 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Descent with Projection Finds Over-Parameterized Neural Networks for Learning Low-Degree Polynomials with Nearly Minimax Optimal Rate
Mar 22, 2026We study the problem of learning a low-degree spherical polynomial of degree $k_0 = Θ(1) \ge 1$ defined on the unit sphere in $\RR^d$ by training an over-parameterized two-layer neural network with augmented feature in this paper. Our main result is the significantly improved sample complexity for learning such low-degree polynomials. We show that, for any regression risk $\eps \in (0, Θ(d^{-k_0})]$, an over-parameterized two-layer neural network trained by a novel Gradient Descent with Projection (GDP) requires a sample complexity of $n \asymp Θ( \log(4/δ) \cdot d^{k_0}/\eps)$ with probability $1-δ$ for $δ\in (0,1)$, in contrast with the representative sample complexity $Θ(d^{k_0} \max\set{\eps^{-2},\log d})$. Moreover, such sample complexity is nearly unimprovable since the trained network renders a nearly optimal rate of the nonparametric regression risk of the order $\log({4}/δ) \cdot Θ(d^{k_0}/{n})$ with probability at least $1-δ$. On the other hand, the minimax optimal rate for the regression risk with a kernel of rank $Θ(d^{k_0})$ is $Θ(d^{k_0}/{n})$, so that the rate of the nonparametric regression risk of the network trained by GDP is nearly minimax optimal. In the case that the ground truth degree $k_0$ is unknown, we present a novel and provable adaptive degree selection algorithm which identifies the true degree and achieves the same nearly optimal regression rate. To the best of our knowledge, this is the first time that a nearly optimal risk bound is obtained by training an over-parameterized neural network with a popular activation function (ReLU) and algorithmic guarantee for learning low-degree spherical polynomials. Due to the feature learning capability of GDP, our results are beyond the regular Neural Tangent Kernel (NTK) limit.
VowelPrompt: Hearing Speech Emotions from Text via Vowel-level Prosodic Augmentation
Feb 06, 2026Emotion recognition in speech presents a complex multimodal challenge, requiring comprehension of both linguistic content and vocal expressivity, particularly prosodic features such as fundamental frequency, intensity, and temporal dynamics. Although large language models (LLMs) have shown promise in reasoning over textual transcriptions for emotion recognition, they typically neglect fine-grained prosodic information, limiting their effectiveness and interpretability. In this work, we propose VowelPrompt, a linguistically grounded framework that augments LLM-based emotion recognition with interpretable, fine-grained vowel-level prosodic cues. Drawing on phonetic evidence that vowels serve as primary carriers of affective prosody, VowelPrompt extracts pitch-, energy-, and duration-based descriptors from time-aligned vowel segments, and converts these features into natural language descriptions for better interpretability. Such a design enables LLMs to jointly reason over lexical semantics and fine-grained prosodic variation. Moreover, we adopt a two-stage adaptation procedure comprising supervised fine-tuning (SFT) followed by Reinforcement Learning with Verifiable Reward (RLVR), implemented via Group Relative Policy Optimization (GRPO), to enhance reasoning capability, enforce structured output adherence, and improve generalization across domains and speaker variations. Extensive evaluations across diverse benchmark datasets demonstrate that VowelPrompt consistently outperforms state-of-the-art emotion recognition methods under zero-shot, fine-tuned, cross-domain, and cross-linguistic conditions, while enabling the generation of interpretable explanations that are jointly grounded in contextual semantics and fine-grained prosodic structure.
Shallow Neural Networks Learn Low-Degree Spherical Polynomials with Learnable Channel Attention
Dec 23, 2025
We study the problem of learning a low-degree spherical polynomial of degree $\ell_0 = Θ(1) \ge 1$ defined on the unit sphere in $\RR^d$ by training an over-parameterized two-layer neural network (NN) with channel attention in this paper. Our main result is the significantly improved sample complexity for learning such low-degree polynomials. We show that, for any regression risk $\eps \in (0,1)$, a carefully designed two-layer NN with channel attention and finite width of $m \ge Θ({n^4 \log (2n/δ)}/{d^{2\ell_0}})$ trained by the vanilla gradient descent (GD) requires the lowest sample complexity of $n \asymp Θ(d^{\ell_0}/\eps)$ with probability $1-δ$ for every $δ\in (0,1)$, in contrast with the representative sample complexity $Θ\pth{d^{\ell_0} \max\set{\eps^{-2},\log d}}$, where $n$ is the training daata size. Moreover, such sample complexity is not improvable since the trained network renders a sharp rate of the nonparametric regression risk of the order $Θ(d^{\ell_0}/{n})$ with probability at least $1-δ$. On the other hand, the minimax optimal rate for the regression risk with a kernel of rank $Θ(d^{\ell_0})$ is $Θ(d^{\ell_0}/{n})$, so that the rate of the nonparametric regression risk of the network trained by GD is minimax optimal. The training of the two-layer NN with channel attention consists of two stages. In Stage 1, a provable learnable channel selection algorithm identifies the ground-truth channel number $\ell_0$ from the initial $L \ge \ell_0$ channels in the first-layer activation, with high probability. This learnable selection is achieved by an efficient one-step GD update on both layers, enabling feature learning for low-degree polynomial targets. In Stage 2, the second layer is trained by standard GD using the activation function with the selected channels.
Differentiable Channel Selection in Self-Attention For Person Re-Identification
May 13, 2025



In this paper, we propose a novel attention module termed the Differentiable Channel Selection Attention module, or the DCS-Attention module. In contrast with conventional self-attention, the DCS-Attention module features selection of informative channels in the computation of the attention weights. The selection of the feature channels is performed in a differentiable manner, enabling seamless integration with DNN training. Our DCS-Attention is compatible with either fixed neural network backbones or learnable backbones with Differentiable Neural Architecture Search (DNAS), leading to DCS with Fixed Backbone (DCS-FB) and DCS-DNAS, respectively. Importantly, our DCS-Attention is motivated by the principle of Information Bottleneck (IB), and a novel variational upper bound for the IB loss, which can be optimized by SGD, is derived and incorporated into the training loss of the networks with the DCS-Attention modules. In this manner, a neural network with DCS-Attention modules is capable of selecting the most informative channels for feature extraction so that it enjoys state-of-the-art performance for the Re-ID task. Extensive experiments on multiple person Re-ID benchmarks using both DCS-FB and DCS-DNAS show that DCS-Attention significantly enhances the prediction accuracy of DNNs for person Re-ID, which demonstrates the effectiveness of DCS-Attention in learning discriminative features critical to identifying person identities. The code of our work is available at https://github.com/Statistical-Deep-Learning/DCS-Attention.
Diffusion on Graph: Augmentation of Graph Structure for Node Classification
Mar 16, 2025



Graph diffusion models have recently been proposed to synthesize entire graphs, such as molecule graphs. Although existing methods have shown great performance in generating entire graphs for graph-level learning tasks, no graph diffusion models have been developed to generate synthetic graph structures, that is, synthetic nodes and associated edges within a given graph, for node-level learning tasks. Inspired by the research in the computer vision literature using synthetic data for enhanced performance, we propose Diffusion on Graph (DoG), which generates synthetic graph structures to boost the performance of GNNs. The synthetic graph structures generated by DoG are combined with the original graph to form an augmented graph for the training of node-level learning tasks, such as node classification and graph contrastive learning (GCL). To improve the efficiency of the generation process, a Bi-Level Neighbor Map Decoder (BLND) is introduced in DoG. To mitigate the adverse effect of the noise introduced by the synthetic graph structures, a low-rank regularization method is proposed for the training of graph neural networks (GNNs) on the augmented graphs. Extensive experiments on various graph datasets for semi-supervised node classification and graph contrastive learning have been conducted to demonstrate the effectiveness of DoG with low-rank regularization. The code of DoG is available at https://github.com/Statistical-Deep-Learning/DoG.
Gradient Descent Finds Over-Parameterized Neural Networks with Sharp Generalization for Nonparametric Regression: A Distribution-Free Analysis
Nov 05, 2024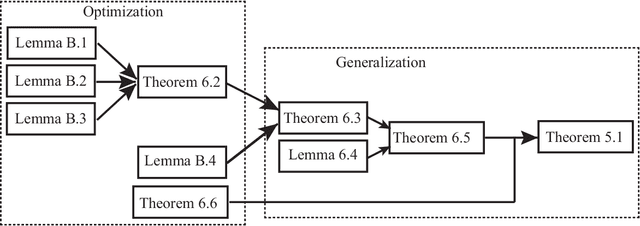

We study nonparametric regression by an over-parameterized two-layer neural network trained by gradient descent (GD) in this paper. We show that, if the neural network is trained by GD with early stopping, then the trained network renders a sharp rate of the nonparametric regression risk of $\cO(\eps_n^2)$, which is the same rate as that for the classical kernel regression trained by GD with early stopping, where $\eps_n$ is the critical population rate of the Neural Tangent Kernel (NTK) associated with the network and $n$ is the size of the training data. It is remarked that our result does not require distributional assumptions on the training data, in a strong contrast with many existing results which rely on specific distributions such as the spherical uniform data distribution or distributions satisfying certain restrictive conditions. The rate $\cO(\eps_n^2)$ is known to be minimax optimal for specific cases, such as the case that the NTK has a polynomial eigenvalue decay rate which happens under certain distributional assumptions. Our result formally fills the gap between training a classical kernel regression model and training an over-parameterized but finite-width neural network by GD for nonparametric regression without distributional assumptions. We also provide confirmative answers to certain open questions or address particular concerns in the literature of training over-parameterized neural networks by GD with early stopping for nonparametric regression, including the characterization of the stopping time, the lower bound for the network width, and the constant learning rate used in GD.
Locally Regularized Sparse Graph by Fast Proximal Gradient Descent
Sep 25, 2024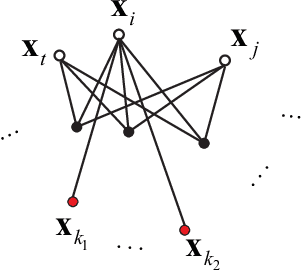
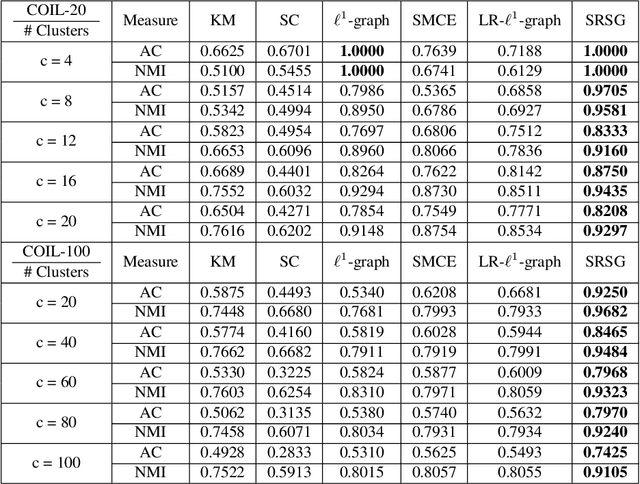
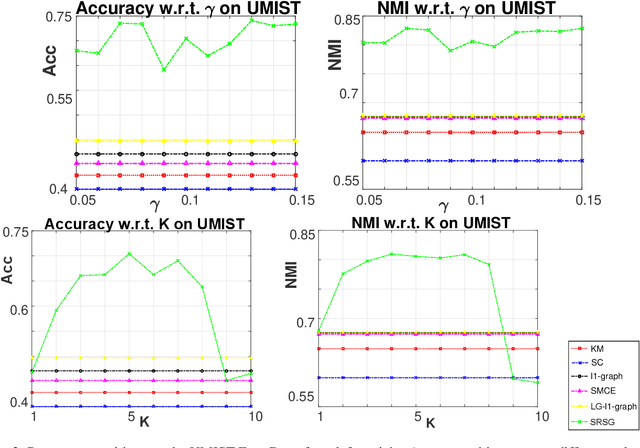
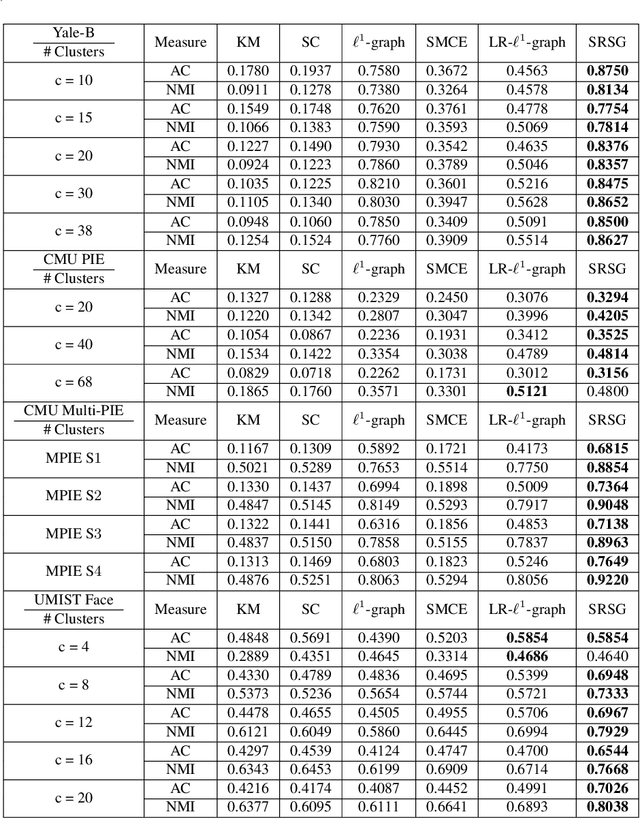
Sparse graphs built by sparse representation has been demonstrated to be effective in clustering high-dimensional data. Albeit the compelling empirical performance, the vanilla sparse graph ignores the geometric information of the data by performing sparse representation for each datum separately. In order to obtain a sparse graph aligned with the local geometric structure of data, we propose a novel Support Regularized Sparse Graph, abbreviated as SRSG, for data clustering. SRSG encourages local smoothness on the neighborhoods of nearby data points by a well-defined support regularization term. We propose a fast proximal gradient descent method to solve the non-convex optimization problem of SRSG with the convergence matching the Nesterov's optimal convergence rate of first-order methods on smooth and convex objective function with Lipschitz continuous gradient. Extensive experimental results on various real data sets demonstrate the superiority of SRSG over other competing clustering methods.
Deep Geometric Moments Promote Shape Consistency in Text-to-3D Generation
Aug 12, 2024



To address the data scarcity associated with 3D assets, 2D-lifting techniques such as Score Distillation Sampling (SDS) have become a widely adopted practice in text-to-3D generation pipelines. However, the diffusion models used in these techniques are prone to viewpoint bias and thus lead to geometric inconsistencies such as the Janus problem. To counter this, we introduce MT3D, a text-to-3D generative model that leverages a high-fidelity 3D object to overcome viewpoint bias and explicitly infuse geometric understanding into the generation pipeline. Firstly, we employ depth maps derived from a high-quality 3D model as control signals to guarantee that the generated 2D images preserve the fundamental shape and structure, thereby reducing the inherent viewpoint bias. Next, we utilize deep geometric moments to ensure geometric consistency in the 3D representation explicitly. By incorporating geometric details from a 3D asset, MT3D enables the creation of diverse and geometrically consistent objects, thereby improving the quality and usability of our 3D representations.
IDNet: A Novel Dataset for Identity Document Analysis and Fraud Detection
Aug 03, 2024
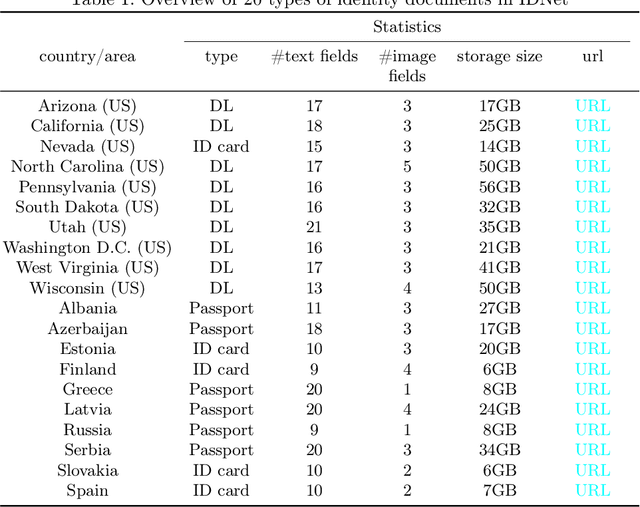


Effective fraud detection and analysis of government-issued identity documents, such as passports, driver's licenses, and identity cards, are essential in thwarting identity theft and bolstering security on online platforms. The training of accurate fraud detection and analysis tools depends on the availability of extensive identity document datasets. However, current publicly available benchmark datasets for identity document analysis, including MIDV-500, MIDV-2020, and FMIDV, fall short in several respects: they offer a limited number of samples, cover insufficient varieties of fraud patterns, and seldom include alterations in critical personal identifying fields like portrait images, limiting their utility in training models capable of detecting realistic frauds while preserving privacy. In response to these shortcomings, our research introduces a new benchmark dataset, IDNet, designed to advance privacy-preserving fraud detection efforts. The IDNet dataset comprises 837,060 images of synthetically generated identity documents, totaling approximately 490 gigabytes, categorized into 20 types from $10$ U.S. states and 10 European countries. We evaluate the utility and present use cases of the dataset, illustrating how it can aid in training privacy-preserving fraud detection methods, facilitating the generation of camera and video capturing of identity documents, and testing schema unification and other identity document management functionalities.
Efficient Visual Transformer by Learnable Token Merging
Jul 21, 2024



Self-attention and transformers have been widely used in deep learning. Recent efforts have been devoted to incorporating transformer blocks into different neural architectures, including those with convolutions, leading to various visual transformers for computer vision tasks. In this paper, we propose a novel and compact transformer block, Transformer with Learnable Token Merging (LTM), or LTM-Transformer. LTM-Transformer performs token merging in a learnable scheme. LTM-Transformer is compatible with many popular and compact transformer networks, and it reduces the FLOPs and the inference time of the visual transformers while maintaining or even improving the prediction accuracy. In the experiments, we replace all the transformer blocks in popular visual transformers, including MobileViT, EfficientViT, ViT-S/16, and Swin-T, with LTM-Transformer blocks, leading to LTM-Transformer networks with different backbones. The LTM-Transformer is motivated by reduction of Information Bottleneck, and a novel and separable variational upper bound for the IB loss is derived. The architecture of mask module in our LTM blocks which generate the token merging mask is designed to reduce the derived upper bound for the IB loss. Extensive results on computer vision tasks evidence that LTM-Transformer renders compact and efficient visual transformers with comparable or much better prediction accuracy than the original visual transformers. The code of the LTM-Transformer is available at \url{https://github.com/Statistical-Deep-Learning/LTM}.