 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecompDreamer: Advancing Structured 3D Asset Generation with Multi-Object Decomposition and Gaussian Splatting
Paper and Code
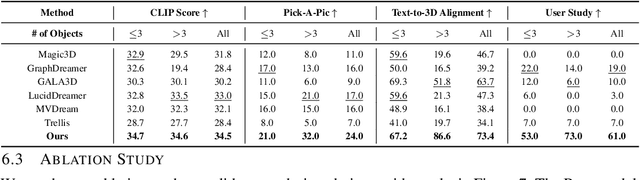
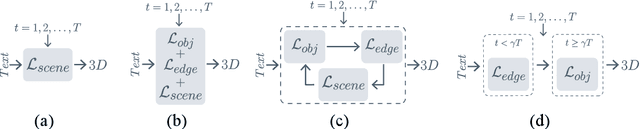

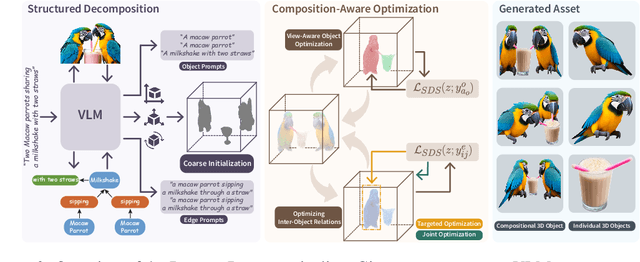
Text-to-3D generation saw dramatic advances in recent years by leveraging Text-to-Image models. However, most existing techniques struggle with compositional prompts, which describe multiple objects and their spatial relationships. They often fail to capture fine-grained inter-object interactions. We introduce DecompDreamer, a Gaussian splatting-based training routine designed to generate high-quality 3D compositions from such complex prompts. DecompDreamer leverages Vision-Language Models (VLMs) to decompose scenes into structured components and their relationships. We propose a progressive optimization strategy that first prioritizes joint relationship modeling before gradually shifting toward targeted object refinement. Our qualitative and quantitative evaluations against state-of-the-art text-to-3D models demonstrate that DecompDreamer effectively generates intricate 3D compositions with superior object disentanglement, offering enhanced control and flexibility in 3D generation. Project page : https://decompdreamer3d.github.io