 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource-efficient Inference with Foundation Model Programs
Apr 09, 2025
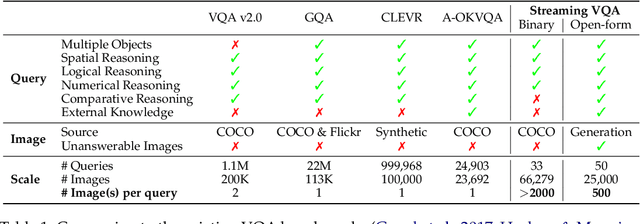
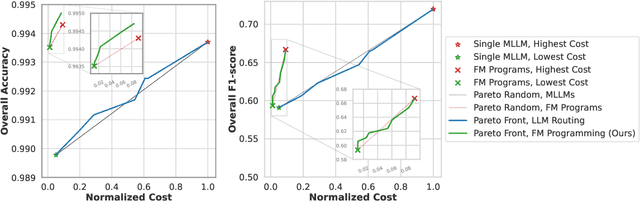
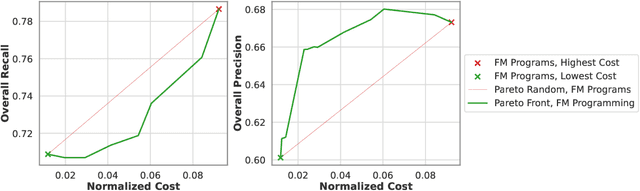
The inference-time resource costs of large language and vision models present a growing challenge in production deployments. We propose the use of foundation model programs, i.e., programs that can invoke foundation models with varying resource costs and performance, as an approach to this problem. Specifically, we present a method that translates a task into a program, then learns a policy for resource allocation that, on each input, selects foundation model "backends" for each program module. The policy uses smaller, cheaper backends to handle simpler subtasks, while allowing more complex subtasks to leverage larger, more capable models. We evaluate the method on two new "streaming" visual question-answering tasks in which a system answers a question on a sequence of inputs, receiving ground-truth feedback after each answer. Compared to monolithic multi-modal models, our implementation achieves up to 98% resource savings with minimal accuracy loss, demonstrating its potential for scalable and resource-efficient multi-modal inference.