 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDNet: A Novel Dataset for Identity Document Analysis and Fraud Detection
Aug 03, 2024
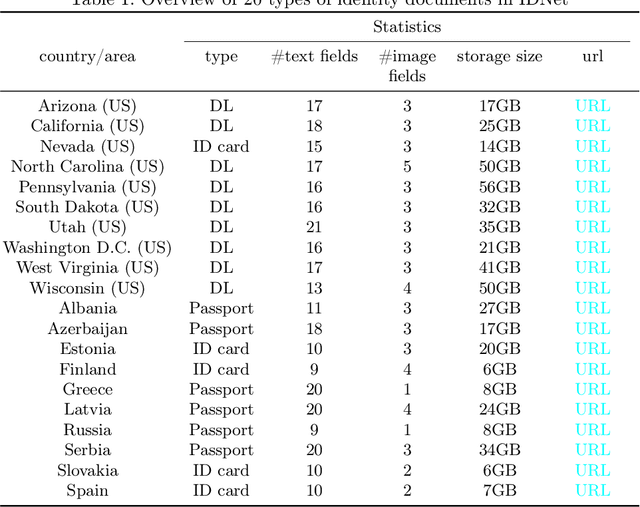


Effective fraud detection and analysis of government-issued identity documents, such as passports, driver's licenses, and identity cards, are essential in thwarting identity theft and bolstering security on online platforms. The training of accurate fraud detection and analysis tools depends on the availability of extensive identity document datasets. However, current publicly available benchmark datasets for identity document analysis, including MIDV-500, MIDV-2020, and FMIDV, fall short in several respects: they offer a limited number of samples, cover insufficient varieties of fraud patterns, and seldom include alterations in critical personal identifying fields like portrait images, limiting their utility in training models capable of detecting realistic frauds while preserving privacy. In response to these shortcomings, our research introduces a new benchmark dataset, IDNet, designed to advance privacy-preserving fraud detection efforts. The IDNet dataset comprises 837,060 images of synthetically generated identity documents, totaling approximately 490 gigabytes, categorized into 20 types from $10$ U.S. states and 10 European countries. We evaluate the utility and present use cases of the dataset, illustrating how it can aid in training privacy-preserving fraud detection methods, facilitating the generation of camera and video capturing of identity documents, and testing schema unification and other identity document management functionalities.
FGeo-HyperGNet: Geometry Problem Solving Integrating Formal Symbolic System and Hypergraph Neural Network
Feb 18, 2024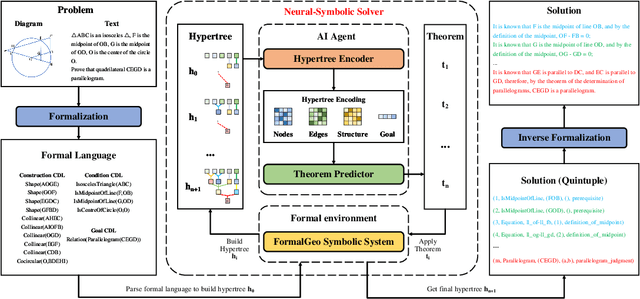
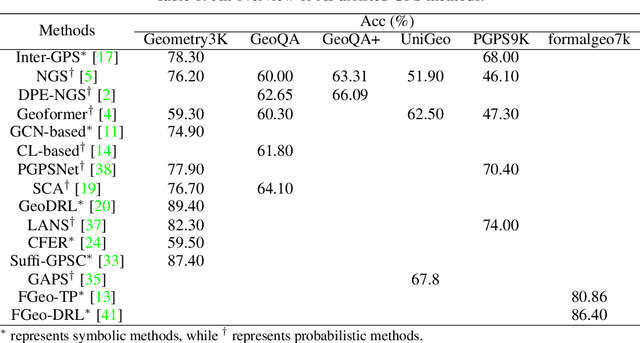
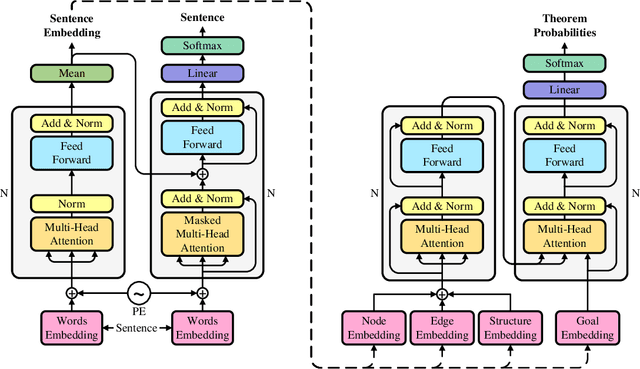
Geometry problem solving has always been a long-standing challenge in the fields of automated reasoning and artificial intelligence. This is the fifth article in a series of our works, we built a neural-symbolic system to automatically perform human-like geometric deductive reasoning. The symbolic part is a formal system built on FormalGeo, which can automatically perform geomertic relational reasoning and algebraic calculations and organize the solving process into a solution hypertree with conditions as hypernodes and theorems as hyperedges. The neural part, called HyperGNet, is a hypergraph neural network based on the attention mechanism, including a encoder to effectively encode the structural and semantic information of the hypertree, and a solver to provide problem-solving guidance. The neural part predicts theorems according to the hypertree, and the symbolic part applies theorems and updates the hypertree, thus forming a Predict-Apply Cycle to ultimately achieve readable and traceable automatic solving of geometric problems. Experiments demonstrate the correctness and effectiveness of this neural-symbolic architecture. We achieved a step-wised accuracy of 87.65% and an overall accuracy of 85.53% on the formalgeo7k datasets. The code and data is available at https://github.com/BitSecret/HyperGNet.
FGeo-DRL: Deductive Reasoning for Geometric Problems through Deep Reinforcement Learning
Feb 15, 2024



The human-like automatic deductive reasoning has always been one of the most challenging open problems in the interdiscipline of mathematics and artificial intelligence. This paper is the third in a series of our works. We built a neural-symbolic system, called FGeoDRL, to automatically perform human-like geometric deductive reasoning. The neural part is an AI agent based on reinforcement learning, capable of autonomously learning problem-solving methods from the feedback of a formalized environment, without the need for human supervision. It leverages a pre-trained natural language model to establish a policy network for theorem selection and employ Monte Carlo Tree Search for heuristic exploration. The symbolic part is a reinforcement learning environment based on geometry formalization theory and FormalGeo, which models GPS as a Markov Decision Process. In this formal symbolic system, the known conditions and objectives of the problem form the state space, while the set of theorems forms the action space. Leveraging FGeoDRL, we have achieved readable and verifiable automated solutions to geometric problems. Experiments conducted on the formalgeo7k dataset have achieved a problem-solving success rate of 86.40%. The project is available at https://github.com/PersonNoName/FGeoDRL.
FGeo-TP: A Language Model-Enhanced Solver for Geometry Problems
Feb 14, 2024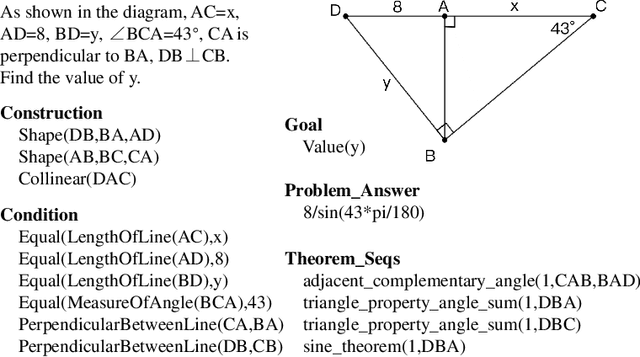
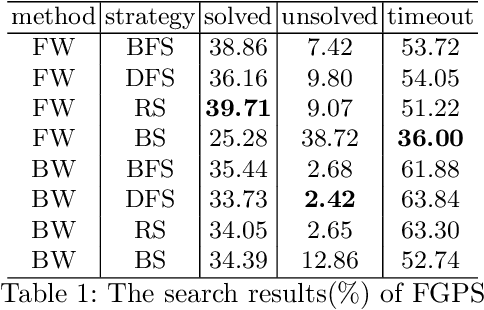
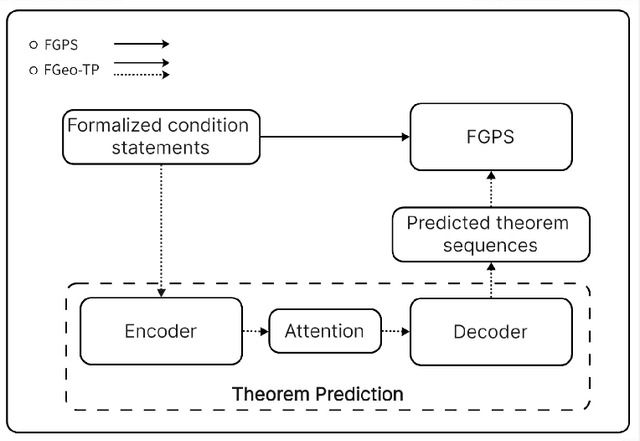
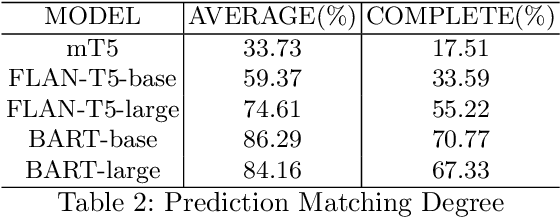
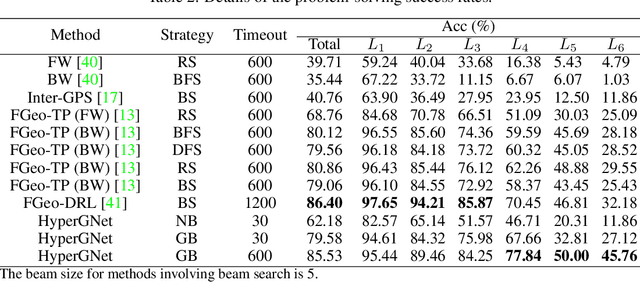
The application of contemporary artificial intelligence techniques to address geometric problems and automated deductive proof has always been a grand challenge to the interdiscipline field of mathematics and artificial Intelligence. This is the fourth article in a series of our works, in our previous work, we established of a geometric formalized system known as FormalGeo. Moreover we annotated approximately 7000 geometric problems, forming the FormalGeo7k dataset. Despite the FGPS (Formal Geometry Problem Solver) can achieve interpretable algebraic equation solving and human-like deductive reasoning, it often experiences timeouts due to the complexity of the search strategy. In this paper, we introduced FGeo-TP (Theorem Predictor), which utilizes the language model to predict theorem sequences for solving geometry problems. We compared the effectiveness of various Transformer architectures, such as BART or T5, in theorem prediction, implementing pruning in the search process of FGPS, thereby improving its performance in solving geometry problems. Our results demonstrate a significant increase in the problem-solving rate of the language model-enhanced FGeo-TP on the FormalGeo7k dataset, rising from 39.7% to 80.86%. Furthermore, FGeo-TP exhibits notable reductions in solving time and search steps across problems of varying difficulty levels.
A Learning-based Declarative Privacy-Preserving Framework for Federated Data Management
Jan 22, 2024It is challenging to balance the privacy and accuracy for federated query processing over multiple private data silos. In this work, we will demonstrate an end-to-end workflow for automating an emerging privacy-preserving technique that uses a deep learning model trained using the Differentially-Private Stochastic Gradient Descent (DP-SGD) algorithm to replace portions of actual data to answer a query. Our proposed novel declarative privacy-preserving workflow allows users to specify "what private information to protect" rather than "how to protect". Under the hood, the system automatically chooses query-model transformation plans as well as hyper-parameters. At the same time, the proposed workflow also allows human experts to review and tune the selected privacy-preserving mechanism for audit/compliance, and optimization purposes.
FormalGeo: The First Step Toward Human-like IMO-level Geometric Automated Reasoning
Oct 30, 2023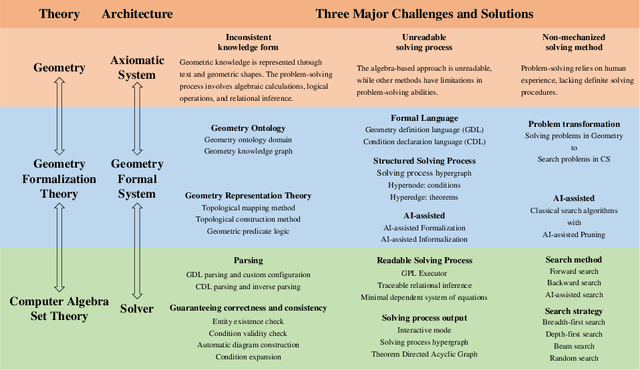
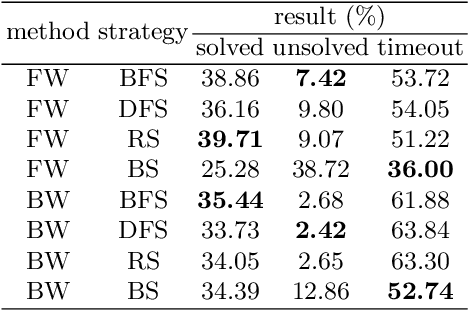
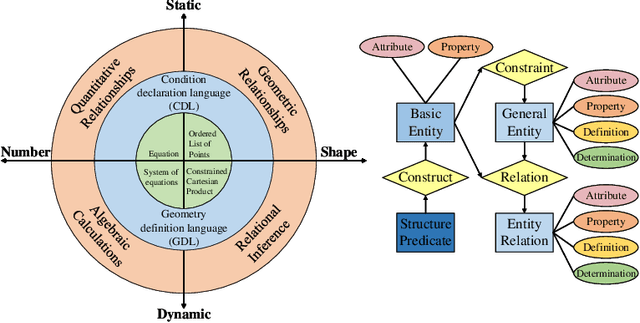
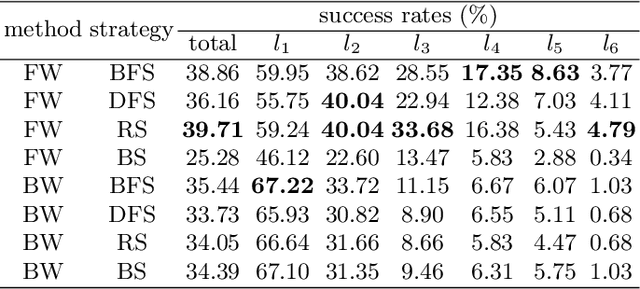
This is the first paper in a series of work we have accomplished over the past three years. In this paper, we have constructed a complete and compatible formal plane geometry system. This will serve as a crucial bridge between IMO-level plane geometry challenges and readable AI automated reasoning. With this formal system in place, we have been able to seamlessly integrate modern AI models with our formal system. Within this formal framework, AI is now capable of providing deductive reasoning solutions to IMO-level plane geometry problems, just like handling other natural languages, and these proofs are readable, traceable, and verifiable. We propose the geometry formalization theory (GFT) to guide the development of the geometry formal system. Based on the GFT, we have established the FormalGeo, which consists of 88 geometric predicates and 196 theorems. It can represent, validate, and solve IMO-level geometry problems. we also have crafted the FGPS (formal geometry problem solver) in Python. It serves as both an interactive assistant for verifying problem-solving processes and an automated problem solver, utilizing various methods such as forward search, backward search and AI-assisted search. We've annotated the FormalGeo7k dataset, containing 6,981 (expand to 186,832 through data augmentation) geometry problems with complete formal language annotations. Implementation of the formal system and experiments on the FormalGeo7k validate the correctness and utility of the GFT. The backward depth-first search method only yields a 2.42% problem-solving failure rate, and we can incorporate deep learning techniques to achieve lower one. The source code of FGPS and FormalGeo7k dataset are available at https://github.com/BitSecret/FormalGeo.
Serving Deep Learning Model in Relational Databases
Oct 10, 2023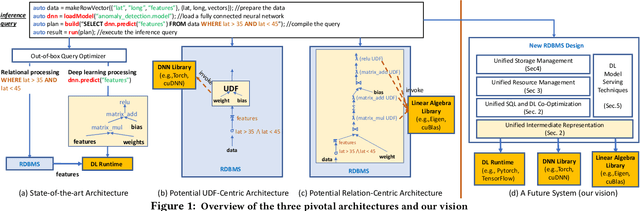


Serving deep learning (DL) models on relational data has become a critical requirement across diverse commercial and scientific domains, sparking growing interest recently. In this visionary paper, we embark on a comprehensive exploration of representative architectures to address the requirement. We highlight three pivotal paradigms: The state-of-the-artDL-Centricarchitecture offloadsDL computations to dedicated DL frameworks. The potential UDF-Centric architecture encapsulates one or more tensor computations into User Defined Functions (UDFs) within the database system. The potentialRelation-Centricarchitecture aims to represent a large-scale tensor computation through relational operators. While each of these architectures demonstrates promise in specific use scenarios, we identify urgent requirements for seamless integration of these architectures and the middle ground between these architectures. We delve into the gaps that impede the integration and explore innovative strategies to close them. We present a pathway to establish a novel database system for enabling a broad class of data-intensive DL inference applications.
A Comparison of Decision Forest Inference Platforms from A Database Perspective
Feb 09, 2023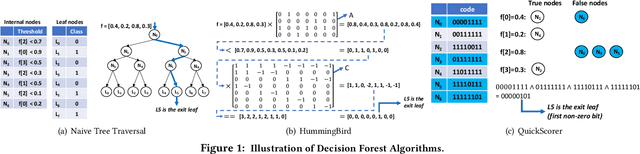

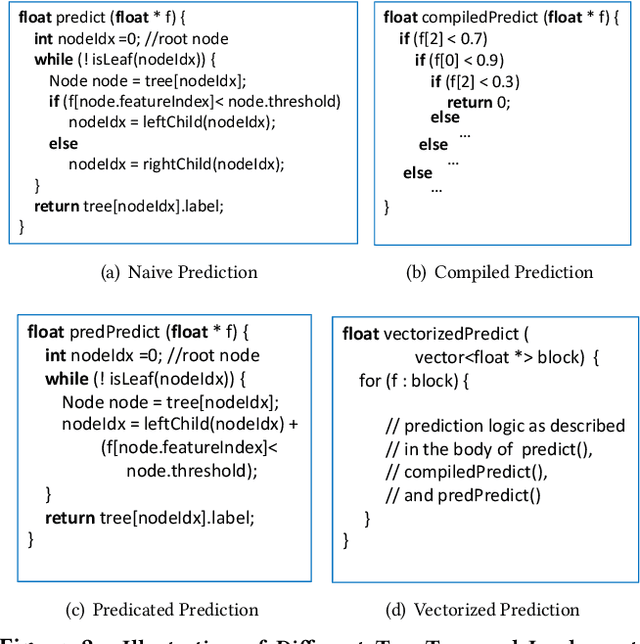

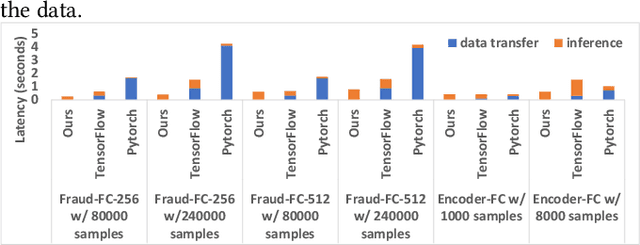
Decision forest, including RandomForest, XGBoost, and LightGBM, is one of the most popular machine learning techniques used in many industrial scenarios, such as credit card fraud detection, ranking, and business intelligence. Because the inference process is usually performance-critical, a number of frameworks were developed and dedicated for decision forest inference, such as ONNX, TreeLite from Amazon, TensorFlow Decision Forest from Google, HummingBird from Microsoft, Nvidia FIL, and lleaves. However, these frameworks are all decoupled with data management frameworks. It is unclear whether in-database inference will improve the overall performance. In addition, these frameworks used different algorithms, optimization techniques, and parallelism models. It is unclear how these implementations will affect the overall performance and how to make design decisions for an in-database inference framework. In this work, we investigated the above questions by comprehensively comparing the end-to-end performance of the aforementioned inference frameworks and netsDB, an in-database inference framework we implemented. Through this study, we identified that netsDB is best suited for handling small-scale models on large-scale datasets and all-scale models on small-scale datasets, for which it achieved up to hundreds of times of speedup. In addition, the relation-centric representation we proposed significantly improved netsDB's performance in handling large-scale models, while the model reuse optimization we proposed further improved netsDB's performance in handling small-scale datasets.
Benchmark of DNN Model Search at Deployment Time
Jun 01, 2022
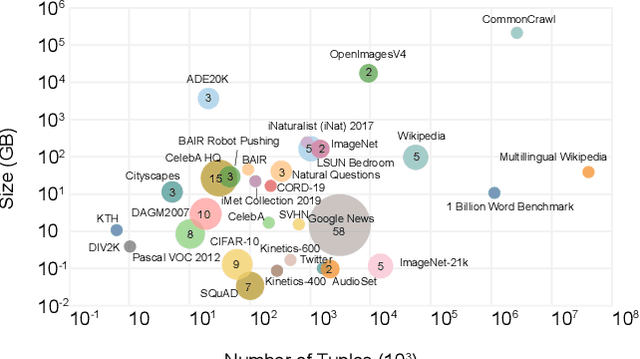
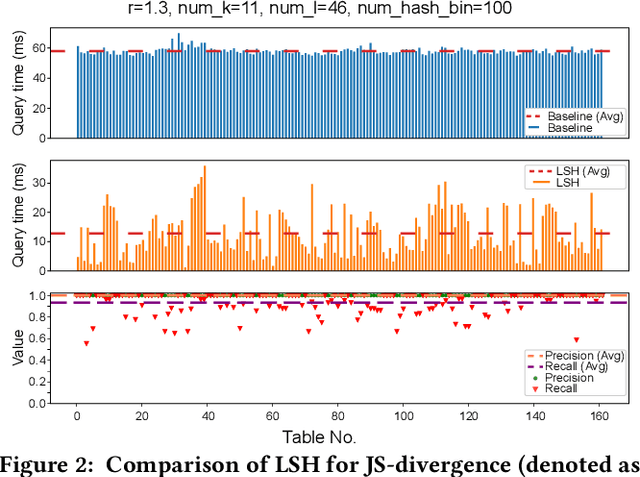
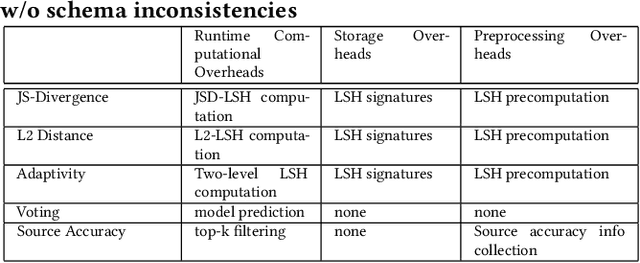
Deep learning has become the most popular direction in machine learning and artificial intelligence. However, the preparation of training data, as well as model training, are often time-consuming and become the bottleneck of the end-to-end machine learning lifecycle. Reusing models for inferring a dataset can avoid the costs of retraining. However, when there are multiple candidate models, it is challenging to discover the right model for reuse. Although there exist a number of model sharing platforms such as ModelDB, TensorFlow Hub, PyTorch Hub, and DLHub, most of these systems require model uploaders to manually specify the details of each model and model downloaders to screen keyword search results for selecting a model. We are lacking a highly productive model search tool that selects models for deployment without the need for any manual inspection and/or labeled data from the target domain. This paper proposes multiple model search strategies including various similarity-based approaches and non-similarity-based approaches. We design, implement, and evaluate these approaches on multiple model inference scenarios, including activity recognition, image recognition, text classification, natural language processing, and entity matching. The experimental evaluation showed that our proposed asymmetric similarity-based measurement, adaptivity, outperformed symmetric similarity-based measurements and non-similarity-based measurements in most of the workloads.
Survive the Schema Changes: Integration of Unmanaged Data Using Deep Learning
Oct 15, 2020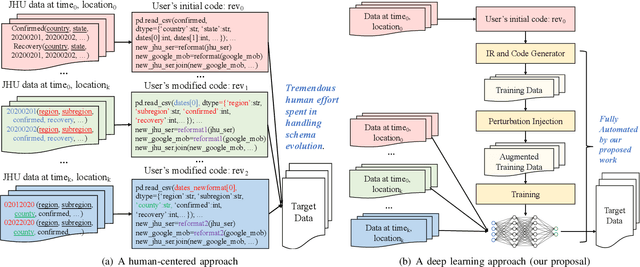
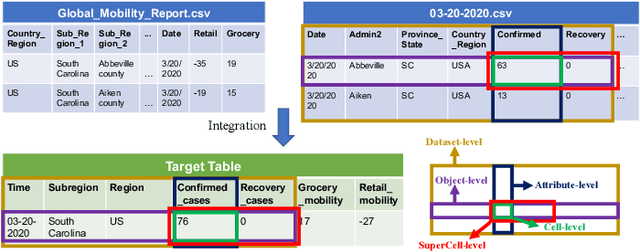
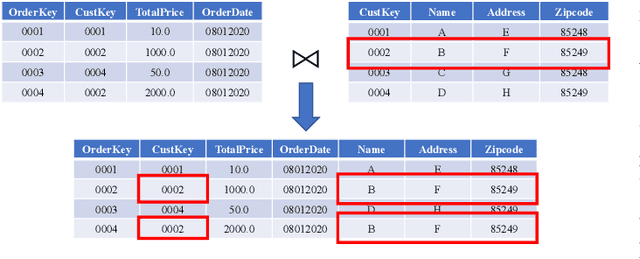
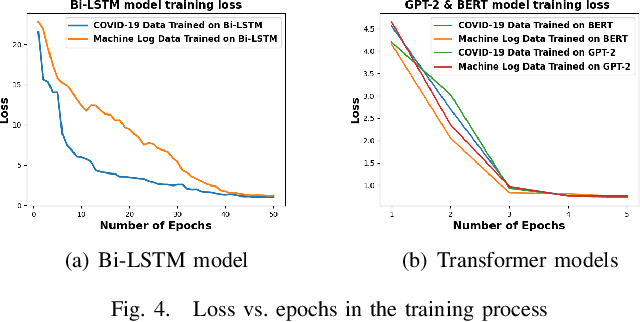
Data is the king in the age of AI. However data integration is often a laborious task that is hard to automate. Schema change is one significant obstacle to the automation of the end-to-end data integration process. Although there exist mechanisms such as query discovery and schema modification language to handle the problem, these approaches can only work with the assumption that the schema is maintained by a database. However, we observe diversified schema changes in heterogeneous data and open data, most of which has no schema defined. In this work, we propose to use deep learning to automatically deal with schema changes through a super cell representation and automatic injection of perturbations to the training data to make the model robust to schema changes. Our experimental results demonstrate that our proposed approach is effective for two real-world data integration scenarios: coronavirus data integration, and machine log integration.