 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDNet: A Novel Dataset for Identity Document Analysis and Fraud Detection
Aug 03, 2024
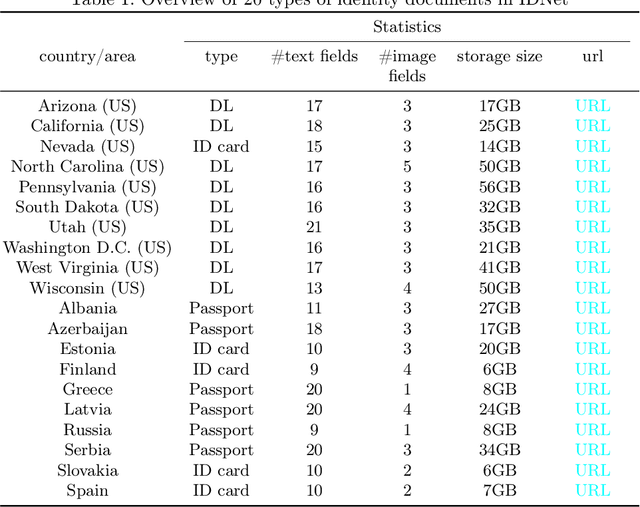


Effective fraud detection and analysis of government-issued identity documents, such as passports, driver's licenses, and identity cards, are essential in thwarting identity theft and bolstering security on online platforms. The training of accurate fraud detection and analysis tools depends on the availability of extensive identity document datasets. However, current publicly available benchmark datasets for identity document analysis, including MIDV-500, MIDV-2020, and FMIDV, fall short in several respects: they offer a limited number of samples, cover insufficient varieties of fraud patterns, and seldom include alterations in critical personal identifying fields like portrait images, limiting their utility in training models capable of detecting realistic frauds while preserving privacy. In response to these shortcomings, our research introduces a new benchmark dataset, IDNet, designed to advance privacy-preserving fraud detection efforts. The IDNet dataset comprises 837,060 images of synthetically generated identity documents, totaling approximately 490 gigabytes, categorized into 20 types from $10$ U.S. states and 10 European countries. We evaluate the utility and present use cases of the dataset, illustrating how it can aid in training privacy-preserving fraud detection methods, facilitating the generation of camera and video capturing of identity documents, and testing schema unification and other identity document management functionalities.
A Learning-based Declarative Privacy-Preserving Framework for Federated Data Management
Jan 22, 2024It is challenging to balance the privacy and accuracy for federated query processing over multiple private data silos. In this work, we will demonstrate an end-to-end workflow for automating an emerging privacy-preserving technique that uses a deep learning model trained using the Differentially-Private Stochastic Gradient Descent (DP-SGD) algorithm to replace portions of actual data to answer a query. Our proposed novel declarative privacy-preserving workflow allows users to specify "what private information to protect" rather than "how to protect". Under the hood, the system automatically chooses query-model transformation plans as well as hyper-parameters. At the same time, the proposed workflow also allows human experts to review and tune the selected privacy-preserving mechanism for audit/compliance, and optimization purposes.
A Comparison of Decision Forest Inference Platforms from A Database Perspective
Feb 09, 2023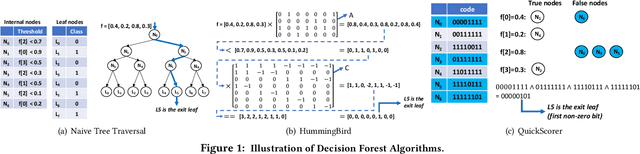

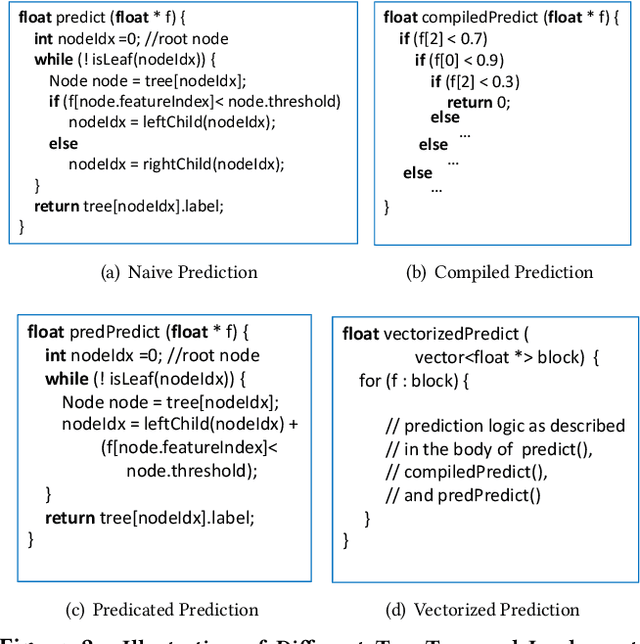

Decision forest, including RandomForest, XGBoost, and LightGBM, is one of the most popular machine learning techniques used in many industrial scenarios, such as credit card fraud detection, ranking, and business intelligence. Because the inference process is usually performance-critical, a number of frameworks were developed and dedicated for decision forest inference, such as ONNX, TreeLite from Amazon, TensorFlow Decision Forest from Google, HummingBird from Microsoft, Nvidia FIL, and lleaves. However, these frameworks are all decoupled with data management frameworks. It is unclear whether in-database inference will improve the overall performance. In addition, these frameworks used different algorithms, optimization techniques, and parallelism models. It is unclear how these implementations will affect the overall performance and how to make design decisions for an in-database inference framework. In this work, we investigated the above questions by comprehensively comparing the end-to-end performance of the aforementioned inference frameworks and netsDB, an in-database inference framework we implemented. Through this study, we identified that netsDB is best suited for handling small-scale models on large-scale datasets and all-scale models on small-scale datasets, for which it achieved up to hundreds of times of speedup. In addition, the relation-centric representation we proposed significantly improved netsDB's performance in handling large-scale models, while the model reuse optimization we proposed further improved netsDB's performance in handling small-scale datasets.
A Bayesian Approach for Medical Inquiry and Disease Inference in Automated Differential Diagnosis
Oct 23, 2021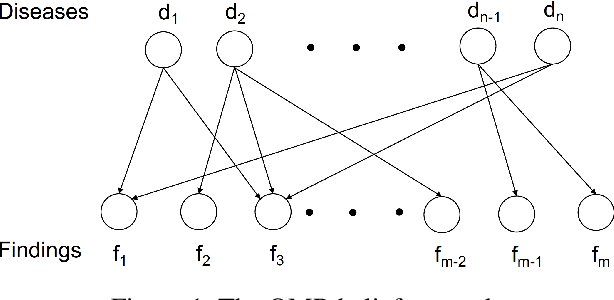

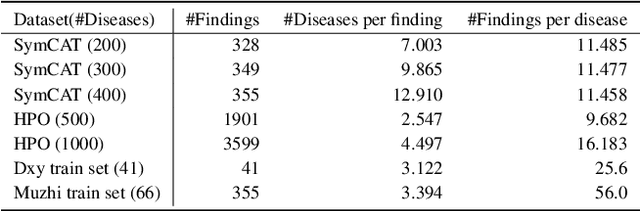

We propose a Bayesian approach for both medical inquiry and disease inference, the two major phases in differential diagnosis. Unlike previous work that simulates data from given probabilities and uses ML algorithms on them, we directly use the Quick Medical Reference (QMR) belief network, and apply Bayesian inference in the inference phase and Bayesian experimental design in the inquiry phase. Moreover, we improve the inquiry phase by extending the Bayesian experimental design framework from one-step search to multi-step search. Our approach has some practical advantages as it is interpretable, free of costly training, and able to adapt to new changes without any additional effort. Our experiments show that our approach achieves new state-of-the-art results on two simulated datasets, SymCAT and HPO, and competitive results on two diagnosis dialogue datasets, Muzhi and Dxy.
COVID-19: Comparative Analysis of Methods for Identifying Articles Related to Therapeutics and Vaccines without Using Labeled Data
Jan 05, 2021
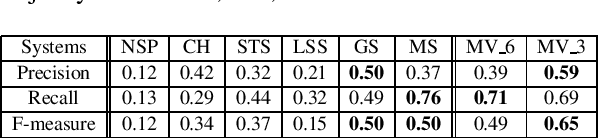
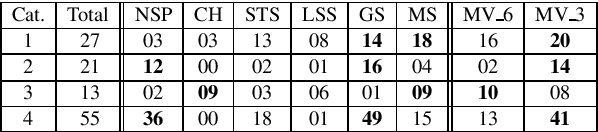
Here we proposed an approach to analyze text classification methods based on the presence or absence of task-specific terms (and their synonyms) in the text. We applied this approach to study six different transfer-learning and unsupervised methods for screening articles relevant to COVID-19 vaccines and therapeutics. The analysis revealed that while a BERT model trained on search-engine results generally performed well, it miss-classified relevant abstracts that did not contain task-specific terms. We used this insight to create a more effective unsupervised ensemble.
Robustly Pre-trained Neural Model for Direct Temporal Relation Extraction
Apr 13, 2020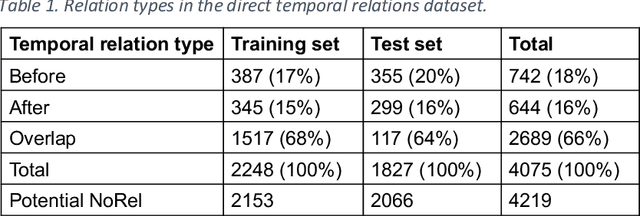

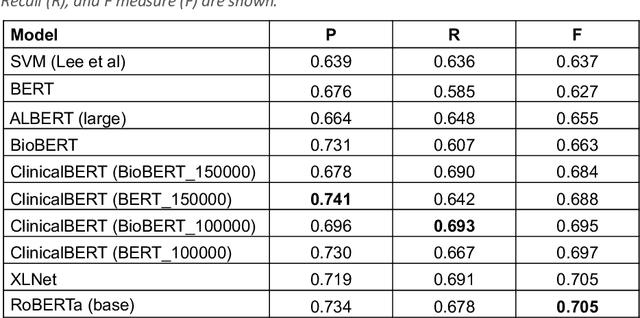
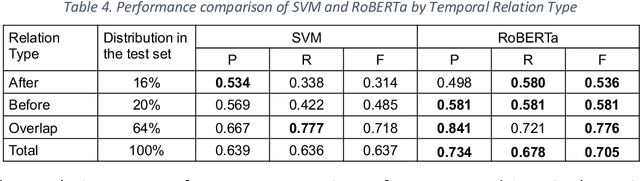
Background: Identifying relationships between clinical events and temporal expressions is a key challenge in meaningfully analyzing clinical text for use in advanced AI applications. While previous studies exist, the state-of-the-art performance has significant room for improvement. Methods: We studied several variants of BERT (Bidirectional Encoder Representations using Transformers) some involving clinical domain customization and the others involving improved architecture and/or training strategies. We evaluated these methods using a direct temporal relations dataset which is a semantically focused subset of the 2012 i2b2 temporal relations challenge dataset. Results: Our results show that RoBERTa, which employs better pre-training strategies including using 10x larger corpus, has improved overall F measure by 0.0864 absolute score (on the 1.00 scale) and thus reducing the error rate by 24% relative to the previous state-of-the-art performance achieved with an SVM (support vector machine) model. Conclusion: Modern contextual language modeling neural networks, pre-trained on a large corpus, achieve impressive performance even on highly-nuanced clinical temporal relation tasks.