 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampling-Based Winner Prediction in District-Based Elections
Feb 28, 2022In a district-based election, we apply a voting rule $r$ to decide the winners in each district, and a candidate who wins in a maximum number of districts is the winner of the election. We present efficient sampling-based algorithms to predict the winner of such district-based election systems in this paper. When $r$ is plurality and the margin of victory is known to be at least $\varepsilon$ fraction of the total population, we present an algorithm to predict the winner. The sample complexity of our algorithm is $\mathcal{O}\left(\frac{1}{\varepsilon^4}\log \frac{1}{\varepsilon}\log\frac{1}{\delta}\right)$. We complement this result by proving that any algorithm, from a natural class of algorithms, for predicting the winner in a district-based election when $r$ is plurality, must sample at least $\Omega\left(\frac{1}{\varepsilon^4}\log\frac{1}{\delta}\right)$ votes. We then extend this result to any voting rule $r$. Loosely speaking, we show that we can predict the winner of a district-based election with an extra overhead of $\mathcal{O}\left(\frac{1}{\varepsilon^2}\log\frac{1}{\delta}\right)$ over the sample complexity of predicting the single-district winner under $r$. We further extend our algorithm for the case when the margin of victory is unknown, but we have only two candidates. We then consider the median voting rule when the set of preferences in each district is single-peaked. We show that the winner of a district-based election can be predicted with $\mathcal{O}\left(\frac{1}{\varepsilon^4}\log\frac{1}{\varepsilon}\log\frac{1}{\delta}\right)$ samples even when the harmonious order in different districts can be different and even unknown. Finally, we also show some results for estimating the margin of victory of a district-based election within both additive and multiplicative error bounds.
Feature-based Individual Fairness in k-Clustering
Sep 09, 2021
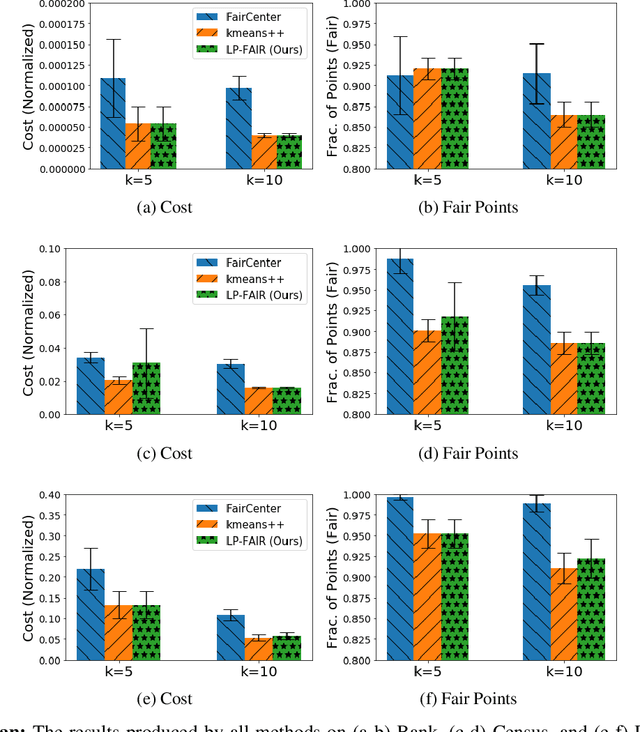
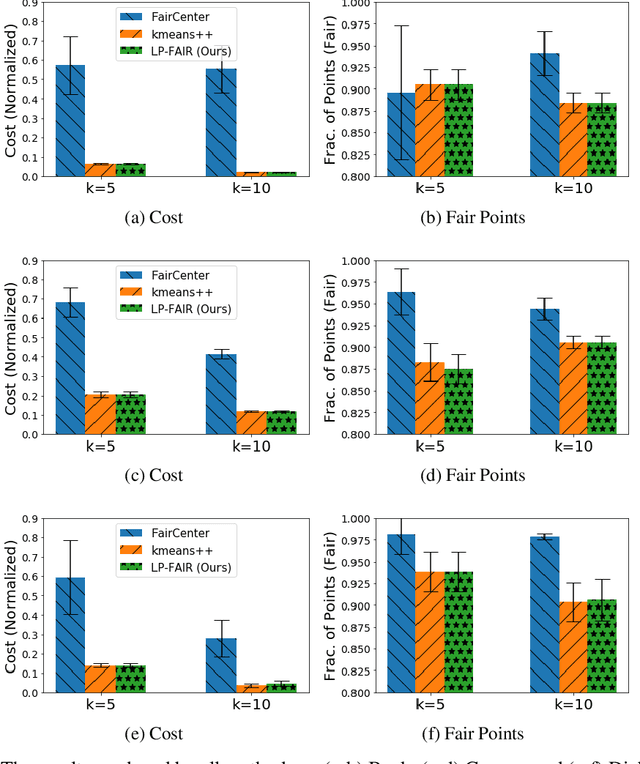

Ensuring fairness in machine learning algorithms is a challenging and important task. We consider the problem of clustering a set of points while ensuring fairness constraints. While there have been several attempts to capture group fairness in the k-clustering problem, fairness at an individual level is not well-studied. We introduce a new notion of individual fairness in k-clustering based on features that are not necessarily used for clustering. We show that this problem is NP-hard and does not admit a constant factor approximation. We then design a randomized algorithm that guarantees approximation both in terms of minimizing the clustering distance objective as well as individual fairness under natural restrictions on the distance metric and fairness constraints. Finally, our experimental results validate that our algorithm produces lower clustering costs compared to existing algorithms while being competitive in individual fairness.