 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Difference Grounding with Natural Language
Apr 02, 2025Visual grounding (VG) typically focuses on locating regions of interest within an image using natural language, and most existing VG methods are limited to single-image interpretations. This limits their applicability in real-world scenarios like automatic surveillance, where detecting subtle but meaningful visual differences across multiple images is crucial. Besides, previous work on image difference understanding (IDU) has either focused on detecting all change regions without cross-modal text guidance, or on providing coarse-grained descriptions of differences. Therefore, to push towards finer-grained vision-language perception, we propose Image Difference Grounding (IDG), a task designed to precisely localize visual differences based on user instructions. We introduce DiffGround, a large-scale and high-quality dataset for IDG, containing image pairs with diverse visual variations along with instructions querying fine-grained differences. Besides, we present a baseline model for IDG, DiffTracker, which effectively integrates feature differential enhancement and common suppression to precisely locate differences. Experiments on the DiffGround dataset highlight the importance of our IDG dataset in enabling finer-grained IDU. To foster future research, both DiffGround data and DiffTracker model will be publicly released.
ChatSearch: a Dataset and a Generative Retrieval Model for General Conversational Image Retrieval
Oct 24, 2024
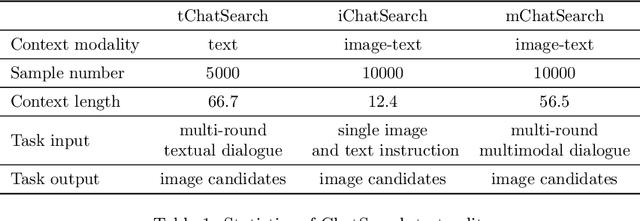
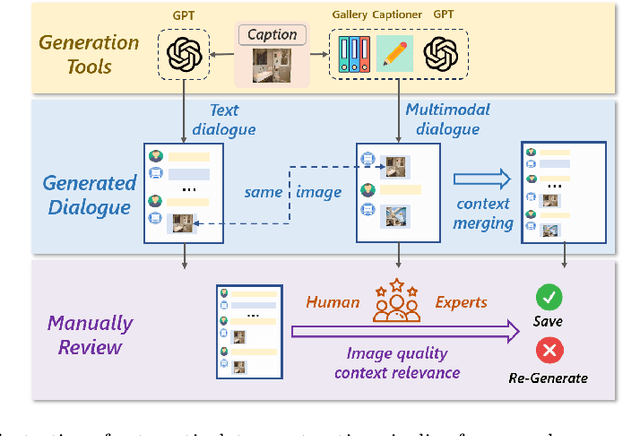
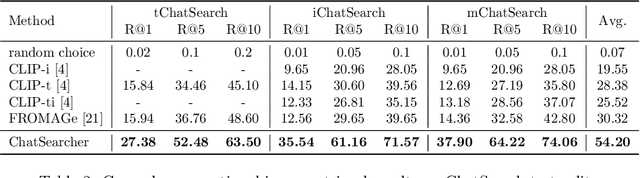
In this paper, we investigate the task of general conversational image retrieval on open-domain images. The objective is to search for images based on interactive conversations between humans and computers. To advance this task, we curate a dataset called ChatSearch. This dataset includes a multi-round multimodal conversational context query for each target image, thereby requiring the retrieval system to find the accurate image from database. Simultaneously, we propose a generative retrieval model named ChatSearcher, which is trained end-to-end to accept/produce interleaved image-text inputs/outputs. ChatSearcher exhibits strong capability in reasoning with multimodal context and can leverage world knowledge to yield visual retrieval results. It demonstrates superior performance on the ChatSearch dataset and also achieves competitive results on other image retrieval tasks and visual conversation tasks. We anticipate that this work will inspire further research on interactive multimodal retrieval systems. Our dataset will be available at https://github.com/joez17/ChatSearch.
OneDiff: A Generalist Model for Image Difference
Jul 08, 2024



In computer vision, Image Difference Captioning (IDC) is crucial for accurately describing variations between closely related images. Traditional IDC methods often rely on specialist models, which restrict their applicability across varied contexts. This paper introduces the OneDiff model, a novel generalist approach that utilizes a robust vision-language model architecture, integrating a siamese image encoder with a Visual Delta Module. This innovative configuration allows for the precise detection and articulation of fine-grained differences between image pairs. OneDiff is trained through a dual-phase strategy, encompassing Coupled Sample Training and multi-task learning across a diverse array of data types, supported by our newly developed DiffCap Dataset. This dataset merges real-world and synthetic data, enhancing the training process and bolstering the model's robustness. Extensive testing on diverse IDC benchmarks, such as Spot-the-Diff, CLEVR-Change, and Birds-to-Words, shows that OneDiff consistently outperforms existing state-of-the-art models in accuracy and adaptability, achieving improvements of up to 85\% CIDEr points in average. By setting a new benchmark in IDC, OneDiff paves the way for more versatile and effective applications in detecting and describing visual differences. The code, models, and data will be made publicly available.
Online Cascade Learning for Efficient Inference over Streams
Feb 07, 2024



Large Language Models (LLMs) have a natural role in answering complex queries about data streams, but the high computational cost of LLM inference makes them infeasible in many such tasks. We propose online cascade learning, the first approach to addressing this challenge. The objective here is to learn a "cascade" of models, starting with lower-capacity models (such as logistic regressors) and ending with a powerful LLM, along with a deferral policy that determines the model that is used on a given input. We formulate the task of learning cascades online as an imitation-learning problem and give a no-regret algorithm for the problem. Experimental results across four benchmarks show that our method parallels LLMs in accuracy while cutting down inference costs by as much as 90%, underscoring its efficacy and adaptability in stream processing.
Federated Learning Over Images: Vertical Decompositions and Pre-Trained Backbones Are Difficult to Beat
Sep 06, 2023We carefully evaluate a number of algorithms for learning in a federated environment, and test their utility for a variety of image classification tasks. We consider many issues that have not been adequately considered before: whether learning over data sets that do not have diverse sets of images affects the results; whether to use a pre-trained feature extraction "backbone"; how to evaluate learner performance (we argue that classification accuracy is not enough), among others. Overall, across a wide variety of settings, we find that vertically decomposing a neural network seems to give the best results, and outperforms more standard reconciliation-used methods.