 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEDM: Scalable Self-Evolving Distributed Memory for Agents
Sep 11, 2025Long-term multi-agent systems inevitably generate vast amounts of trajectories and historical interactions, which makes efficient memory management essential for both performance and scalability. Existing methods typically depend on vector retrieval and hierarchical storage, yet they are prone to noise accumulation, uncontrolled memory expansion, and limited generalization across domains. To address these challenges, we present SEDM, Self-Evolving Distributed Memory, a verifiable and adaptive framework that transforms memory from a passive repository into an active, self-optimizing component. SEDM integrates verifiable write admission based on reproducible replay, a self-scheduling memory controller that dynamically ranks and consolidates entries according to empirical utility, and cross-domain knowledge diffusion that abstracts reusable insights to support transfer across heterogeneous tasks. Evaluations on benchmark datasets demonstrate that SEDM improves reasoning accuracy while reducing token overhead compared with strong memory baselines, and further enables knowledge distilled from fact verification to enhance multi-hop reasoning. The results highlight SEDM as a scalable and sustainable memory mechanism for open-ended multi-agent collaboration. The code will be released in the later stage of this project.
Shop-R1: Rewarding LLMs to Simulate Human Behavior in Online Shopping via Reinforcement Learning
Jul 23, 2025

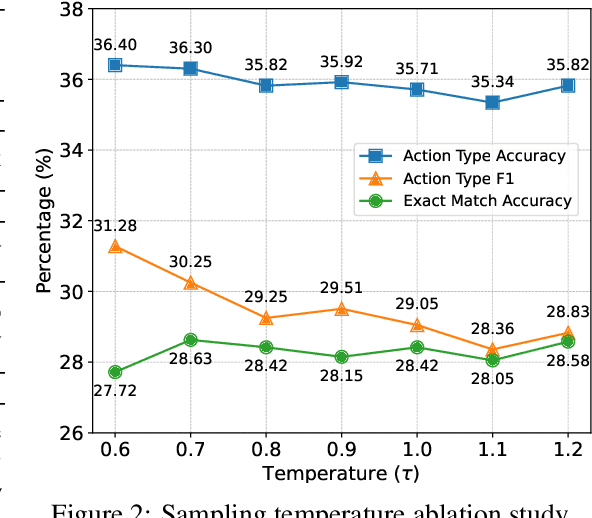

Large Language Models (LLMs) have recently demonstrated strong potential in generating 'believable human-like' behavior in web environments. Prior work has explored augmenting training data with LLM-synthesized rationales and applying supervised fine-tuning (SFT) to enhance reasoning ability, which in turn can improve downstream action prediction. However, the performance of such approaches remains inherently bounded by the reasoning capabilities of the model used to generate the rationales. In this paper, we introduce Shop-R1, a novel reinforcement learning (RL) framework aimed at enhancing the reasoning ability of LLMs for simulation of real human behavior in online shopping environments Specifically, Shop-R1 decomposes the human behavior simulation task into two stages: rationale generation and action prediction, each guided by distinct reward signals. For rationale generation, we leverage internal model signals (e.g., logit distributions) to guide the reasoning process in a self-supervised manner. For action prediction, we propose a hierarchical reward structure with difficulty-aware scaling to prevent reward hacking and enable fine-grained reward assignment. This design evaluates both high-level action types and the correctness of fine-grained sub-action details (attributes and values), rewarding outputs proportionally to their difficulty. Experimental results show that our method achieves a relative improvement of over 65% compared to the baseline.
DOPPLER: Dual-Policy Learning for Device Assignment in Asynchronous Dataflow Graphs
May 29, 2025We study the problem of assigning operations in a dataflow graph to devices to minimize execution time in a work-conserving system, with emphasis on complex machine learning workloads. Prior learning-based methods often struggle due to three key limitations: (1) reliance on bulk-synchronous systems like TensorFlow, which under-utilize devices due to barrier synchronization; (2) lack of awareness of the scheduling mechanism of underlying systems when designing learning-based methods; and (3) exclusive dependence on reinforcement learning, ignoring the structure of effective heuristics designed by experts. In this paper, we propose \textsc{Doppler}, a three-stage framework for training dual-policy networks consisting of 1) a $\mathsf{SEL}$ policy for selecting operations and 2) a $\mathsf{PLC}$ policy for placing chosen operations on devices. Our experiments show that \textsc{Doppler} outperforms all baseline methods across tasks by reducing system execution time and additionally demonstrates sampling efficiency by reducing per-episode training time.
COPU: Conformal Prediction for Uncertainty Quantification in Natural Language Generation
Feb 18, 2025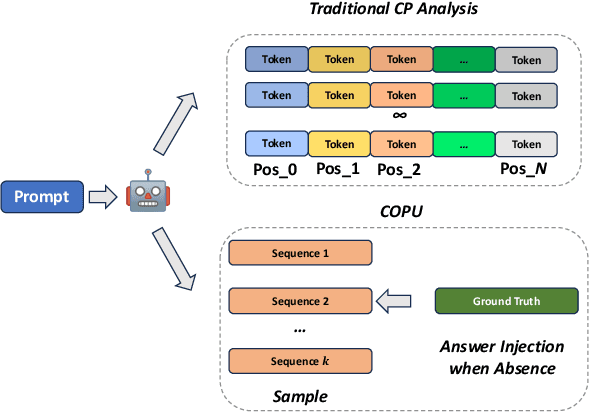
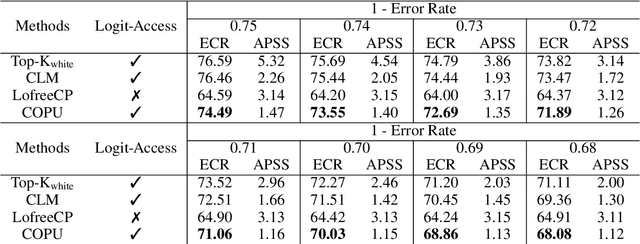


Uncertainty Quantification (UQ) for Natural Language Generation (NLG) is crucial for assessing the performance of Large Language Models (LLMs), as it reveals confidence in predictions, identifies failure modes, and gauges output reliability. Conformal Prediction (CP), a model-agnostic method that generates prediction sets with a specified error rate, has been adopted for UQ in classification tasks, where the size of the prediction set indicates the model's uncertainty. However, when adapting CP to NLG, the sampling-based method for generating candidate outputs cannot guarantee the inclusion of the ground truth, limiting its applicability across a wide range of error rates. To address this, we propose \ourmethod, a method that explicitly adds the ground truth to the candidate outputs and uses logit scores to measure nonconformity. Our experiments with six LLMs on four NLG tasks show that \ourmethod outperforms baseline methods in calibrating error rates and empirical cover rates, offering accurate UQ across a wide range of user-specified error rates.
SimCE: Simplifying Cross-Entropy Loss for Collaborative Filtering
Jun 23, 2024



The learning objective is integral to collaborative filtering systems, where the Bayesian Personalized Ranking (BPR) loss is widely used for learning informative backbones. However, BPR often experiences slow convergence and suboptimal local optima, partially because it only considers one negative item for each positive item, neglecting the potential impacts of other unobserved items. To address this issue, the recently proposed Sampled Softmax Cross-Entropy (SSM) compares one positive sample with multiple negative samples, leading to better performance. Our comprehensive experiments confirm that recommender systems consistently benefit from multiple negative samples during training. Furthermore, we introduce a \underline{Sim}plified Sampled Softmax \underline{C}ross-\underline{E}ntropy Loss (SimCE), which simplifies the SSM using its upper bound. Our validation on 12 benchmark datasets, using both MF and LightGCN backbones, shows that SimCE significantly outperforms both BPR and SSM.
Federated Learning Over Images: Vertical Decompositions and Pre-Trained Backbones Are Difficult to Beat
Sep 06, 2023We carefully evaluate a number of algorithms for learning in a federated environment, and test their utility for a variety of image classification tasks. We consider many issues that have not been adequately considered before: whether learning over data sets that do not have diverse sets of images affects the results; whether to use a pre-trained feature extraction "backbone"; how to evaluate learner performance (we argue that classification accuracy is not enough), among others. Overall, across a wide variety of settings, we find that vertically decomposing a neural network seems to give the best results, and outperforms more standard reconciliation-used methods.
Auto-Differentiation of Relational Computations for Very Large Scale Machine Learning
Jun 07, 2023The relational data model was designed to facilitate large-scale data management and analytics. We consider the problem of how to differentiate computations expressed relationally. We show experimentally that a relational engine running an auto-differentiated relational algorithm can easily scale to very large datasets, and is competitive with state-of-the-art, special-purpose systems for large-scale distributed machine learning.
Chain-Of-Thought Prompting Under Streaming Batch: A Case Study
Jun 01, 2023


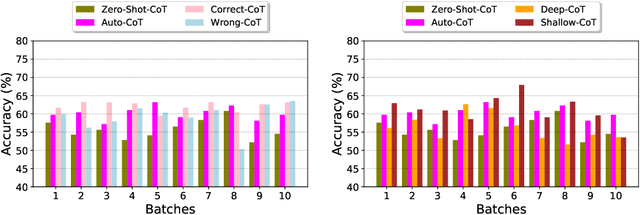
Recently, Large Language Models (LLMs) have demonstrated remarkable capabilities. Chain-of-Thought (CoT) has been proposed as a way of assisting LLMs in performing complex reasoning. However, developing effective prompts can be a challenging and labor-intensive task. Many studies come out of some way to automatically construct CoT from test data. Most of them assume that all test data is visible before testing and only select a small subset to generate rationales, which is an unrealistic assumption. In this paper, we present a case study on how to construct and optimize chain-of-thought prompting using batch data in streaming settings.
Compress, Then Prompt: Improving Accuracy-Efficiency Trade-off of LLM Inference with Transferable Prompt
May 17, 2023Large Language Models (LLMs), armed with billions of parameters, exhibit exceptional performance across a wide range of Natural Language Processing (NLP) tasks. However, they present a significant computational challenge during inference, especially when deploying on common hardware such as single GPUs. As such, minimizing the latency of LLM inference by curtailing computational and memory requirements, though achieved through compression, becomes critically important. However, this process inevitably instigates a trade-off between efficiency and accuracy, as compressed LLMs typically experience a reduction in predictive precision. In this research, we introduce an innovative perspective: to optimize this trade-off, compressed LLMs require a unique input format that varies from that of the original models. Our findings indicate that the generation quality in a compressed LLM can be markedly improved for specific queries by selecting prompts with precision. Capitalizing on this insight, we introduce a prompt learning paradigm that cultivates an additive prompt over a compressed LLM to bolster their accuracy. Our empirical results imply that through our strategic prompt utilization, compressed LLMs can match, and occasionally even exceed, the accuracy of the original models. Moreover, we demonstrated that these learned prompts have a certain degree of transferability across various datasets, tasks, and compression levels. These insights shine a light on new possibilities for enhancing the balance between accuracy and efficiency in LLM inference. Specifically, they underscore the importance of judicious input editing to a compressed large model, hinting at potential advancements in scaling LLMs on common hardware.
Federated Multiple Label Hashing (FedMLH): Communication Efficient Federated Learning on Extreme Classification Tasks
Oct 23, 2021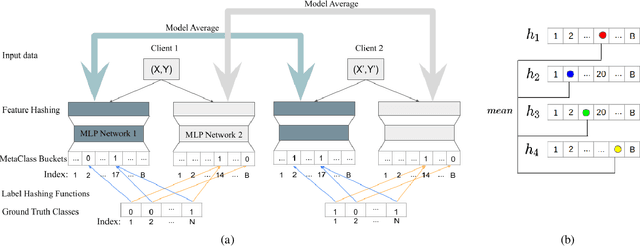



Federated learning enables many local devices to train a deep learning model jointly without sharing the local data. Currently, most of federated training schemes learns a global model by averaging the parameters of local models. However, most of these training schemes suffer from high communication cost resulted from transmitting full local model parameters. Moreover, directly averaging model parameters leads to a significant performance degradation, due to the class-imbalanced non-iid data on different devices. Especially for the real life federated learning tasks involving extreme classification, (1) communication becomes the main bottleneck since the model size increases proportionally to the number of output classes; (2) extreme classification (such as user recommendation) normally have extremely imbalanced classes and heterogeneous data on different devices. To overcome this problem, we propose federated multiple label hashing (FedMLH), which leverages label hashing to simultaneously reduce the model size (up to 3.40X decrease) with communication cost (up to 18.75X decrease) and achieves significant better accuracy (up to 35.5%} relative accuracy improvement) and faster convergence rate (up to 5.5X increase) for free on the federated extreme classification tasks compared to federated average algorithm.