 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe SA-FARI Dataset: Segment Anything in Footage of Animals for Recognition and Identification
Nov 19, 2025Automated video analysis is critical for wildlife conservation. A foundational task in this domain is multi-animal tracking (MAT), which underpins applications such as individual re-identification and behavior recognition. However, existing datasets are limited in scale, constrained to a few species, or lack sufficient temporal and geographical diversity - leaving no suitable benchmark for training general-purpose MAT models applicable across wild animal populations. To address this, we introduce SA-FARI, the largest open-source MAT dataset for wild animals. It comprises 11,609 camera trap videos collected over approximately 10 years (2014-2024) from 741 locations across 4 continents, spanning 99 species categories. Each video is exhaustively annotated culminating in ~46 hours of densely annotated footage containing 16,224 masklet identities and 942,702 individual bounding boxes, segmentation masks, and species labels. Alongside the task-specific annotations, we publish anonymized camera trap locations for each video. Finally, we present comprehensive benchmarks on SA-FARI using state-of-the-art vision-language models for detection and tracking, including SAM 3, evaluated with both species-specific and generic animal prompts. We also compare against vision-only methods developed specifically for wildlife analysis. SA-FARI is the first large-scale dataset to combine high species diversity, multi-region coverage, and high-quality spatio-temporal annotations, offering a new foundation for advancing generalizable multianimal tracking in the wild. The dataset is available at $\href{https://www.conservationxlabs.com/sa-fari}{\text{conservationxlabs.com/SA-FARI}}$.
SAM 2: Segment Anything in Images and Videos
Aug 01, 2024



We present Segment Anything Model 2 (SAM 2), a foundation model towards solving promptable visual segmentation in images and videos. We build a data engine, which improves model and data via user interaction, to collect the largest video segmentation dataset to date. Our model is a simple transformer architecture with streaming memory for real-time video processing. SAM 2 trained on our data provides strong performance across a wide range of tasks. In video segmentation, we observe better accuracy, using 3x fewer interactions than prior approaches. In image segmentation, our model is more accurate and 6x faster than the Segment Anything Model (SAM). We believe that our data, model, and insights will serve as a significant milestone for video segmentation and related perception tasks. We are releasing a version of our model, the dataset and an interactive demo.
Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles
Jun 01, 2023



Modern hierarchical vision transformers have added several vision-specific components in the pursuit of supervised classification performance. While these components lead to effective accuracies and attractive FLOP counts, the added complexity actually makes these transformers slower than their vanilla ViT counterparts. In this paper, we argue that this additional bulk is unnecessary. By pretraining with a strong visual pretext task (MAE), we can strip out all the bells-and-whistles from a state-of-the-art multi-stage vision transformer without losing accuracy. In the process, we create Hiera, an extremely simple hierarchical vision transformer that is more accurate than previous models while being significantly faster both at inference and during training. We evaluate Hiera on a variety of tasks for image and video recognition. Our code and models are available at https://github.com/facebookresearch/hiera.
Occupancy Planes for Single-view RGB-D Human Reconstruction
Aug 04, 2022
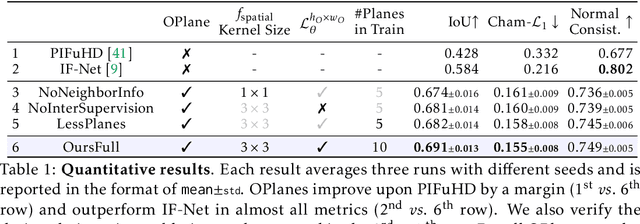
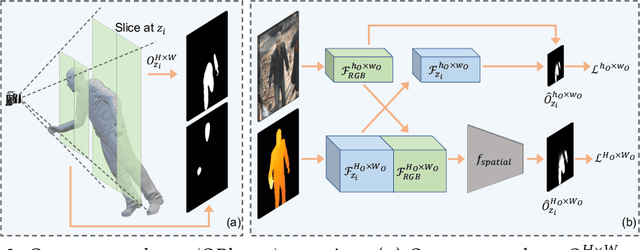
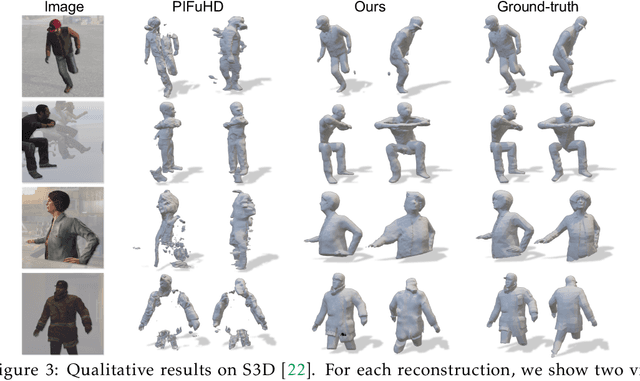
Single-view RGB-D human reconstruction with implicit functions is often formulated as per-point classification. Specifically, a set of 3D locations within the view-frustum of the camera are first projected independently onto the image and a corresponding feature is subsequently extracted for each 3D location. The feature of each 3D location is then used to classify independently whether the corresponding 3D point is inside or outside the observed object. This procedure leads to sub-optimal results because correlations between predictions for neighboring locations are only taken into account implicitly via the extracted features. For more accurate results we propose the occupancy planes (OPlanes) representation, which enables to formulate single-view RGB-D human reconstruction as occupancy prediction on planes which slice through the camera's view frustum. Such a representation provides more flexibility than voxel grids and enables to better leverage correlations than per-point classification. On the challenging S3D data we observe a simple classifier based on the OPlanes representation to yield compelling results, especially in difficult situations with partial occlusions due to other objects and partial visibility, which haven't been addressed by prior work.
Total Variation Optimization Layers for Computer Vision
Apr 07, 2022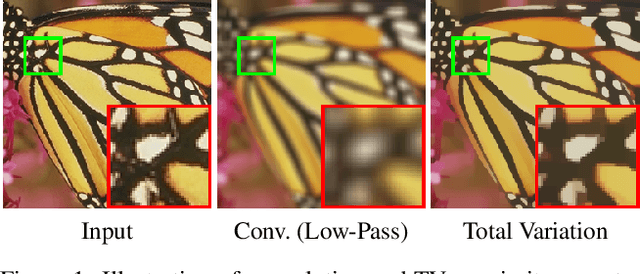



Optimization within a layer of a deep-net has emerged as a new direction for deep-net layer design. However, there are two main challenges when applying these layers to computer vision tasks: (a) which optimization problem within a layer is useful?; (b) how to ensure that computation within a layer remains efficient? To study question (a), in this work, we propose total variation (TV) minimization as a layer for computer vision. Motivated by the success of total variation in image processing, we hypothesize that TV as a layer provides useful inductive bias for deep-nets too. We study this hypothesis on five computer vision tasks: image classification, weakly supervised object localization, edge-preserving smoothing, edge detection, and image denoising, improving over existing baselines. To achieve these results we had to address question (b): we developed a GPU-based projected-Newton method which is $37\times$ faster than existing solutions.
Equivariance Discovery by Learned Parameter-Sharing
Apr 07, 2022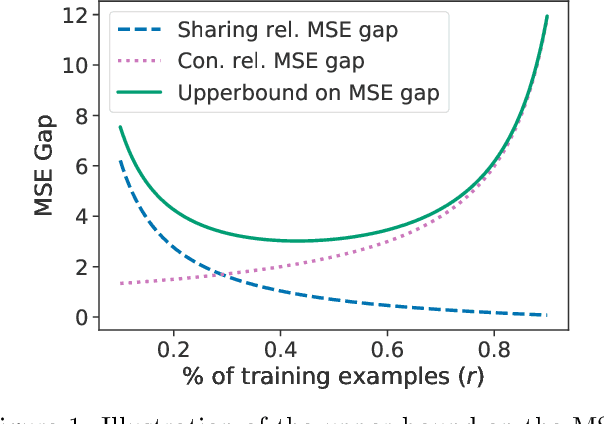
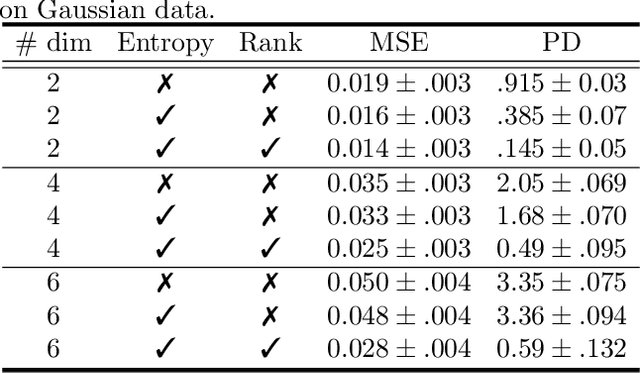
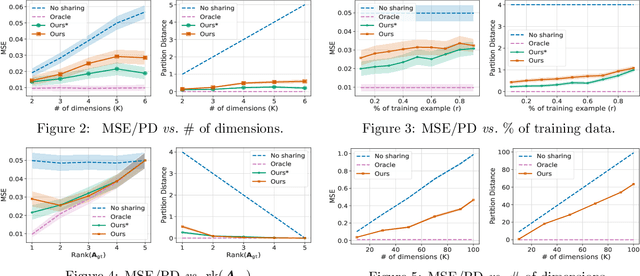
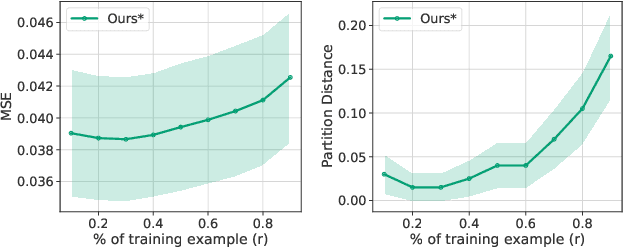
Designing equivariance as an inductive bias into deep-nets has been a prominent approach to build effective models, e.g., a convolutional neural network incorporates translation equivariance. However, incorporating these inductive biases requires knowledge about the equivariance properties of the data, which may not be available, e.g., when encountering a new domain. To address this, we study how to discover interpretable equivariances from data. Specifically, we formulate this discovery process as an optimization problem over a model's parameter-sharing schemes. We propose to use the partition distance to empirically quantify the accuracy of the recovered equivariance. Also, we theoretically analyze the method for Gaussian data and provide a bound on the mean squared gap between the studied discovery scheme and the oracle scheme. Empirically, we show that the approach recovers known equivariances, such as permutations and shifts, on sum of numbers and spatially-invariant data.
SAIL-VOS 3D: A Synthetic Dataset and Baselines for Object Detection and 3D Mesh Reconstruction from Video Data
May 18, 2021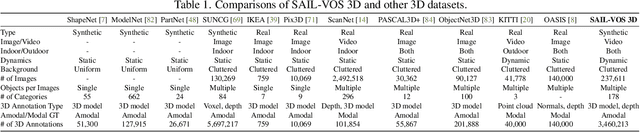
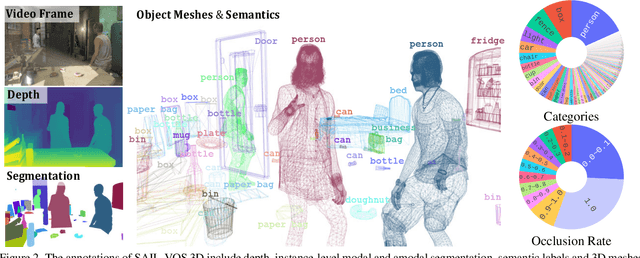

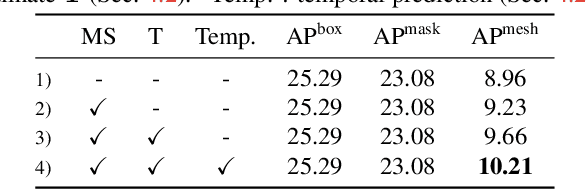
Extracting detailed 3D information of objects from video data is an important goal for holistic scene understanding. While recent methods have shown impressive results when reconstructing meshes of objects from a single image, results often remain ambiguous as part of the object is unobserved. Moreover, existing image-based datasets for mesh reconstruction don't permit to study models which integrate temporal information. To alleviate both concerns we present SAIL-VOS 3D: a synthetic video dataset with frame-by-frame mesh annotations which extends SAIL-VOS. We also develop first baselines for reconstruction of 3D meshes from video data via temporal models. We demonstrate efficacy of the proposed baseline on SAIL-VOS 3D and Pix3D, showing that temporal information improves reconstruction quality. Resources and additional information are available at http://sailvos.web.illinois.edu.
Chirality Nets for Human Pose Regression
Oct 31, 2019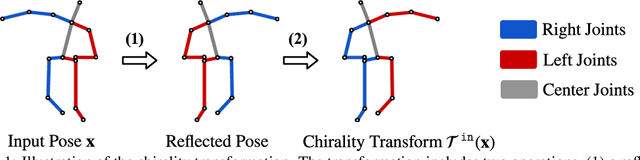
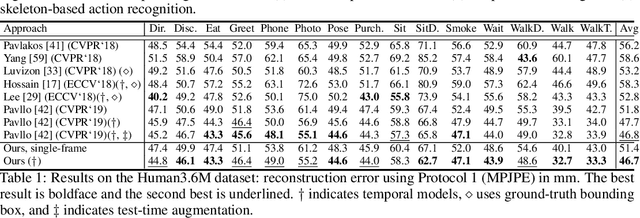
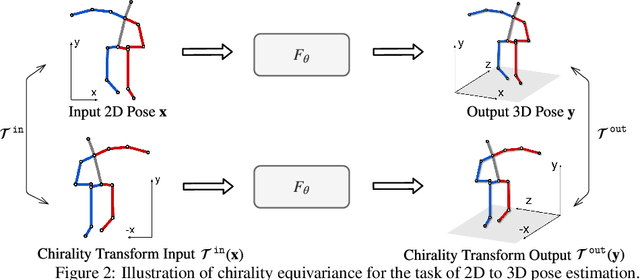

We propose Chirality Nets, a family of deep nets that is equivariant to the "chirality transform," i.e., the transformation to create a chiral pair. Through parameter sharing, odd and even symmetry, we propose and prove variants of standard building blocks of deep nets that satisfy the equivariance property, including fully connected layers, convolutional layers, batch-normalization, and LSTM/GRU cells. The proposed layers lead to a more data efficient representation and a reduction in computation by exploiting symmetry. We evaluate chirality nets on the task of human pose regression, which naturally exploits the left/right mirroring of the human body. We study three pose regression tasks: 3D pose estimation from video, 2D pose forecasting, and skeleton based activity recognition. Our approach achieves/matches state-of-the-art results, with more significant gains on small datasets and limited-data settings.
Max-Sliced Wasserstein Distance and its use for GANs
Apr 11, 2019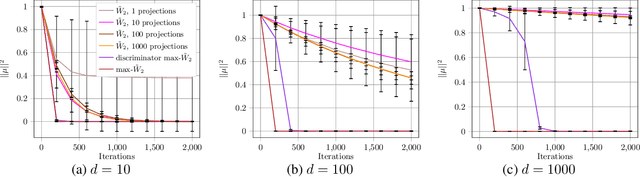

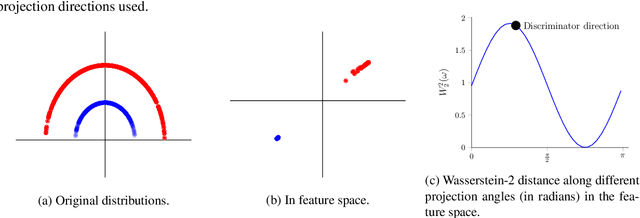

Generative adversarial nets (GANs) and variational auto-encoders have significantly improved our distribution modeling capabilities, showing promise for dataset augmentation, image-to-image translation and feature learning. However, to model high-dimensional distributions, sequential training and stacked architectures are common, increasing the number of tunable hyper-parameters as well as the training time. Nonetheless, the sample complexity of the distance metrics remains one of the factors affecting GAN training. We first show that the recently proposed sliced Wasserstein distance has compelling sample complexity properties when compared to the Wasserstein distance. To further improve the sliced Wasserstein distance we then analyze its `projection complexity' and develop the max-sliced Wasserstein distance which enjoys compelling sample complexity while reducing projection complexity, albeit necessitating a max estimation. We finally illustrate that the proposed distance trains GANs on high-dimensional images up to a resolution of 256x256 easily.
Unsupervised Video Object Segmentation using Motion Saliency-Guided Spatio-Temporal Propagation
Sep 04, 2018

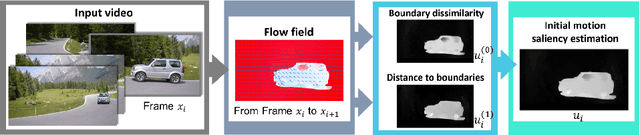
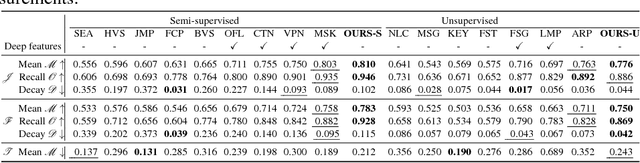
Unsupervised video segmentation plays an important role in a wide variety of applications from object identification to compression. However, to date, fast motion, motion blur and occlusions pose significant challenges. To address these challenges for unsupervised video segmentation, we develop a novel saliency estimation technique as well as a novel neighborhood graph, based on optical flow and edge cues. Our approach leads to significantly better initial foreground-background estimates and their robust as well as accurate diffusion across time. We evaluate our proposed algorithm on the challenging DAVIS, SegTrack v2 and FBMS-59 datasets. Despite the usage of only a standard edge detector trained on 200 images, our method achieves state-of-the-art results outperforming deep learning based methods in the unsupervised setting. We even demonstrate competitive results comparable to deep learning based methods in the semi-supervised setting on the DAVIS dataset.