 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDNet: A Novel Dataset for Identity Document Analysis and Fraud Detection
Aug 03, 2024
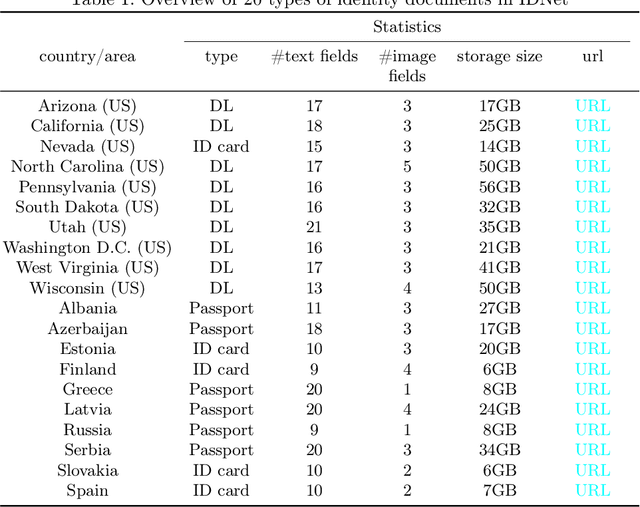


Effective fraud detection and analysis of government-issued identity documents, such as passports, driver's licenses, and identity cards, are essential in thwarting identity theft and bolstering security on online platforms. The training of accurate fraud detection and analysis tools depends on the availability of extensive identity document datasets. However, current publicly available benchmark datasets for identity document analysis, including MIDV-500, MIDV-2020, and FMIDV, fall short in several respects: they offer a limited number of samples, cover insufficient varieties of fraud patterns, and seldom include alterations in critical personal identifying fields like portrait images, limiting their utility in training models capable of detecting realistic frauds while preserving privacy. In response to these shortcomings, our research introduces a new benchmark dataset, IDNet, designed to advance privacy-preserving fraud detection efforts. The IDNet dataset comprises 837,060 images of synthetically generated identity documents, totaling approximately 490 gigabytes, categorized into 20 types from $10$ U.S. states and 10 European countries. We evaluate the utility and present use cases of the dataset, illustrating how it can aid in training privacy-preserving fraud detection methods, facilitating the generation of camera and video capturing of identity documents, and testing schema unification and other identity document management functionalities.