 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGround Reaction Force Estimation via Time-aware Knowledge Distillation
Jun 12, 2025Human gait analysis with wearable sensors has been widely used in various applications, such as daily life healthcare, rehabilitation, physical therapy, and clinical diagnostics and monitoring. In particular, ground reaction force (GRF) provides critical information about how the body interacts with the ground during locomotion. Although instrumented treadmills have been widely used as the gold standard for measuring GRF during walking, their lack of portability and high cost make them impractical for many applications. As an alternative, low-cost, portable, wearable insole sensors have been utilized to measure GRF; however, these sensors are susceptible to noise and disturbance and are less accurate than treadmill measurements. To address these challenges, we propose a Time-aware Knowledge Distillation framework for GRF estimation from insole sensor data. This framework leverages similarity and temporal features within a mini-batch during the knowledge distillation process, effectively capturing the complementary relationships between features and the sequential properties of the target and input data. The performance of the lightweight models distilled through this framework was evaluated by comparing GRF estimations from insole sensor data against measurements from an instrumented treadmill. Empirical results demonstrated that Time-aware Knowledge Distillation outperforms current baselines in GRF estimation from wearable sensor data.
Intra-class Patch Swap for Self-Distillation
May 20, 2025Knowledge distillation (KD) is a valuable technique for compressing large deep learning models into smaller, edge-suitable networks. However, conventional KD frameworks rely on pre-trained high-capacity teacher networks, which introduce significant challenges such as increased memory/storage requirements, additional training costs, and ambiguity in selecting an appropriate teacher for a given student model. Although a teacher-free distillation (self-distillation) has emerged as a promising alternative, many existing approaches still rely on architectural modifications or complex training procedures, which limit their generality and efficiency. To address these limitations, we propose a novel framework based on teacher-free distillation that operates using a single student network without any auxiliary components, architectural modifications, or additional learnable parameters. Our approach is built on a simple yet highly effective augmentation, called intra-class patch swap augmentation. This augmentation simulates a teacher-student dynamic within a single model by generating pairs of intra-class samples with varying confidence levels, and then applying instance-to-instance distillation to align their predictive distributions. Our method is conceptually simple, model-agnostic, and easy to implement, requiring only a single augmentation function. Extensive experiments across image classification, semantic segmentation, and object detection show that our method consistently outperforms both existing self-distillation baselines and conventional teacher-based KD approaches. These results suggest that the success of self-distillation could hinge on the design of the augmentation itself. Our codes are available at https://github.com/hchoi71/Intra-class-Patch-Swap.
Guiding Diffusion with Deep Geometric Moments: Balancing Fidelity and Variation
May 18, 2025Text-to-image generation models have achieved remarkable capabilities in synthesizing images, but often struggle to provide fine-grained control over the output. Existing guidance approaches, such as segmentation maps and depth maps, introduce spatial rigidity that restricts the inherent diversity of diffusion models. In this work, we introduce Deep Geometric Moments (DGM) as a novel form of guidance that encapsulates the subject's visual features and nuances through a learned geometric prior. DGMs focus specifically on the subject itself compared to DINO or CLIP features, which suffer from overemphasis on global image features or semantics. Unlike ResNets, which are sensitive to pixel-wise perturbations, DGMs rely on robust geometric moments. Our experiments demonstrate that DGM effectively balance control and diversity in diffusion-based image generation, allowing a flexible control mechanism for steering the diffusion process.
Graph Network Modeling Techniques for Visualizing Human Mobility Patterns
Apr 04, 2025



Human mobility analysis at urban-scale requires models to represent the complex nature of human movements, which in turn are affected by accessibility to nearby points of interest, underlying socioeconomic factors of a place, and local transport choices for people living in a geographic region. In this work, we represent human mobility and the associated flow of movements as a grapyh. Graph-based approaches for mobility analysis are still in their early stages of adoption and are actively being researched. The challenges of graph-based mobility analysis are multifaceted - the lack of sufficiently high-quality data to represent flows at high spatial and teporal resolution whereas, limited computational resources to translate large voluments of mobility data into a network structure, and scaling issues inherent in graph models etc. The current study develops a methodology by embedding graphs into a continuous space, which alleviates issues related to fast graph matching, graph time-series modeling, and visualization of mobility dynamics. Through experiments, we demonstrate how mobility data collected from taxicab trajectories could be transformed into network structures and patterns of mobility flow changes, and can be used for downstream tasks reporting approx 40% decrease in error on average in matched graphs vs unmatched ones.
DecompDreamer: Advancing Structured 3D Asset Generation with Multi-Object Decomposition and Gaussian Splatting
Mar 15, 2025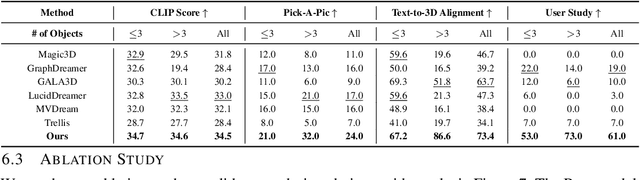
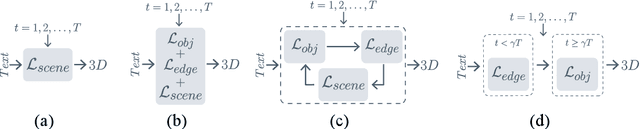

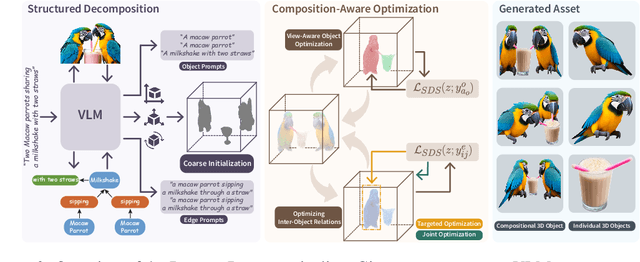
Text-to-3D generation saw dramatic advances in recent years by leveraging Text-to-Image models. However, most existing techniques struggle with compositional prompts, which describe multiple objects and their spatial relationships. They often fail to capture fine-grained inter-object interactions. We introduce DecompDreamer, a Gaussian splatting-based training routine designed to generate high-quality 3D compositions from such complex prompts. DecompDreamer leverages Vision-Language Models (VLMs) to decompose scenes into structured components and their relationships. We propose a progressive optimization strategy that first prioritizes joint relationship modeling before gradually shifting toward targeted object refinement. Our qualitative and quantitative evaluations against state-of-the-art text-to-3D models demonstrate that DecompDreamer effectively generates intricate 3D compositions with superior object disentanglement, offering enhanced control and flexibility in 3D generation. Project page : https://decompdreamer3d.github.io
Automatic Temporal Segmentation for Post-Stroke Rehabilitation: A Keypoint Detection and Temporal Segmentation Approach for Small Datasets
Feb 27, 2025Rehabilitation is essential and critical for post-stroke patients, addressing both physical and cognitive aspects. Stroke predominantly affects older adults, with 75% of cases occurring in individuals aged 65 and older, underscoring the urgent need for tailored rehabilitation strategies in aging populations. Despite the critical role therapists play in evaluating rehabilitation progress and ensuring the effectiveness of treatment, current assessment methods can often be subjective, inconsistent, and time-consuming, leading to delays in adjusting therapy protocols. This study aims to address these challenges by providing a solution for consistent and timely analysis. Specifically, we perform temporal segmentation of video recordings to capture detailed activities during stroke patients' rehabilitation. The main application scenario motivating this study is the clinical assessment of daily tabletop object interactions, which are crucial for post-stroke physical rehabilitation. To achieve this, we present a framework that leverages the biomechanics of movement during therapy sessions. Our solution divides the process into two main tasks: 2D keypoint detection to track patients' physical movements, and 1D time-series temporal segmentation to analyze these movements over time. This dual approach enables automated labeling with only a limited set of real-world data, addressing the challenges of variability in patient movements and limited dataset availability. By tackling these issues, our method shows strong potential for practical deployment in physical therapy settings, enhancing the speed and accuracy of rehabilitation assessments.
Role of Mixup in Topological Persistence Based Knowledge Distillation for Wearable Sensor Data
Feb 02, 2025



The analysis of wearable sensor data has enabled many successes in several applications. To represent the high-sampling rate time-series with sufficient detail, the use of topological data analysis (TDA) has been considered, and it is found that TDA can complement other time-series features. Nonetheless, due to the large time consumption and high computational resource requirements of extracting topological features through TDA, it is difficult to deploy topological knowledge in various applications. To tackle this problem, knowledge distillation (KD) can be adopted, which is a technique facilitating model compression and transfer learning to generate a smaller model by transferring knowledge from a larger network. By leveraging multiple teachers in KD, both time-series and topological features can be transferred, and finally, a superior student using only time-series data is distilled. On the other hand, mixup has been popularly used as a robust data augmentation technique to enhance model performance during training. Mixup and KD employ similar learning strategies. In KD, the student model learns from the smoothed distribution generated by the teacher model, while mixup creates smoothed labels by blending two labels. Hence, this common smoothness serves as the connecting link that establishes a connection between these two methods. In this paper, we analyze the role of mixup in KD with time-series as well as topological persistence, employing multiple teachers. We present a comprehensive analysis of various methods in KD and mixup on wearable sensor data.
Deep Geometric Moments Promote Shape Consistency in Text-to-3D Generation
Aug 12, 2024



To address the data scarcity associated with 3D assets, 2D-lifting techniques such as Score Distillation Sampling (SDS) have become a widely adopted practice in text-to-3D generation pipelines. However, the diffusion models used in these techniques are prone to viewpoint bias and thus lead to geometric inconsistencies such as the Janus problem. To counter this, we introduce MT3D, a text-to-3D generative model that leverages a high-fidelity 3D object to overcome viewpoint bias and explicitly infuse geometric understanding into the generation pipeline. Firstly, we employ depth maps derived from a high-quality 3D model as control signals to guarantee that the generated 2D images preserve the fundamental shape and structure, thereby reducing the inherent viewpoint bias. Next, we utilize deep geometric moments to ensure geometric consistency in the 3D representation explicitly. By incorporating geometric details from a 3D asset, MT3D enables the creation of diverse and geometrically consistent objects, thereby improving the quality and usability of our 3D representations.
Topological Persistence Guided Knowledge Distillation for Wearable Sensor Data
Jul 07, 2024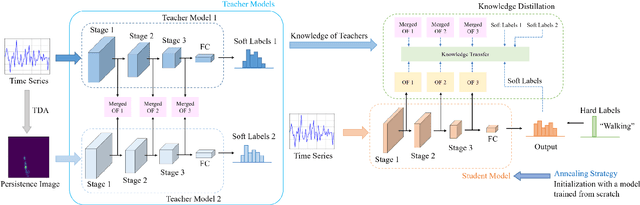
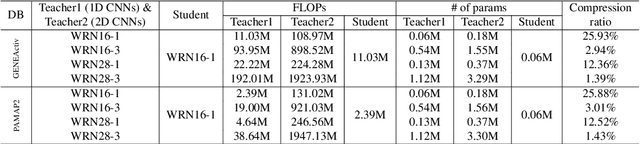
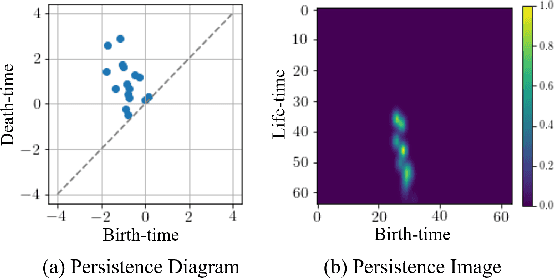
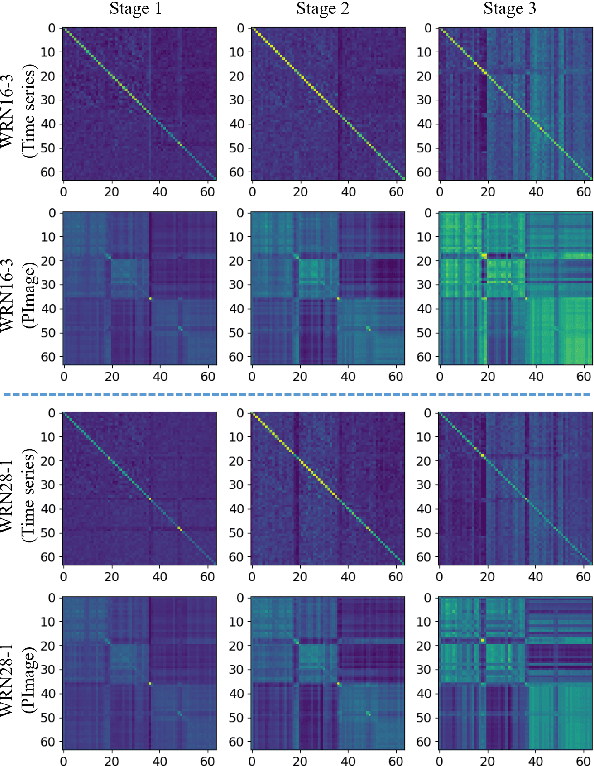
Deep learning methods have achieved a lot of success in various applications involving converting wearable sensor data to actionable health insights. A common application areas is activity recognition, where deep-learning methods still suffer from limitations such as sensitivity to signal quality, sensor characteristic variations, and variability between subjects. To mitigate these issues, robust features obtained by topological data analysis (TDA) have been suggested as a potential solution. However, there are two significant obstacles to using topological features in deep learning: (1) large computational load to extract topological features using TDA, and (2) different signal representations obtained from deep learning and TDA which makes fusion difficult. In this paper, to enable integration of the strengths of topological methods in deep-learning for time-series data, we propose to use two teacher networks, one trained on the raw time-series data, and another trained on persistence images generated by TDA methods. The distilled student model utilizes only the raw time-series data at test-time. This approach addresses both issues. The use of KD with multiple teachers utilizes complementary information, and results in a compact model with strong supervisory features and an integrated richer representation. To assimilate desirable information from different modalities, we design new constraints, including orthogonality imposed on feature correlation maps for improving feature expressiveness and allowing the student to easily learn from the teacher. Also, we apply an annealing strategy in KD for fast saturation and better accommodation from different features, while the knowledge gap between the teachers and student is reduced. Finally, a robust student model is distilled, which uses only the time-series data as an input, while implicitly preserving topological features.
* Engineering Applications of Artificial Intelligence 130, 107719
Leveraging Topological Guidance for Improved Knowledge Distillation
Jul 07, 2024



Deep learning has shown its efficacy in extracting useful features to solve various computer vision tasks. However, when the structure of the data is complex and noisy, capturing effective information to improve performance is very difficult. To this end, topological data analysis (TDA) has been utilized to derive useful representations that can contribute to improving performance and robustness against perturbations. Despite its effectiveness, the requirements for large computational resources and significant time consumption in extracting topological features through TDA are critical problems when implementing it on small devices. To address this issue, we propose a framework called Topological Guidance-based Knowledge Distillation (TGD), which uses topological features in knowledge distillation (KD) for image classification tasks. We utilize KD to train a superior lightweight model and provide topological features with multiple teachers simultaneously. We introduce a mechanism for integrating features from different teachers and reducing the knowledge gap between teachers and the student, which aids in improving performance. We demonstrate the effectiveness of our approach through diverse empirical evaluations.