 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Diffusion with Deep Geometric Moments: Balancing Fidelity and Variation
May 18, 2025Text-to-image generation models have achieved remarkable capabilities in synthesizing images, but often struggle to provide fine-grained control over the output. Existing guidance approaches, such as segmentation maps and depth maps, introduce spatial rigidity that restricts the inherent diversity of diffusion models. In this work, we introduce Deep Geometric Moments (DGM) as a novel form of guidance that encapsulates the subject's visual features and nuances through a learned geometric prior. DGMs focus specifically on the subject itself compared to DINO or CLIP features, which suffer from overemphasis on global image features or semantics. Unlike ResNets, which are sensitive to pixel-wise perturbations, DGMs rely on robust geometric moments. Our experiments demonstrate that DGM effectively balance control and diversity in diffusion-based image generation, allowing a flexible control mechanism for steering the diffusion process.
DecompDreamer: Advancing Structured 3D Asset Generation with Multi-Object Decomposition and Gaussian Splatting
Mar 15, 2025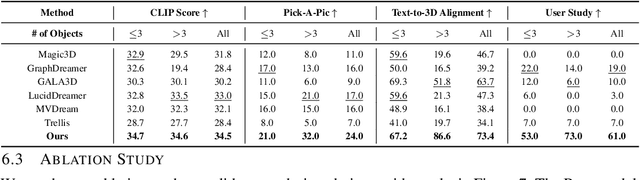
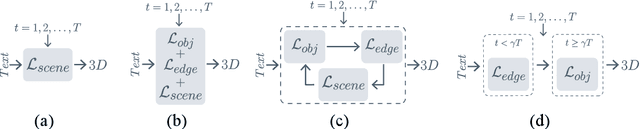

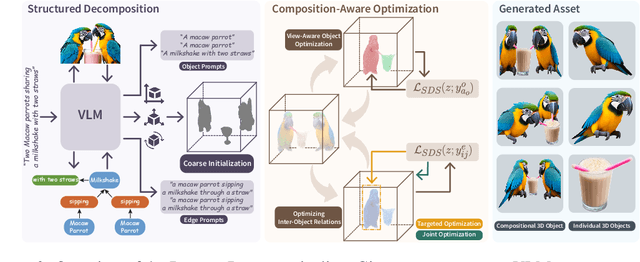
Text-to-3D generation saw dramatic advances in recent years by leveraging Text-to-Image models. However, most existing techniques struggle with compositional prompts, which describe multiple objects and their spatial relationships. They often fail to capture fine-grained inter-object interactions. We introduce DecompDreamer, a Gaussian splatting-based training routine designed to generate high-quality 3D compositions from such complex prompts. DecompDreamer leverages Vision-Language Models (VLMs) to decompose scenes into structured components and their relationships. We propose a progressive optimization strategy that first prioritizes joint relationship modeling before gradually shifting toward targeted object refinement. Our qualitative and quantitative evaluations against state-of-the-art text-to-3D models demonstrate that DecompDreamer effectively generates intricate 3D compositions with superior object disentanglement, offering enhanced control and flexibility in 3D generation. Project page : https://decompdreamer3d.github.io
Deep Geometric Moments Promote Shape Consistency in Text-to-3D Generation
Aug 12, 2024



To address the data scarcity associated with 3D assets, 2D-lifting techniques such as Score Distillation Sampling (SDS) have become a widely adopted practice in text-to-3D generation pipelines. However, the diffusion models used in these techniques are prone to viewpoint bias and thus lead to geometric inconsistencies such as the Janus problem. To counter this, we introduce MT3D, a text-to-3D generative model that leverages a high-fidelity 3D object to overcome viewpoint bias and explicitly infuse geometric understanding into the generation pipeline. Firstly, we employ depth maps derived from a high-quality 3D model as control signals to guarantee that the generated 2D images preserve the fundamental shape and structure, thereby reducing the inherent viewpoint bias. Next, we utilize deep geometric moments to ensure geometric consistency in the 3D representation explicitly. By incorporating geometric details from a 3D asset, MT3D enables the creation of diverse and geometrically consistent objects, thereby improving the quality and usability of our 3D representations.
Learning Decomposable and Debiased Representations via Attribute-Centric Information Bottlenecks
Mar 21, 2024


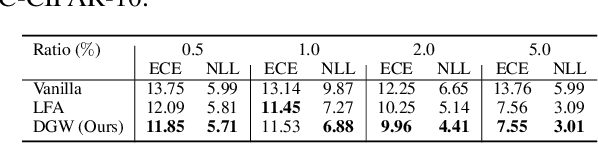
Biased attributes, spuriously correlated with target labels in a dataset, can problematically lead to neural networks that learn improper shortcuts for classifications and limit their capabilities for out-of-distribution (OOD) generalization. Although many debiasing approaches have been proposed to ensure correct predictions from biased datasets, few studies have considered learning latent embedding consisting of intrinsic and biased attributes that contribute to improved performance and explain how the model pays attention to attributes. In this paper, we propose a novel debiasing framework, Debiasing Global Workspace, introducing attention-based information bottlenecks for learning compositional representations of attributes without defining specific bias types. Based on our observation that learning shape-centric representation helps robust performance on OOD datasets, we adopt those abilities to learn robust and generalizable representations of decomposable latent embeddings corresponding to intrinsic and biasing attributes. We conduct comprehensive evaluations on biased datasets, along with both quantitative and qualitative analyses, to showcase our approach's efficacy in attribute-centric representation learning and its ability to differentiate between intrinsic and bias-related features.
RNAS-CL: Robust Neural Architecture Search by Cross-Layer Knowledge Distillation
Jan 19, 2023Deep Neural Networks are vulnerable to adversarial attacks. Neural Architecture Search (NAS), one of the driving tools of deep neural networks, demonstrates superior performance in prediction accuracy in various machine learning applications. However, it is unclear how it performs against adversarial attacks. Given the presence of a robust teacher, it would be interesting to investigate if NAS would produce robust neural architecture by inheriting robustness from the teacher. In this paper, we propose Robust Neural Architecture Search by Cross-Layer Knowledge Distillation (RNAS-CL), a novel NAS algorithm that improves the robustness of NAS by learning from a robust teacher through cross-layer knowledge distillation. Unlike previous knowledge distillation methods that encourage close student/teacher output only in the last layer, RNAS-CL automatically searches for the best teacher layer to supervise each student layer. Experimental result evidences the effectiveness of RNAS-CL and shows that RNAS-CL produces small and robust neural architecture.
Similarity-based Distance for Categorical Clustering using Space Structure
Nov 19, 2020
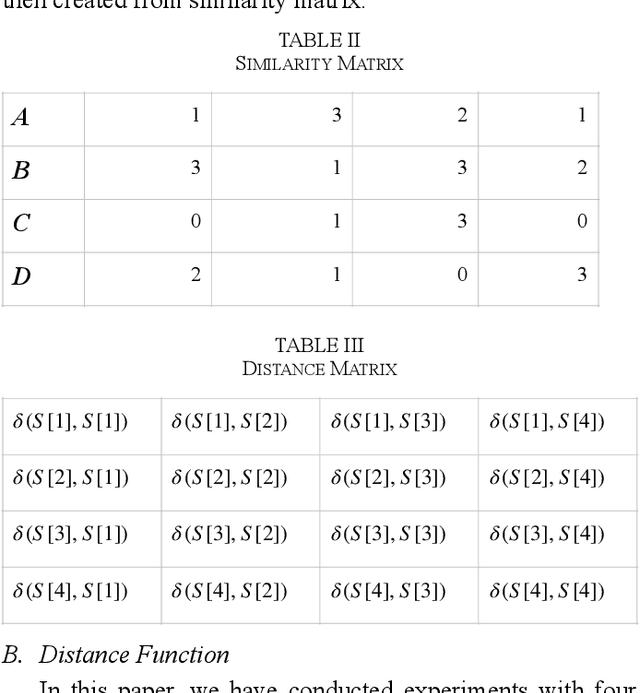
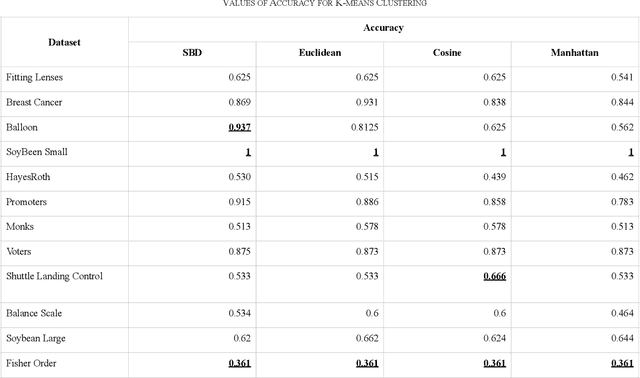
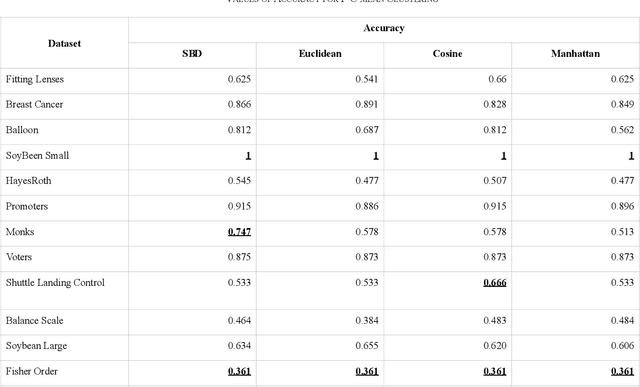
Clustering is spotting pattern in a group of objects and resultantly grouping the similar objects together. Objects have attributes which are not always numerical, sometimes attributes have domain or categories to which they could belong to. Such data is called categorical data. To group categorical data many clustering algorithms are used, among which k- modes algorithm has so far given the most significant results. Nevertheless, there is still a lot which could be improved. Algorithms like k-means, fuzzy-c-means or hierarchical have given far better accuracies with numerical data. In this paper, we have proposed a novel distance metric, similarity-based distance (SBD) to find the distance between objects of categorical data. Experiments have shown that our proposed distance (SBD), when used with the SBC (space structure based clustering) type algorithm significantly outperforms the existing algorithms like k-modes or other SBC type algorithms when used on categorical datasets.
Better Together: Resnet-50 accuracy with $13x$ fewer parameters and at $3x$ speed
Jun 10, 2020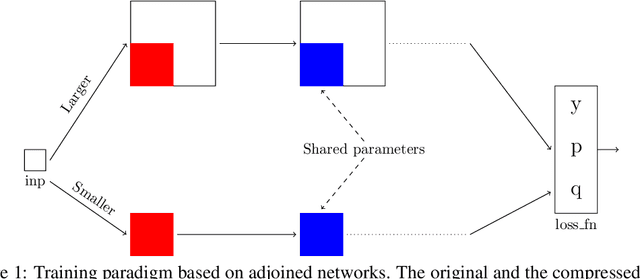
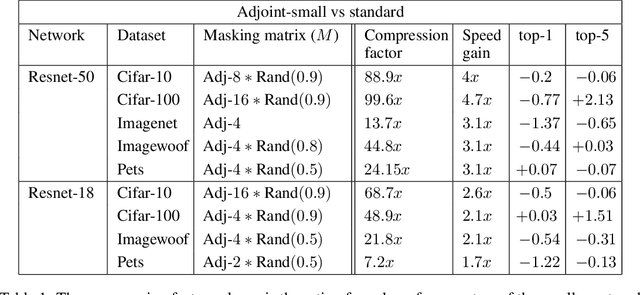
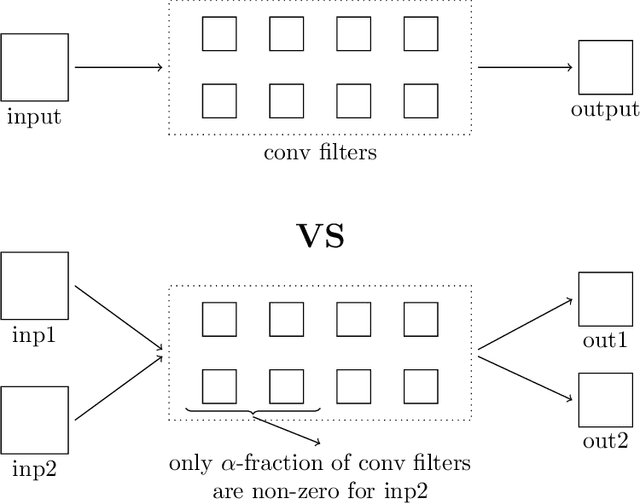
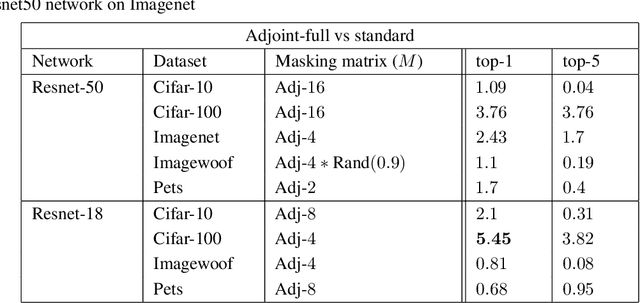
Recent research on compressing deep neural networks has focused on reducing the number of parameters. Smaller networks are easier to export and deploy on edge-devices. We introduce Adjoined networks as a training approach that can compress and regularize any CNN-based neural architecture. Our one-shot learning paradigm trains both the original and the smaller networks together. The parameters of the smaller network are shared across both the architectures. For resnet-50 trained on Imagenet, we are able to achieve a $13.7x$ reduction in the number of parameters and a $3x$ improvement in inference time without any significant drop in accuracy. For the same architecture on CIFAR-100, we are able to achieve a $99.7x$ reduction in the number of parameters and a $5x$ improvement in inference time. On both these datasets, the original network trained in the adjoint fashion gains about $3\%$ in top-1 accuracy as compared to the same network trained in the standard fashion.