 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Tensor-Relational Decomposition for Large-Scale Sparse Tensor Computation
Mar 09, 2026A \emph{tensor-relational} computation is a relational computation where individual tuples carry vectors, matrices, or higher-dimensional arrays. An advantage of tensor-relational computation is that the overall computation can be executed on top of a relational system, inheriting the system's ability to automatically handle very large inputs with high levels of sparsity while high-performance kernels (such as optimized matrix-matrix multiplication codes) can be used to perform most of the underlying mathematical operations. In this paper, we introduce upper-case-lower-case \texttt{EinSum}, which is a tensor-relational version of the classical Einstein Summation Notation. We study how to automatically rewrite a computation in Einstein Notation into upper-case-lower-case \texttt{EinSum} so that computationally intensive components are executed using efficient numerical kernels, while sparsity is managed relationally.
DOPPLER: Dual-Policy Learning for Device Assignment in Asynchronous Dataflow Graphs
May 29, 2025We study the problem of assigning operations in a dataflow graph to devices to minimize execution time in a work-conserving system, with emphasis on complex machine learning workloads. Prior learning-based methods often struggle due to three key limitations: (1) reliance on bulk-synchronous systems like TensorFlow, which under-utilize devices due to barrier synchronization; (2) lack of awareness of the scheduling mechanism of underlying systems when designing learning-based methods; and (3) exclusive dependence on reinforcement learning, ignoring the structure of effective heuristics designed by experts. In this paper, we propose \textsc{Doppler}, a three-stage framework for training dual-policy networks consisting of 1) a $\mathsf{SEL}$ policy for selecting operations and 2) a $\mathsf{PLC}$ policy for placing chosen operations on devices. Our experiments show that \textsc{Doppler} outperforms all baseline methods across tasks by reducing system execution time and additionally demonstrates sampling efficiency by reducing per-episode training time.
Resource-efficient Inference with Foundation Model Programs
Apr 09, 2025
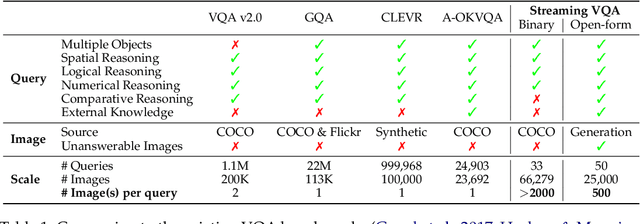
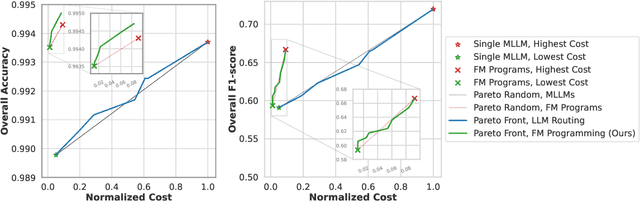
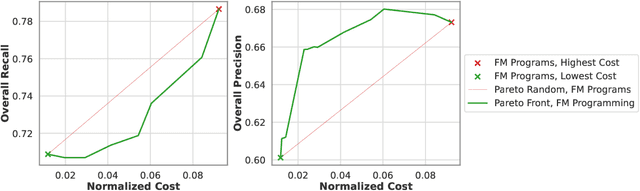
The inference-time resource costs of large language and vision models present a growing challenge in production deployments. We propose the use of foundation model programs, i.e., programs that can invoke foundation models with varying resource costs and performance, as an approach to this problem. Specifically, we present a method that translates a task into a program, then learns a policy for resource allocation that, on each input, selects foundation model "backends" for each program module. The policy uses smaller, cheaper backends to handle simpler subtasks, while allowing more complex subtasks to leverage larger, more capable models. We evaluate the method on two new "streaming" visual question-answering tasks in which a system answers a question on a sequence of inputs, receiving ground-truth feedback after each answer. Compared to monolithic multi-modal models, our implementation achieves up to 98% resource savings with minimal accuracy loss, demonstrating its potential for scalable and resource-efficient multi-modal inference.
Prompt Tuning Strikes Back: Customizing Foundation Models with Low-Rank Prompt Adaptation
May 24, 2024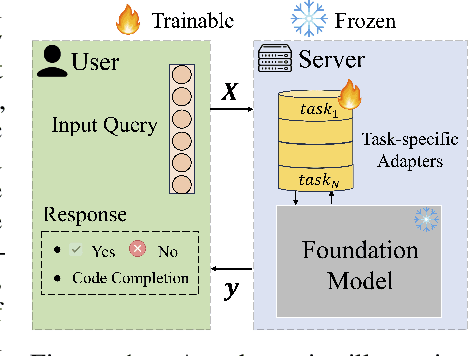
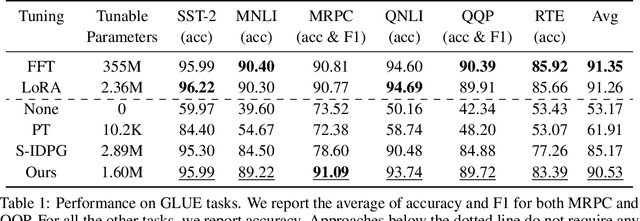
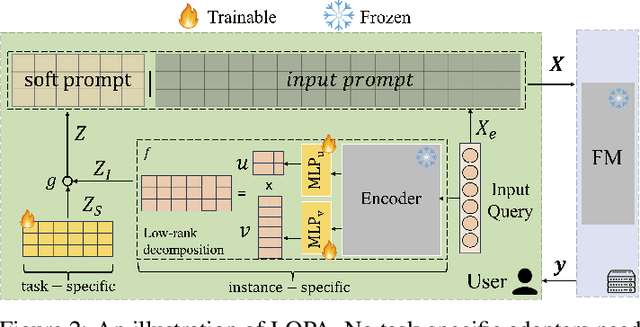
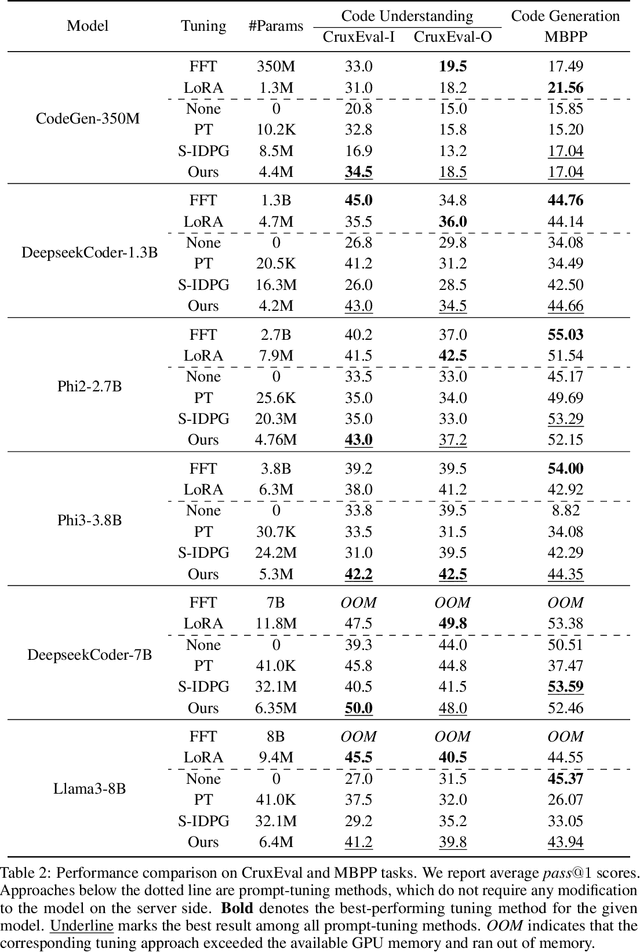
Parameter-Efficient Fine-Tuning (PEFT) has become the standard for customising Foundation Models (FMs) to user-specific downstream tasks. However, typical PEFT methods require storing multiple task-specific adapters, creating scalability issues as these adapters must be housed and run at the FM server. Traditional prompt tuning offers a potential solution by customising them through task-specific input prefixes, but it under-performs compared to other PEFT methods like LoRA. To address this gap, we propose Low-Rank Prompt Adaptation (LOPA), a prompt-tuning-based approach that performs on par with state-of-the-art PEFT methods and full fine-tuning while being more parameter-efficient and not requiring a server-based adapter. LOPA generates soft prompts by balancing between sharing task-specific information across instances and customization for each instance. It uses a low-rank decomposition of the soft-prompt component encoded for each instance to achieve parameter efficiency. We provide a comprehensive evaluation on multiple natural language understanding and code generation and understanding tasks across a wide range of foundation models with varying sizes.
Federated Learning Over Images: Vertical Decompositions and Pre-Trained Backbones Are Difficult to Beat
Sep 06, 2023We carefully evaluate a number of algorithms for learning in a federated environment, and test their utility for a variety of image classification tasks. We consider many issues that have not been adequately considered before: whether learning over data sets that do not have diverse sets of images affects the results; whether to use a pre-trained feature extraction "backbone"; how to evaluate learner performance (we argue that classification accuracy is not enough), among others. Overall, across a wide variety of settings, we find that vertically decomposing a neural network seems to give the best results, and outperforms more standard reconciliation-used methods.
Auto-Differentiation of Relational Computations for Very Large Scale Machine Learning
Jun 07, 2023The relational data model was designed to facilitate large-scale data management and analytics. We consider the problem of how to differentiate computations expressed relationally. We show experimentally that a relational engine running an auto-differentiated relational algorithm can easily scale to very large datasets, and is competitive with state-of-the-art, special-purpose systems for large-scale distributed machine learning.
Tuning Models of Code with Compiler-Generated Reinforcement Learning Feedback
May 25, 2023Large Language Models (LLMs) pre-trained on code have recently emerged as the dominant approach to program synthesis. However, the code that these models produce can violate basic language-level invariants, leading to lower performance in downstream tasks. We address this issue through an approach, called RLCF, that further trains a pre-trained LLM using feedback from a code compiler. RLCF views the LLM as an RL agent that generates code step by step and receives: (i) compiler-derived feedback on whether the code it generates passes a set of correctness checks; and (ii) feedback from a different LLM on whether the generated code is similar to a set of reference programs in the training corpus. Together, these feedback mechanisms help the generated code remain within the target distribution while passing all static correctness checks. RLCF is model- and language-agnostic. We empirically evaluate it on the MBJP and MathQA tasks for Java. Our experiments show that RLCF significantly raises the odds that an LLM-generated program compiles, is executable, and produces the right output on tests, often allowing LLMs to match the performance of 2x-8x larger LLMs.
LOFT: Finding Lottery Tickets through Filter-wise Training
Oct 28, 2022
Recent work on the Lottery Ticket Hypothesis (LTH) shows that there exist ``\textit{winning tickets}'' in large neural networks. These tickets represent ``sparse'' versions of the full model that can be trained independently to achieve comparable accuracy with respect to the full model. However, finding the winning tickets requires one to \emph{pretrain} the large model for at least a number of epochs, which can be a burdensome task, especially when the original neural network gets larger. In this paper, we explore how one can efficiently identify the emergence of such winning tickets, and use this observation to design efficient pretraining algorithms. For clarity of exposition, our focus is on convolutional neural networks (CNNs). To identify good filters, we propose a novel filter distance metric that well-represents the model convergence. As our theory dictates, our filter analysis behaves consistently with recent findings of neural network learning dynamics. Motivated by these observations, we present the \emph{LOttery ticket through Filter-wise Training} algorithm, dubbed as \textsc{LoFT}. \textsc{LoFT} is a model-parallel pretraining algorithm that partitions convolutional layers by filters to train them independently in a distributed setting, resulting in reduced memory and communication costs during pretraining. Experiments show that \textsc{LoFT} $i)$ preserves and finds good lottery tickets, while $ii)$ it achieves non-trivial computation and communication savings, and maintains comparable or even better accuracy than other pretraining methods.
Efficient and Light-Weight Federated Learning via Asynchronous Distributed Dropout
Oct 28, 2022


Asynchronous learning protocols have regained attention lately, especially in the Federated Learning (FL) setup, where slower clients can severely impede the learning process. Herein, we propose \texttt{AsyncDrop}, a novel asynchronous FL framework that utilizes dropout regularization to handle device heterogeneity in distributed settings. Overall, \texttt{AsyncDrop} achieves better performance compared to state of the art asynchronous methodologies, while resulting in less communication and training time overheads. The key idea revolves around creating ``submodels'' out of the global model, and distributing their training to workers, based on device heterogeneity. We rigorously justify that such an approach can be theoretically characterized. We implement our approach and compare it against other asynchronous baselines, both by design and by adapting existing synchronous FL algorithms to asynchronous scenarios. Empirically, \texttt{AsyncDrop} reduces the communication cost and training time, while matching or improving the final test accuracy in diverse non-i.i.d. FL scenarios.
Neural Program Generation Modulo Static Analysis
Nov 22, 2021
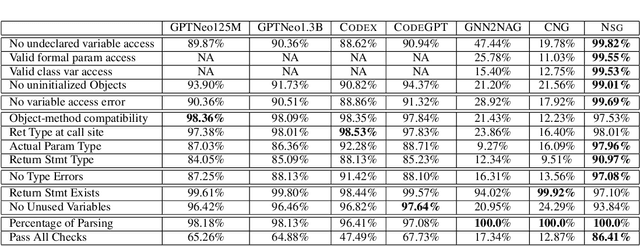
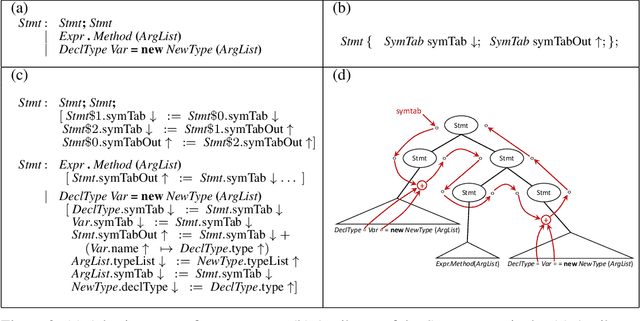

State-of-the-art neural models of source code tend to be evaluated on the generation of individual expressions and lines of code, and commonly fail on long-horizon tasks such as the generation of entire method bodies. We propose to address this deficiency using weak supervision from a static program analyzer. Our neurosymbolic method allows a deep generative model to symbolically compute, using calls to a static-analysis tool, long-distance semantic relationships in the code that it has already generated. During training, the model observes these relationships and learns to generate programs conditioned on them. We apply our approach to the problem of generating entire Java methods given the remainder of the class that contains the method. Our experiments show that the approach substantially outperforms state-of-the-art transformers and a model that explicitly tries to learn program semantics on this task, both in terms of producing programs free of basic semantic errors and in terms of syntactically matching the ground truth.