 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXray-Visual Models: Scaling Vision models on Industry Scale Data
Feb 18, 2026We present Xray-Visual, a unified vision model architecture for large-scale image and video understanding trained on industry-scale social media data. Our model leverages over 15 billion curated image-text pairs and 10 billion video-hashtag pairs from Facebook and Instagram, employing robust data curation pipelines that incorporate balancing and noise suppression strategies to maximize semantic diversity while minimizing label noise. We introduce a three-stage training pipeline that combines self-supervised MAE, semi-supervised hashtag classification, and CLIP-style contrastive learning to jointly optimize image and video modalities. Our architecture builds on a Vision Transformer backbone enhanced with efficient token reorganization (EViT) for improved computational efficiency. Extensive experiments demonstrate that Xray-Visual achieves state-of-the-art performance across diverse benchmarks, including ImageNet for image classification, Kinetics and HMDB51 for video understanding, and MSCOCO for cross-modal retrieval. The model exhibits strong robustness to domain shift and adversarial perturbations. We further demonstrate that integrating large language models as text encoders (LLM2CLIP) significantly enhances retrieval performance and generalization capabilities, particularly in real-world environments. Xray-Visual establishes new benchmarks for scalable, multimodal vision models, while maintaining superior accuracy and computational efficiency.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles
Jun 01, 2023



Modern hierarchical vision transformers have added several vision-specific components in the pursuit of supervised classification performance. While these components lead to effective accuracies and attractive FLOP counts, the added complexity actually makes these transformers slower than their vanilla ViT counterparts. In this paper, we argue that this additional bulk is unnecessary. By pretraining with a strong visual pretext task (MAE), we can strip out all the bells-and-whistles from a state-of-the-art multi-stage vision transformer without losing accuracy. In the process, we create Hiera, an extremely simple hierarchical vision transformer that is more accurate than previous models while being significantly faster both at inference and during training. We evaluate Hiera on a variety of tasks for image and video recognition. Our code and models are available at https://github.com/facebookresearch/hiera.
Few-shot Image Classification: Just Use a Library of Pre-trained Feature Extractors and a Simple Classifier
Jan 03, 2021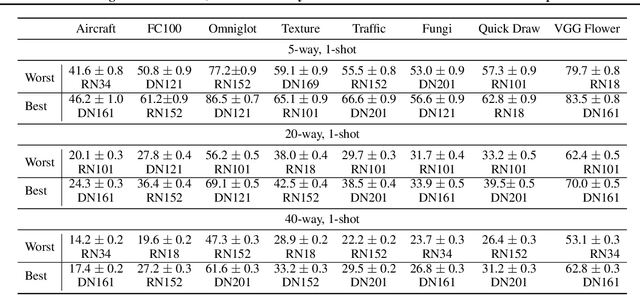
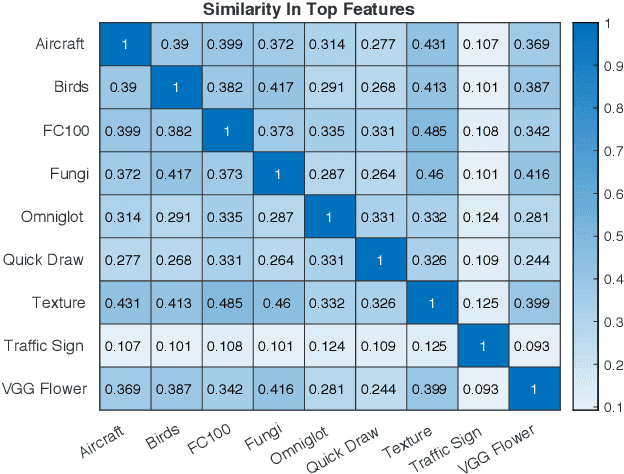
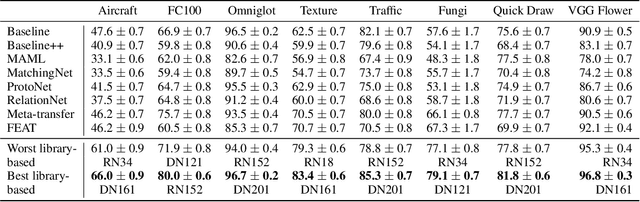

Recent papers have suggested that transfer learning can outperform sophisticated meta-learning methods for few-shot image classification. We take this hypothesis to its logical conclusion, and suggest the use of an ensemble of high-quality, pre-trained feature extractors for few-shot image classification. We show experimentally that a library of pre-trained feature extractors combined with a simple feed-forward network learned with an L2-regularizer can be an excellent option for solving cross-domain few-shot image classification. Our experimental results suggest that this simpler sample-efficient approach far outperforms several well-established meta-learning algorithms on a variety of few-shot tasks.
Meta-Meta-Classification for One-Shot Learning
May 12, 2020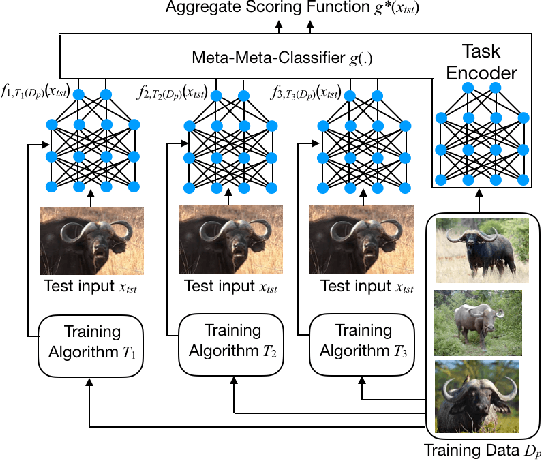
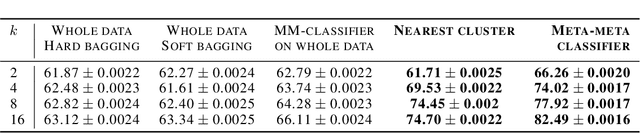
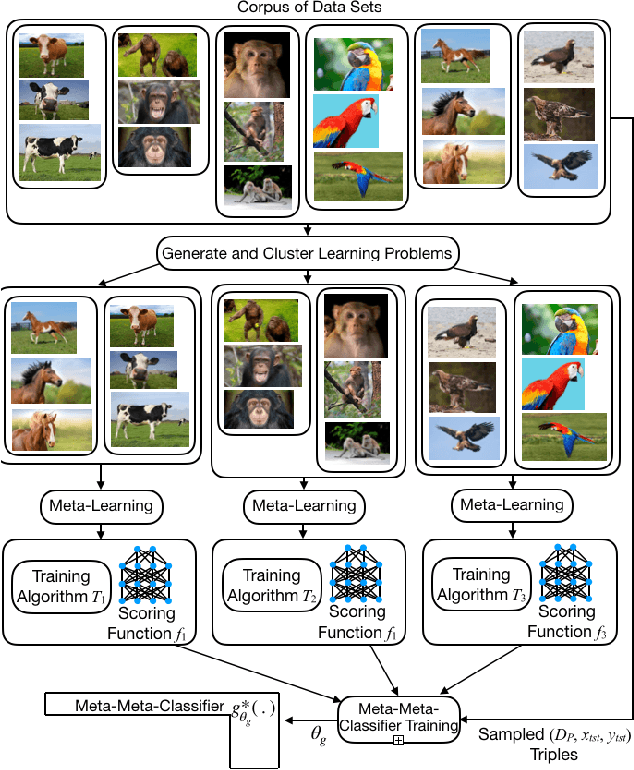

We present a new approach, called meta-meta-classification, to learning in small-data settings. In this approach, one uses a large set of learning problems to design an ensemble of learners, where each learner has high bias and low variance and is skilled at solving a specific type of learning problem. The meta-meta classifier learns how to examine a given learning problem and combine the various learners to solve the problem. The meta-meta-learning approach is especially suited to solving few-shot learning tasks, as it is easier to learn to classify a new learning problem with little data than it is to apply a learning algorithm to a small data set. We evaluate the approach on a one-shot, one-class-versus-all classification task and show that it is able to outperform traditional meta-learning as well as ensembling approaches.
Multi-modal dialog for browsing large visual catalogs using exploration-exploitation paradigm in a joint embedding space
Jan 29, 2019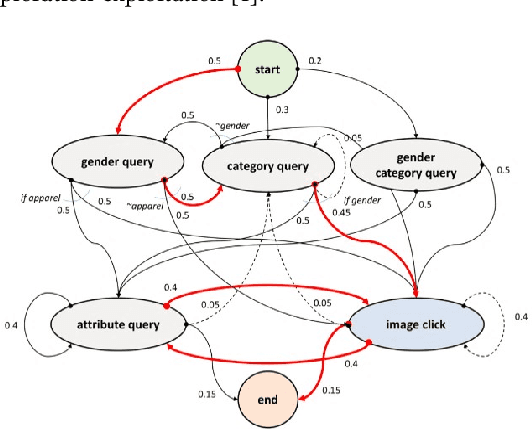
We present a multi-modal dialog system to assist online shoppers in visually browsing through large catalogs. Visual browsing is different from visual search in that it allows the user to explore the wide range of products in a catalog, beyond the exact search matches. We focus on a slightly asymmetric version of the complete multi-modal dialog where the system can understand both text and image queries but responds only in images. We formulate our problem of "showing $k$ best images to a user" based on the dialog context so far, as sampling from a Gaussian Mixture Model in a high dimensional joint multi-modal embedding space, that embed both the text and the image queries. Our system remembers the context of the dialog and uses an exploration-exploitation paradigm to assist in visual browsing. We train and evaluate the system on a multi-modal dialog dataset that we generate from large catalog data. Our experiments are promising and show that the agent is capable of learning and can display relevant results with an average cosine similarity of 0.85 to the ground truth. Our preliminary human evaluation also corroborates the fact that such a multi-modal dialog system for visual browsing is well-received and is capable of engaging human users.
An Evolutionary Approach to Drug-Design Using a Novel Neighbourhood Based Genetic Algorithm
May 03, 2012
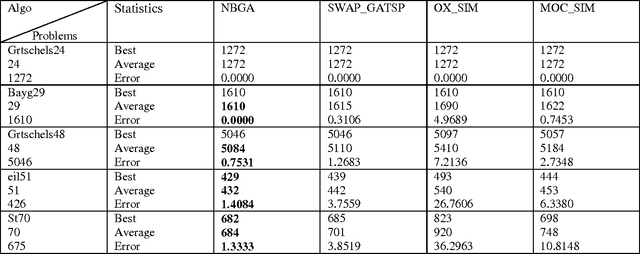
The present work provides a new approach to evolve ligand structures which represent possible drug to be docked to the active site of the target protein. The structure is represented as a tree where each non-empty node represents a functional group. It is assumed that the active site configuration of the target protein is known with position of the essential residues. In this paper the interaction energy of the ligands with the protein target is minimized. Moreover, the size of the tree is difficult to obtain and it will be different for different active sites. To overcome the difficulty, a variable tree size configuration is used for designing ligands. The optimization is done using a novel Neighbourhood Based Genetic Algorithm (NBGA) which uses dynamic neighbourhood topology. To get variable tree size, a variable-length version of the above algorithm is devised. To judge the merit of the algorithm, it is initially applied on the well known Travelling Salesman Problem (TSP).
Multi-robot Cooperative Box-pushing problem using Multi-objective Particle Swarm Optimization Technique
May 03, 2012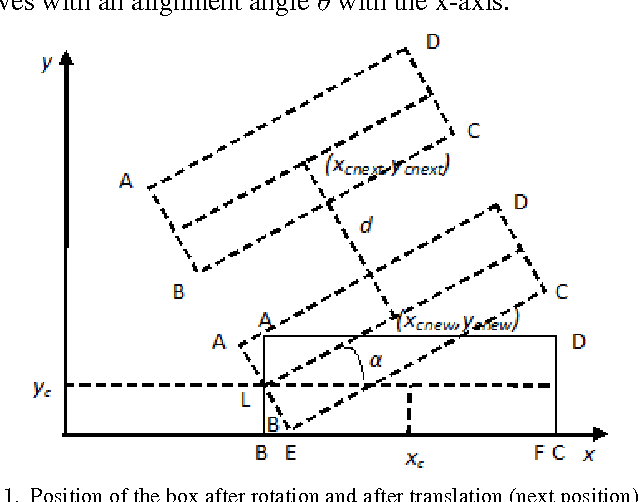
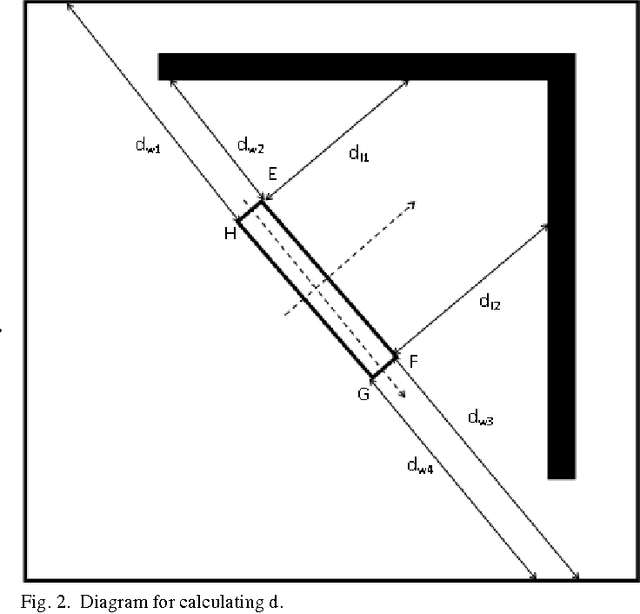
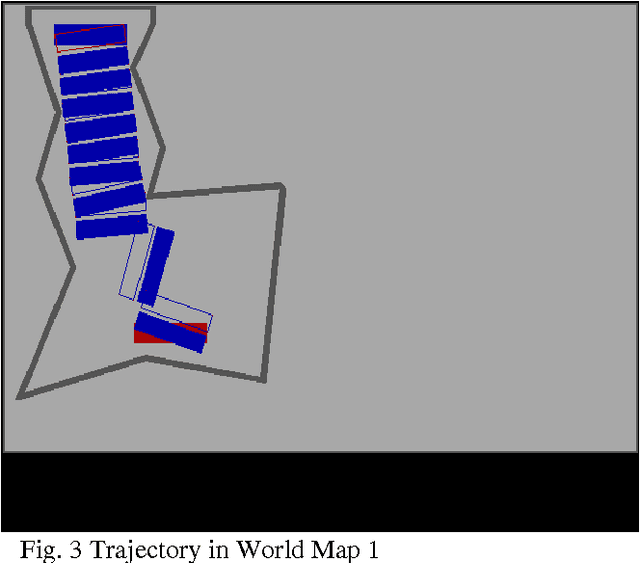
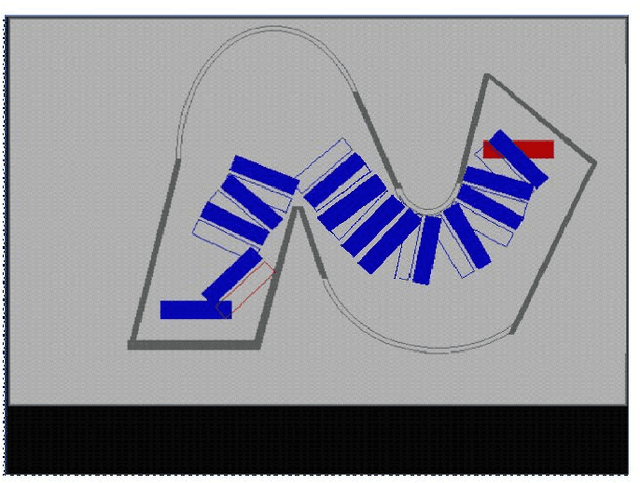
The present work provides a new approach to solve the well-known multi-robot co-operative box pushing problem as a multi objective optimization problem using modified Multi-objective Particle Swarm Optimization. The method proposed here allows both turning and translation of the box, during shift to a desired goal position. We have employed local planning scheme to determine the magnitude of the forces applied by the two mobile robots perpendicularly at specific locations on the box to align and translate it in each distinct step of motion of the box, for minimization of both time and energy. Finally the results are compared with the results obtained by solving the same problem using Non-dominated Sorting Genetic Algorithm-II (NSGA-II). The proposed scheme is found to give better results compared to NSGA-II.
An Evolutionary Approach to Drug-Design Using Quantam Binary Particle Swarm Optimization Algorithm
May 03, 2012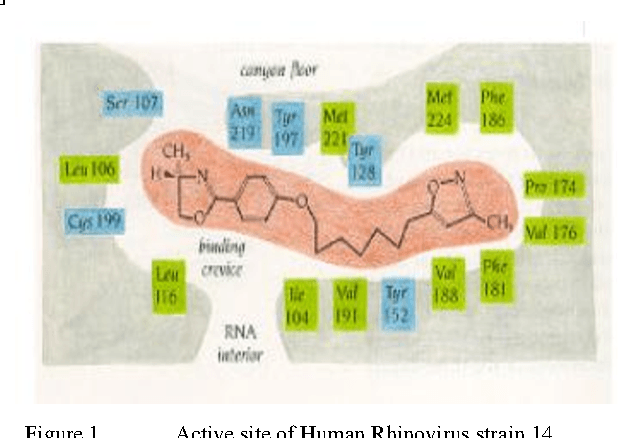
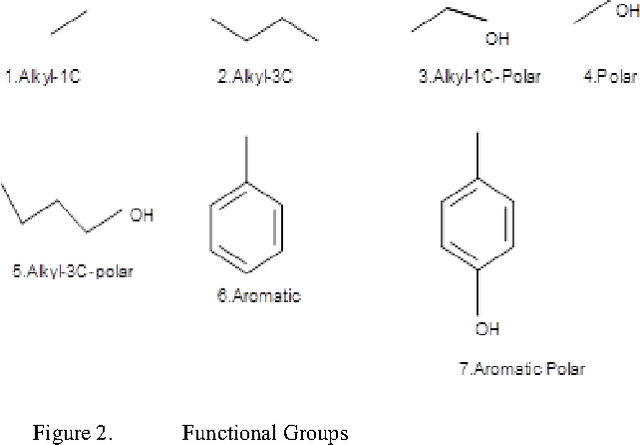
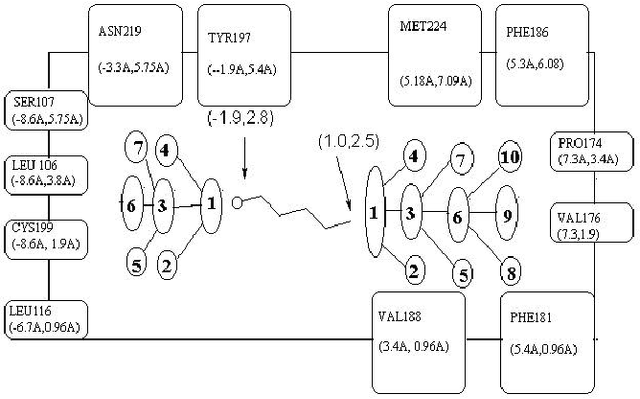
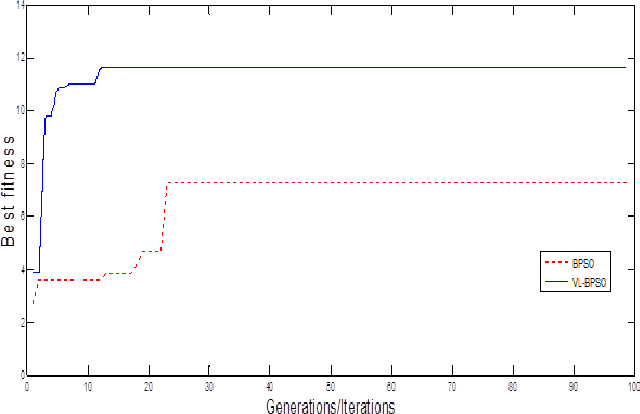
The present work provides a new approach to evolve ligand structures which represent possible drug to be docked to the active site of the target protein. The structure is represented as a tree where each non-empty node represents a functional group. It is assumed that the active site configuration of the target protein is known with position of the essential residues. In this paper the interaction energy of the ligands with the protein target is minimized. Moreover, the size of the tree is difficult to obtain and it will be different for different active sites. To overcome the difficulty, a variable tree size configuration is used for designing ligands. The optimization is done using a quantum discrete PSO. The result using fixed length and variable length configuration are compared.