 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOPPLER: Dual-Policy Learning for Device Assignment in Asynchronous Dataflow Graphs
May 29, 2025We study the problem of assigning operations in a dataflow graph to devices to minimize execution time in a work-conserving system, with emphasis on complex machine learning workloads. Prior learning-based methods often struggle due to three key limitations: (1) reliance on bulk-synchronous systems like TensorFlow, which under-utilize devices due to barrier synchronization; (2) lack of awareness of the scheduling mechanism of underlying systems when designing learning-based methods; and (3) exclusive dependence on reinforcement learning, ignoring the structure of effective heuristics designed by experts. In this paper, we propose \textsc{Doppler}, a three-stage framework for training dual-policy networks consisting of 1) a $\mathsf{SEL}$ policy for selecting operations and 2) a $\mathsf{PLC}$ policy for placing chosen operations on devices. Our experiments show that \textsc{Doppler} outperforms all baseline methods across tasks by reducing system execution time and additionally demonstrates sampling efficiency by reducing per-episode training time.
Resource-efficient Inference with Foundation Model Programs
Apr 09, 2025
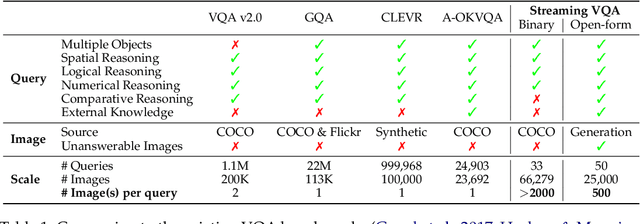
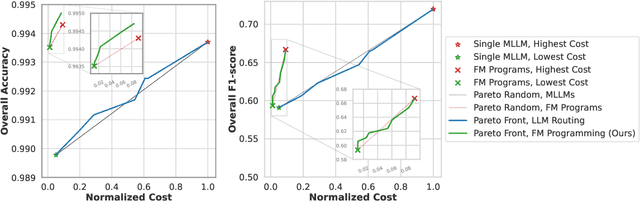
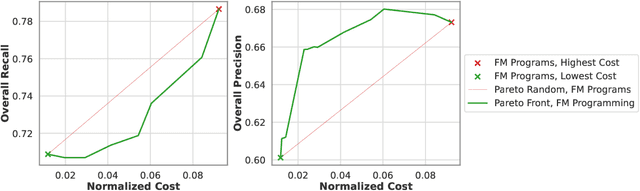
The inference-time resource costs of large language and vision models present a growing challenge in production deployments. We propose the use of foundation model programs, i.e., programs that can invoke foundation models with varying resource costs and performance, as an approach to this problem. Specifically, we present a method that translates a task into a program, then learns a policy for resource allocation that, on each input, selects foundation model "backends" for each program module. The policy uses smaller, cheaper backends to handle simpler subtasks, while allowing more complex subtasks to leverage larger, more capable models. We evaluate the method on two new "streaming" visual question-answering tasks in which a system answers a question on a sequence of inputs, receiving ground-truth feedback after each answer. Compared to monolithic multi-modal models, our implementation achieves up to 98% resource savings with minimal accuracy loss, demonstrating its potential for scalable and resource-efficient multi-modal inference.
Online Cascade Learning for Efficient Inference over Streams
Feb 07, 2024



Large Language Models (LLMs) have a natural role in answering complex queries about data streams, but the high computational cost of LLM inference makes them infeasible in many such tasks. We propose online cascade learning, the first approach to addressing this challenge. The objective here is to learn a "cascade" of models, starting with lower-capacity models (such as logistic regressors) and ending with a powerful LLM, along with a deferral policy that determines the model that is used on a given input. We formulate the task of learning cascades online as an imitation-learning problem and give a no-regret algorithm for the problem. Experimental results across four benchmarks show that our method parallels LLMs in accuracy while cutting down inference costs by as much as 90%, underscoring its efficacy and adaptability in stream processing.
Auto-Differentiation of Relational Computations for Very Large Scale Machine Learning
Jun 07, 2023The relational data model was designed to facilitate large-scale data management and analytics. We consider the problem of how to differentiate computations expressed relationally. We show experimentally that a relational engine running an auto-differentiated relational algorithm can easily scale to very large datasets, and is competitive with state-of-the-art, special-purpose systems for large-scale distributed machine learning.