarding the screenshots and GUI-agent testing of the websites are generated by a visual language model (VLM), together with scores that quantify their quality. The screenshot and GUI-agent scores are further integrated with a backtracking and select-best mechanism, enhancing the performance of the agent. Utilizing the accurate visual scores inherent in the WebGen-Agent workflow, we further introduce \textit{Step-GRPO with Screenshot and GUI-agent Feedback} to improve the ability of LLMs to act as the reasoning engine of WebGen-Agent. By using the screenshot and GUI-agent scores at each step as the reward in Step-GRPO, we provide a dense and reliable process supervision signal, which effectively improves the model's website-generation ability. On the WebGen-Bench dataset, WebGen-Agent increases the accuracy of Claude-3.5-Sonnet from 26.4% to 51.9% and its appearance score from 3.0 to 3.9, outperforming the previous state-of-the-art agent system. Additionally, our Step-GRPO training approach increases the accuracy of Qwen2.5-Coder-7B-Instruct from 38.9% to 45.4% and raises the appearance score from 3.4 to 3.7.
Alignment with Fill-In-the-Middle for Enhancing Code Generation
Aug 27, 2025The code generation capabilities of Large Language Models (LLMs) have advanced applications like tool invocation and problem-solving. However, improving performance in code-related tasks remains challenging due to limited training data that is verifiable with accurate test cases. While Direct Preference Optimization (DPO) has shown promise, existing methods for generating test cases still face limitations. In this paper, we propose a novel approach that splits code snippets into smaller, granular blocks, creating more diverse DPO pairs from the same test cases. Additionally, we introduce the Abstract Syntax Tree (AST) splitting and curriculum training method to enhance the DPO training. Our approach demonstrates significant improvements in code generation tasks, as validated by experiments on benchmark datasets such as HumanEval (+), MBPP (+), APPS, LiveCodeBench, and BigCodeBench. Code and data are available at https://github.com/SenseLLM/StructureCoder.
Probability-Consistent Preference Optimization for Enhanced LLM Reasoning
May 29, 2025Recent advances in preference optimization have demonstrated significant potential for improving mathematical reasoning capabilities in large language models (LLMs). While current approaches leverage high-quality pairwise preference data through outcome-based criteria like answer correctness or consistency, they fundamentally neglect the internal logical coherence of responses. To overcome this, we propose Probability-Consistent Preference Optimization (PCPO), a novel framework that establishes dual quantitative metrics for preference selection: (1) surface-level answer correctness and (2) intrinsic token-level probability consistency across responses. Extensive experiments show that our PCPO consistently outperforms existing outcome-only criterion approaches across a diverse range of LLMs and benchmarks. Our code is publicly available at https://github.com/YunqiaoYang/PCPO.
MathCoder-VL: Bridging Vision and Code for Enhanced Multimodal Mathematical Reasoning
May 15, 2025Natural language image-caption datasets, widely used for training Large Multimodal Models, mainly focus on natural scenarios and overlook the intricate details of mathematical figures that are critical for problem-solving, hindering the advancement of current LMMs in multimodal mathematical reasoning. To this end, we propose leveraging code as supervision for cross-modal alignment, since code inherently encodes all information needed to generate corresponding figures, establishing a precise connection between the two modalities. Specifically, we co-develop our image-to-code model and dataset with model-in-the-loop approach, resulting in an image-to-code model, FigCodifier and ImgCode-8.6M dataset, the largest image-code dataset to date. Furthermore, we utilize FigCodifier to synthesize novel mathematical figures and then construct MM-MathInstruct-3M, a high-quality multimodal math instruction fine-tuning dataset. Finally, we present MathCoder-VL, trained with ImgCode-8.6M for cross-modal alignment and subsequently fine-tuned on MM-MathInstruct-3M for multimodal math problem solving. Our model achieves a new open-source SOTA across all six metrics. Notably, it surpasses GPT-4o and Claude 3.5 Sonnet in the geometry problem-solving subset of MathVista, achieving improvements of 8.9% and 9.2%. The dataset and models will be released at https://github.com/mathllm/MathCoder.
Navi-plus: Managing Ambiguous GUI Navigation Tasks with Follow-up
Mar 31, 2025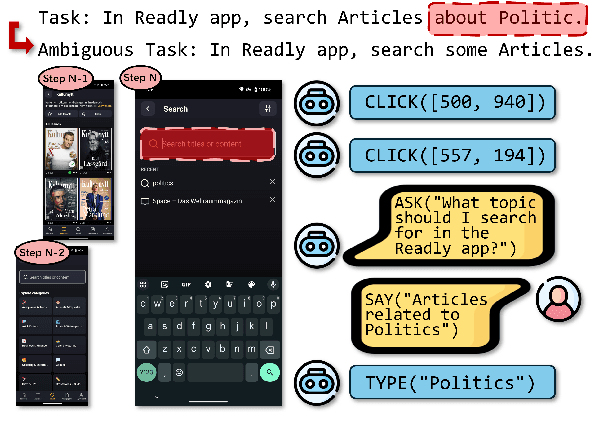
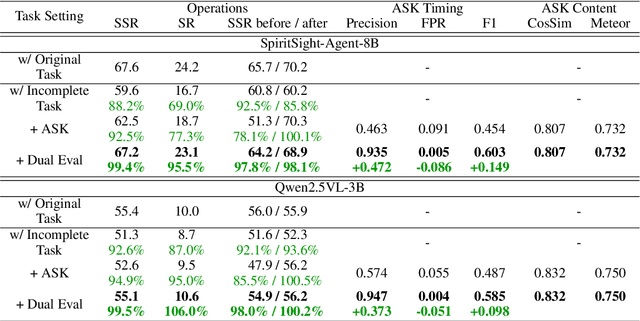
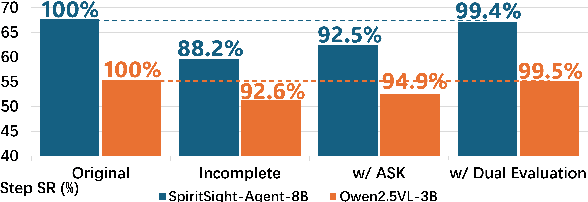
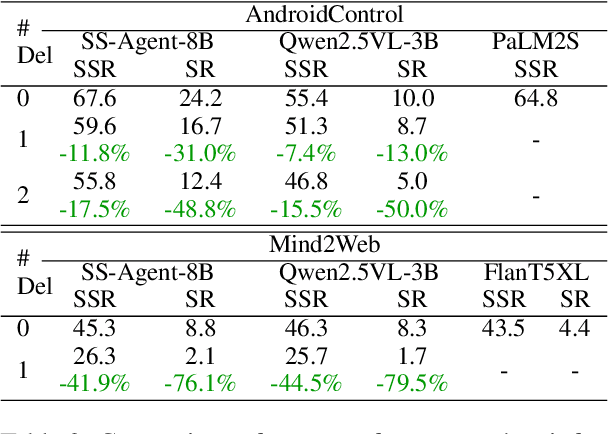
Graphical user interfaces (GUI) automation agents are emerging as powerful tools, enabling humans to accomplish increasingly complex tasks on smart devices. However, users often inadvertently omit key information when conveying tasks, which hinders agent performance in the current agent paradigm that does not support immediate user intervention. To address this issue, we introduce a $\textbf{Self-Correction GUI Navigation}$ task that incorporates interactive information completion capabilities within GUI agents. We developed the $\textbf{Navi-plus}$ dataset with GUI follow-up question-answer pairs, alongside a $\textbf{Dual-Stream Trajectory Evaluation}$ method to benchmark this new capability. Our results show that agents equipped with the ability to ask GUI follow-up questions can fully recover their performance when faced with ambiguous user tasks.
SpiritSight Agent: Advanced GUI Agent with One Look
Mar 05, 2025Graphical User Interface (GUI) agents show amazing abilities in assisting human-computer interaction, automating human user's navigation on digital devices. An ideal GUI agent is expected to achieve high accuracy, low latency, and compatibility for different GUI platforms. Recent vision-based approaches have shown promise by leveraging advanced Vision Language Models (VLMs). While they generally meet the requirements of compatibility and low latency, these vision-based GUI agents tend to have low accuracy due to their limitations in element grounding. To address this issue, we propose $\textbf{SpiritSight}$, a vision-based, end-to-end GUI agent that excels in GUI navigation tasks across various GUI platforms. First, we create a multi-level, large-scale, high-quality GUI dataset called $\textbf{GUI-Lasagne}$ using scalable methods, empowering SpiritSight with robust GUI understanding and grounding capabilities. Second, we introduce the $\textbf{Universal Block Parsing (UBP)}$ method to resolve the ambiguity problem in dynamic high-resolution of visual inputs, further enhancing SpiritSight's ability to ground GUI objects. Through these efforts, SpiritSight agent outperforms other advanced methods on diverse GUI benchmarks, demonstrating its superior capability and compatibility in GUI navigation tasks. Models are available at $\href{https://huggingface.co/SenseLLM/SpiritSight-Agent-8B}{this\ URL}$.