 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Dyadic Barrier: Rethinking Fairness in Link Prediction Beyond Demographic Parity
Nov 16, 2025Link prediction is a fundamental task in graph machine learning with applications, ranging from social recommendation to knowledge graph completion. Fairness in this setting is critical, as biased predictions can exacerbate societal inequalities. Prior work adopts a dyadic definition of fairness, enforcing fairness through demographic parity between intra-group and inter-group link predictions. However, we show that this dyadic framing can obscure underlying disparities across subgroups, allowing systemic biases to go undetected. Moreover, we argue that demographic parity does not meet desired properties for fairness assessment in ranking-based tasks such as link prediction. We formalize the limitations of existing fairness evaluations and propose a framework that enables a more expressive assessment. Additionally, we propose a lightweight post-processing method combined with decoupled link predictors that effectively mitigates bias and achieves state-of-the-art fairness-utility trade-offs.
DOPPLER: Dual-Policy Learning for Device Assignment in Asynchronous Dataflow Graphs
May 29, 2025We study the problem of assigning operations in a dataflow graph to devices to minimize execution time in a work-conserving system, with emphasis on complex machine learning workloads. Prior learning-based methods often struggle due to three key limitations: (1) reliance on bulk-synchronous systems like TensorFlow, which under-utilize devices due to barrier synchronization; (2) lack of awareness of the scheduling mechanism of underlying systems when designing learning-based methods; and (3) exclusive dependence on reinforcement learning, ignoring the structure of effective heuristics designed by experts. In this paper, we propose \textsc{Doppler}, a three-stage framework for training dual-policy networks consisting of 1) a $\mathsf{SEL}$ policy for selecting operations and 2) a $\mathsf{PLC}$ policy for placing chosen operations on devices. Our experiments show that \textsc{Doppler} outperforms all baseline methods across tasks by reducing system execution time and additionally demonstrates sampling efficiency by reducing per-episode training time.
Graph Anomaly Detection via Adaptive Test-time Representation Learning across Out-of-Distribution Domains
Feb 20, 2025Graph Anomaly Detection (GAD) has demonstrated great effectiveness in identifying unusual patterns within graph-structured data. However, while labeled anomalies are often scarce in emerging applications, existing supervised GAD approaches are either ineffective or not applicable when moved across graph domains due to distribution shifts and heterogeneous feature spaces. To address these challenges, we present AdaGraph-T3, a novel test-time training framework for cross-domain GAD. AdaGraph-T3 combines supervised and self-supervised learning during training while adapting to a new domain during test time using only self-supervised learning by leveraging a homophily-based affinity score that captures domain-invariant properties of anomalies. Our framework introduces four key innovations to cross-domain GAD: an effective self-supervision scheme, an attention-based mechanism that dynamically learns edge importance weights during message passing, domain-specific encoders for handling heterogeneous features, and class-aware regularization to address imbalance. Experiments across multiple cross-domain settings demonstrate that AdaGraph-T3 significantly outperforms existing approaches, achieving average improvements of over 6.6% in AUROC and 7.9% in AUPRC compared to the best competing model.
Attribute-Enhanced Similarity Ranking for Sparse Link Prediction
Nov 29, 2024



Link prediction is a fundamental problem in graph data. In its most realistic setting, the problem consists of predicting missing or future links between random pairs of nodes from the set of disconnected pairs. Graph Neural Networks (GNNs) have become the predominant framework for link prediction. GNN-based methods treat link prediction as a binary classification problem and handle the extreme class imbalance -- real graphs are very sparse -- by sampling (uniformly at random) a balanced number of disconnected pairs not only for training but also for evaluation. However, we show that the reported performance of GNNs for link prediction in the balanced setting does not translate to the more realistic imbalanced setting and that simpler topology-based approaches are often better at handling sparsity. These findings motivate Gelato, a similarity-based link-prediction method that applies (1) graph learning based on node attributes to enhance a topological heuristic, (2) a ranking loss for addressing class imbalance, and (3) a negative sampling scheme that efficiently selects hard training pairs via graph partitioning. Experiments show that Gelato outperforms existing GNN-based alternatives.
Better Fair than Sorry: Adversarial Missing Data Imputation for Fair GNNs
Nov 02, 2023



This paper addresses the problem of learning fair Graph Neural Networks (GNNs) under missing protected attributes. GNNs have achieved state-of-the-art results in many relevant tasks where decisions might disproportionately impact specific communities. However, existing work on fair GNNs assumes that either protected attributes are fully-observed or that the missing data imputation is fair. In practice, biases in the imputation will be propagated to the model outcomes, leading them to overestimate the fairness of their predictions. We address this challenge by proposing Better Fair than Sorry (BFtS), a fair missing data imputation model for protected attributes used by fair GNNs. The key design principle behind BFtS is that imputations should approximate the worst-case scenario for the fair GNN -- i.e. when optimizing fairness is the hardest. We implement this idea using a 3-player adversarial scheme where two adversaries collaborate against the fair GNN. Experiments using synthetic and real datasets show that BFtS often achieves a better fairness $\times$ accuracy trade-off than existing alternatives.
Robust Ante-hoc Graph Explainer using Bilevel Optimization
May 25, 2023



Explaining the decisions made by machine learning models for high-stakes applications is critical for increasing transparency and guiding improvements to these decisions. This is particularly true in the case of models for graphs, where decisions often depend on complex patterns combining rich structural and attribute data. While recent work has focused on designing so-called post-hoc explainers, the question of what constitutes a good explanation remains open. One intuitive property is that explanations should be sufficiently informative to enable humans to approximately reproduce the predictions given the data. However, we show that post-hoc explanations do not achieve this goal as their explanations are highly dependent on fixed model parameters (e.g., learned GNN weights). To address this challenge, this paper proposes RAGE (Robust Ante-hoc Graph Explainer), a novel and flexible ante-hoc explainer designed to discover explanations for a broad class of graph neural networks using bilevel optimization. RAGE is able to efficiently identify explanations that contain the full information needed for prediction while still enabling humans to rank these explanations based on their influence. Our experiments, based on graph classification and regression, show that RAGE explanations are more robust than existing post-hoc and ante-hoc approaches and often achieve similar or better accuracy than state-of-the-art models.
Link Prediction without Graph Neural Networks
May 23, 2023Link prediction, which consists of predicting edges based on graph features, is a fundamental task in many graph applications. As for several related problems, Graph Neural Networks (GNNs), which are based on an attribute-centric message-passing paradigm, have become the predominant framework for link prediction. GNNs have consistently outperformed traditional topology-based heuristics, but what contributes to their performance? Are there simpler approaches that achieve comparable or better results? To answer these questions, we first identify important limitations in how GNN-based link prediction methods handle the intrinsic class imbalance of the problem -- due to the graph sparsity -- in their training and evaluation. Moreover, we propose Gelato, a novel topology-centric framework that applies a topological heuristic to a graph enhanced by attribute information via graph learning. Our model is trained end-to-end with an N-pair loss on an unbiased training set to address class imbalance. Experiments show that Gelato is 145% more accurate, trains 11 times faster, infers 6,000 times faster, and has less than half of the trainable parameters compared to state-of-the-art GNNs for link prediction.
A Broader Picture of Random-walk Based Graph Embedding
Oct 24, 2021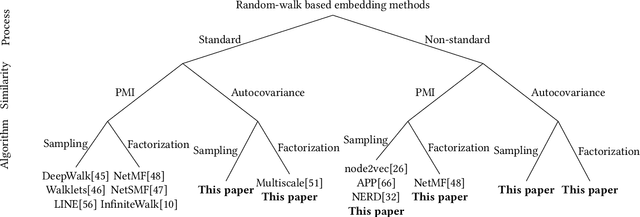
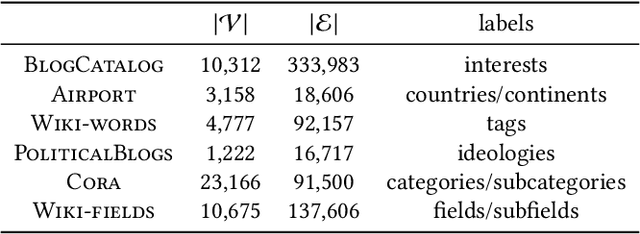
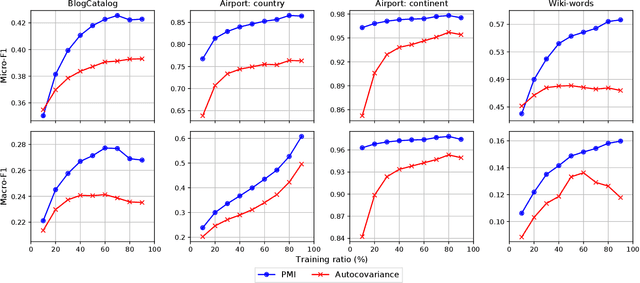
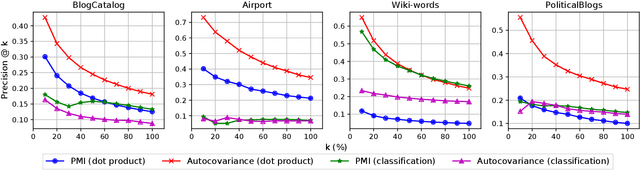
Graph embedding based on random-walks supports effective solutions for many graph-related downstream tasks. However, the abundance of embedding literature has made it increasingly difficult to compare existing methods and to identify opportunities to advance the state-of-the-art. Meanwhile, existing work has left several fundamental questions -- such as how embeddings capture different structural scales and how they should be applied for effective link prediction -- unanswered. This paper addresses these challenges with an analytical framework for random-walk based graph embedding that consists of three components: a random-walk process, a similarity function, and an embedding algorithm. Our framework not only categorizes many existing approaches but naturally motivates new ones. With it, we illustrate novel ways to incorporate embeddings at multiple scales to improve downstream task performance. We also show that embeddings based on autocovariance similarity, when paired with dot product ranking for link prediction, outperform state-of-the-art methods based on Pointwise Mutual Information similarity by up to 100%.
Event Detection on Dynamic Graphs
Oct 23, 2021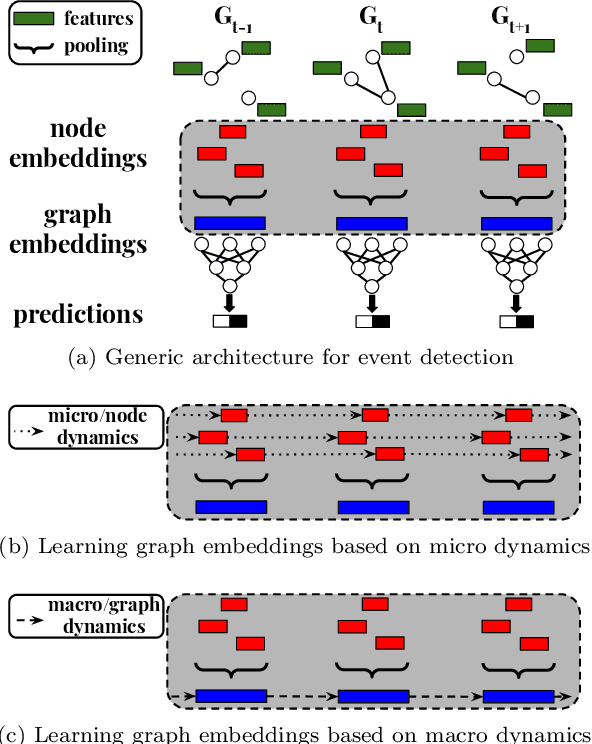
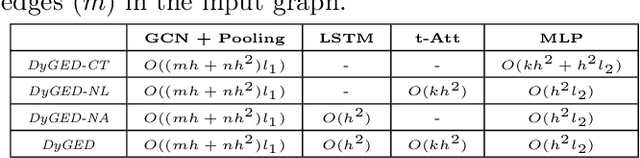
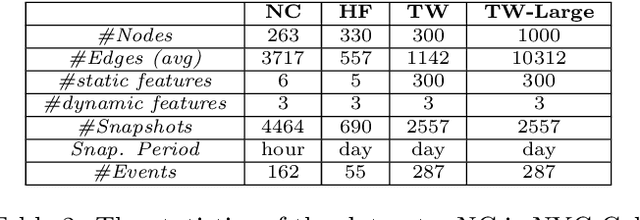
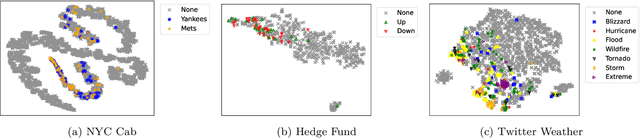
Event detection is a critical task for timely decision-making in graph analytics applications. Despite the recent progress towards deep learning on graphs, event detection on dynamic graphs presents particular challenges to existing architectures. Real-life events are often associated with sudden deviations of the normal behavior of the graph. However, existing approaches for dynamic node embedding are unable to capture the graph-level dynamics related to events. In this paper, we propose DyGED, a simple yet novel deep learning model for event detection on dynamic graphs. DyGED learns correlations between the graph macro dynamics -- i.e. a sequence of graph-level representations -- and labeled events. Moreover, our approach combines structural and temporal self-attention mechanisms to account for application-specific node and time importances effectively. Our experimental evaluation, using a representative set of datasets, demonstrates that DyGED outperforms competing solutions in terms of event detection accuracy by up to 8.5% while being more scalable than the top alternatives. We also present case studies illustrating key features of our model.
POLE: Polarized Embedding for Signed Networks
Oct 20, 2021
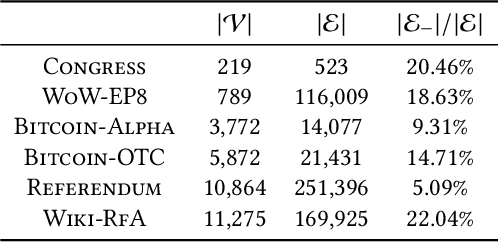
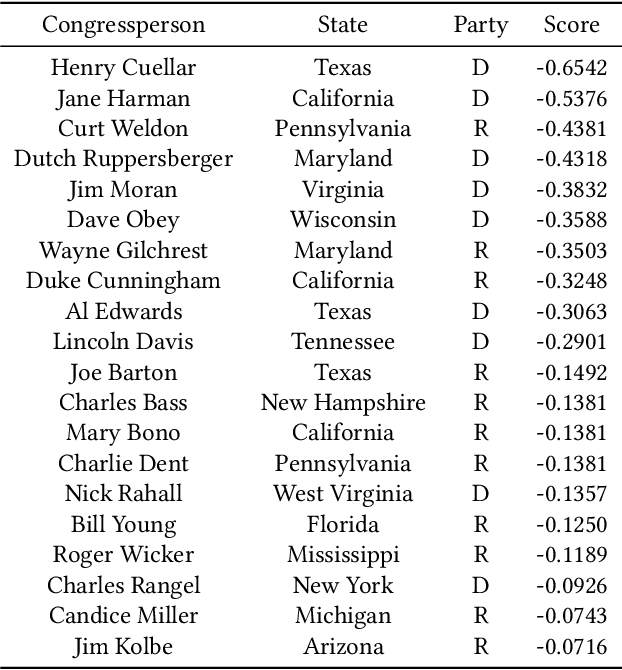
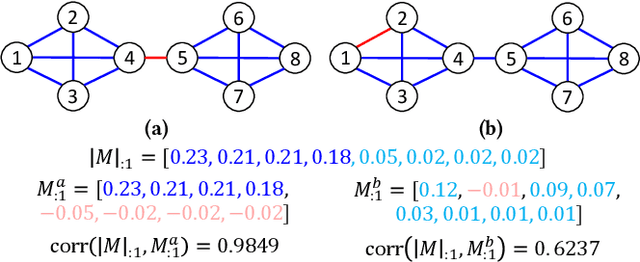
From the 2016 U.S. presidential election to the 2021 Capitol riots to the spread of misinformation related to COVID-19, many have blamed social media for today's deeply divided society. Recent advances in machine learning for signed networks hold the promise to guide small interventions with the goal of reducing polarization in social media. However, existing models are especially ineffective in predicting conflicts (or negative links) among users. This is due to a strong correlation between link signs and the network structure, where negative links between polarized communities are too sparse to be predicted even by state-of-the-art approaches. To address this problem, we first design a partition-agnostic polarization measure for signed graphs based on the signed random-walk and show that many real-world graphs are highly polarized. Then, we propose POLE (POLarized Embedding for signed networks), a signed embedding method for polarized graphs that captures both topological and signed similarities jointly via signed autocovariance. Through extensive experiments, we show that POLE significantly outperforms state-of-the-art methods in signed link prediction, particularly for negative links with gains of up to one order of magnitude.