 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-Differentiation of Relational Computations for Very Large Scale Machine Learning
Jun 07, 2023The relational data model was designed to facilitate large-scale data management and analytics. We consider the problem of how to differentiate computations expressed relationally. We show experimentally that a relational engine running an auto-differentiated relational algorithm can easily scale to very large datasets, and is competitive with state-of-the-art, special-purpose systems for large-scale distributed machine learning.
Tensor Relational Algebra for Machine Learning System Design
Oct 01, 2020
Machine learning (ML) systems have to support various tensor operations. However, such ML systems were largely developed without asking: what are the foundational abstractions necessary for building machine learning systems? We believe that proper computational and implementation abstractions will allow for the construction of self-configuring, declarative ML systems, especially when the goal is to execute tensor operations in a distributed environment, or partitioned across multiple AI accelerators (ASICs). To this end, we first introduce a tensor relational algebra (TRA), which is expressive to encode any tensor operation that can be written in the Einstein notation. We consider how TRA expressions can be re-written into an implementation algebra (IA) that enables effective implementation in a distributed environment, as well as how expressions in the IA can be optimized. Our empirical study shows that the optimized implementation provided by IA can reach or even out-perform carefully engineered HPC or ML systems for large scale tensor manipulations and ML workflows in distributed clusters.
Declarative Recursive Computation on an RDBMS, or, Why You Should Use a Database For Distributed Machine Learning
Apr 25, 2019

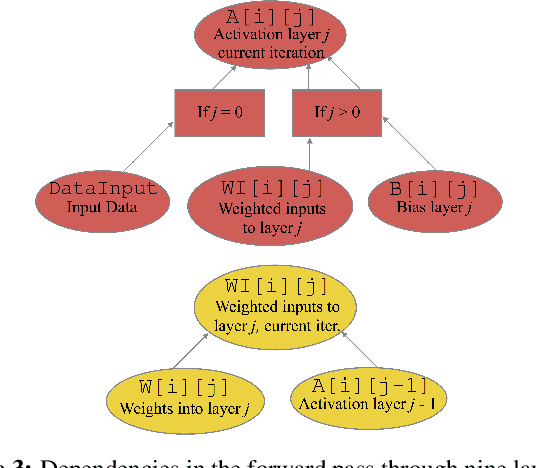
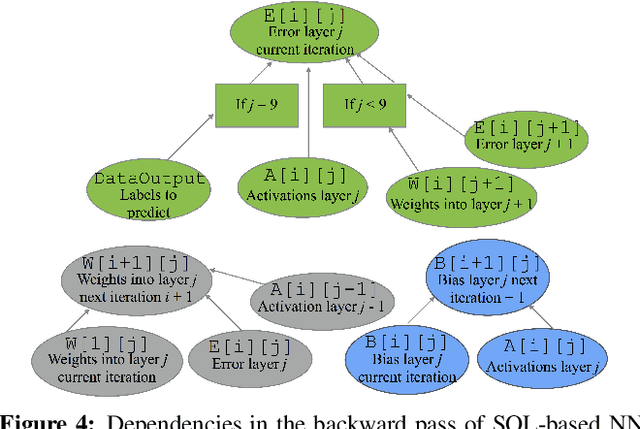
A number of popular systems, most notably Google's TensorFlow, have been implemented from the ground up to support machine learning tasks. We consider how to make a very small set of changes to a modern relational database management system (RDBMS) to make it suitable for distributed learning computations. Changes include adding better support for recursion, and optimization and execution of very large compute plans. We also show that there are key advantages to using an RDBMS as a machine learning platform. In particular, learning based on a database management system allows for trivial scaling to large data sets and especially large models, where different computational units operate on different parts of a model that may be too large to fit into RAM.