 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hybrid Architecture for Benign-Malignant Classification of Mammography ROIs
Apr 14, 2026Accurate characterization of suspicious breast lesions in mammography is important for early diagnosis and treatment planning. While Convolutional Neural Networks (CNNs) are effective at extracting local visual patterns, they are less suited to modeling long-range dependencies. Vision Transformers (ViTs) address this limitation through self-attention, but their quadratic computational cost can be prohibitive. This paper presents a hybrid architecture that combines EfficientNetV2-M for local feature extraction with Vision Mamba, a State Space Model (SSM), for efficient global context modeling. The proposed model performs binary classification of abnormality-centered mammography regions of interest (ROIs) from the CBIS-DDSM dataset into benign and malignant classes. By combining a strong CNN backbone with a linear-complexity sequence model, the approach achieves strong lesion-level classification performance in an ROI-based setting.
Empirical Analysis of Nature-Inspired Algorithms for Autism Spectrum Disorder Detection Using 3D Video Dataset
Jan 02, 2025
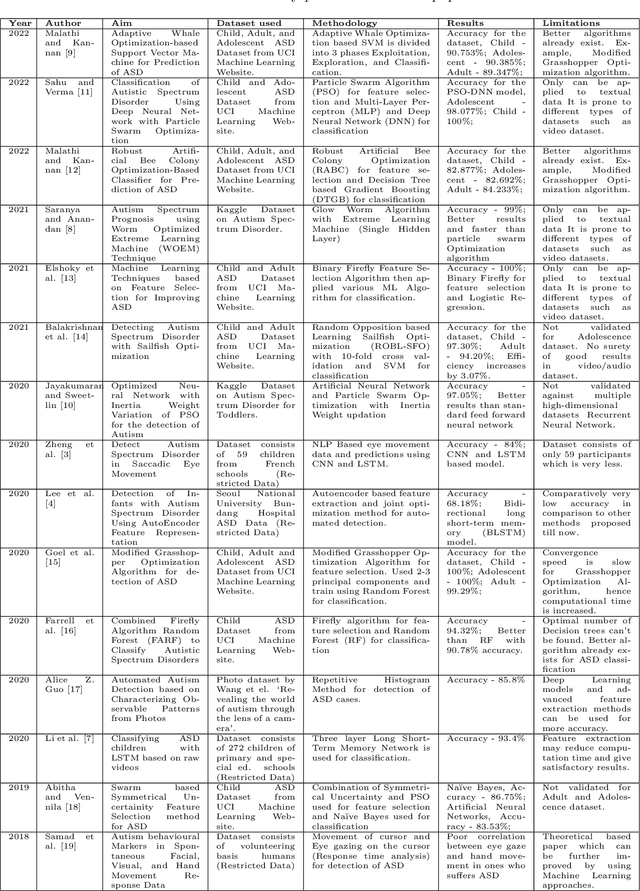
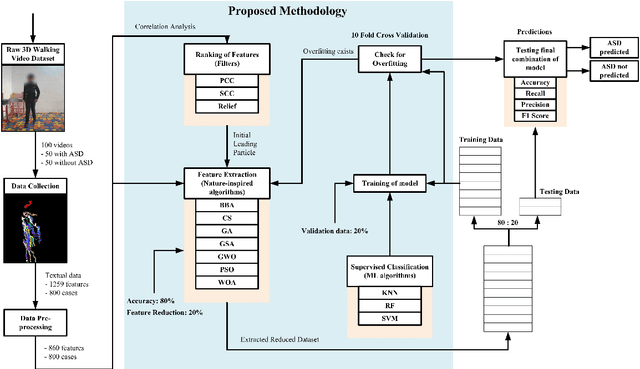

Autism Spectrum Disorder (ASD) is a chronic neurodevelopmental disorder symptoms of which includes repetitive behaviour and lack of social and communication skills. Even though these symptoms can be seen very clearly in social but a large number of individuals with ASD remain undiagnosed. In this paper, we worked on a methodology for the detection of ASD from a 3-dimensional walking video dataset, utilizing supervised machine learning (ML) classification algorithms and nature-inspired optimization algorithms for feature extraction from the dataset. The proposed methodology involves the classification of ASD using a supervised ML classification algorithm and extracting important and relevant features from the dataset using nature-inspired optimization algorithms. We also included the ranking coefficients to find the initial leading particle. This selection of particle significantly reduces the computation time and hence, improves the total efficiency and accuracy for ASD detection. To evaluate the efficiency of the proposed methodology, we deployed various combinationsalgorithms of classification algorithm and nature-inspired algorithms resulting in an outstanding classification accuracy of $100\%$ using the random forest classification algorithm and gravitational search algorithm for feature selection. The application of the proposed methodology with different datasets would enhance the robustness and generalizability of the proposed methodology. Due to high accuracy and less total computation time, the proposed methodology will offer a significant contribution to the medical and academic fields, providing a foundation for future research and advancements in ASD diagnosis.
Similarity-based Distance for Categorical Clustering using Space Structure
Nov 19, 2020
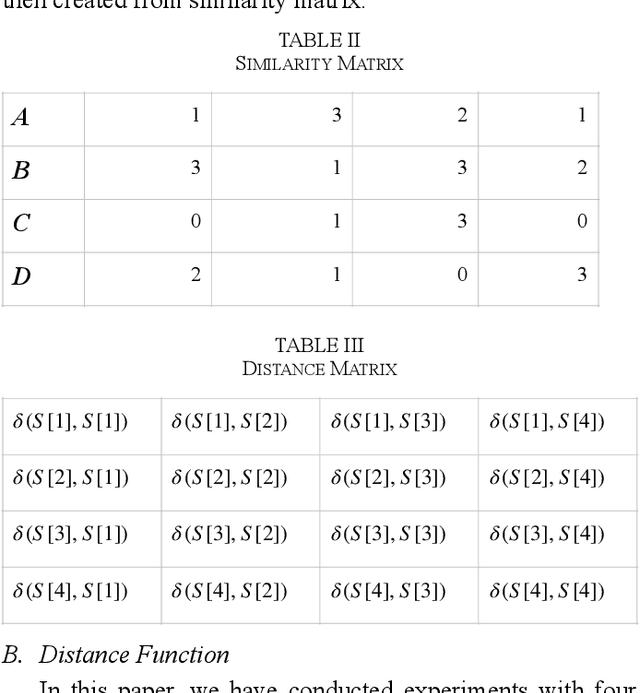
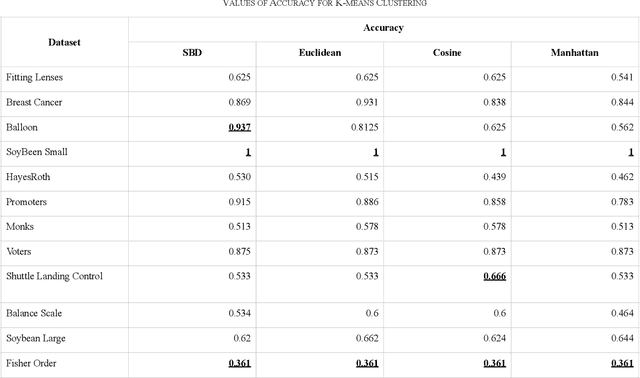
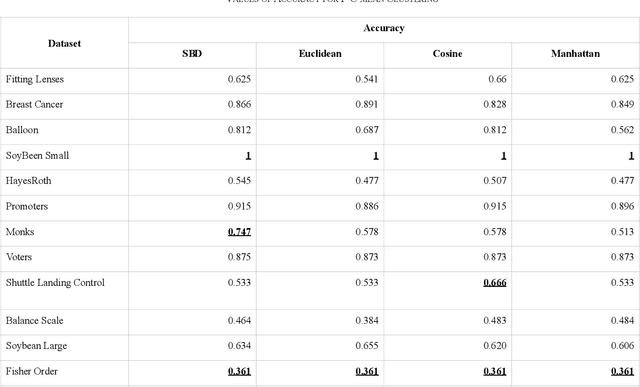
Clustering is spotting pattern in a group of objects and resultantly grouping the similar objects together. Objects have attributes which are not always numerical, sometimes attributes have domain or categories to which they could belong to. Such data is called categorical data. To group categorical data many clustering algorithms are used, among which k- modes algorithm has so far given the most significant results. Nevertheless, there is still a lot which could be improved. Algorithms like k-means, fuzzy-c-means or hierarchical have given far better accuracies with numerical data. In this paper, we have proposed a novel distance metric, similarity-based distance (SBD) to find the distance between objects of categorical data. Experiments have shown that our proposed distance (SBD), when used with the SBC (space structure based clustering) type algorithm significantly outperforms the existing algorithms like k-modes or other SBC type algorithms when used on categorical datasets.