 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlucoLens: Explainable Postprandial Blood Glucose Prediction from Diet and Physical Activity
Mar 05, 2025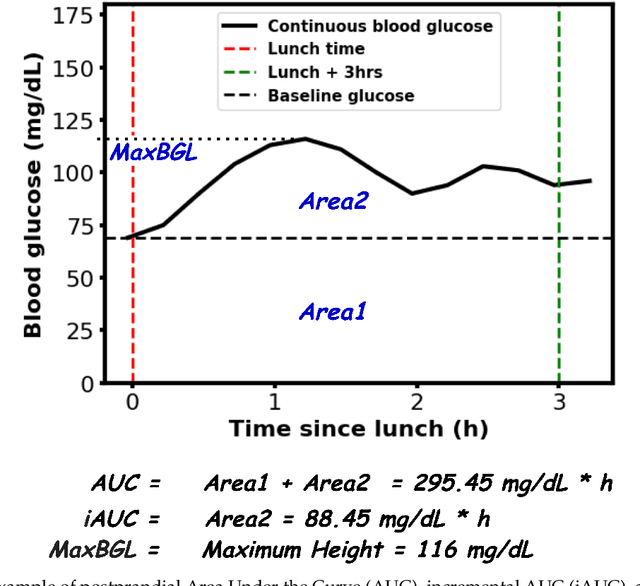
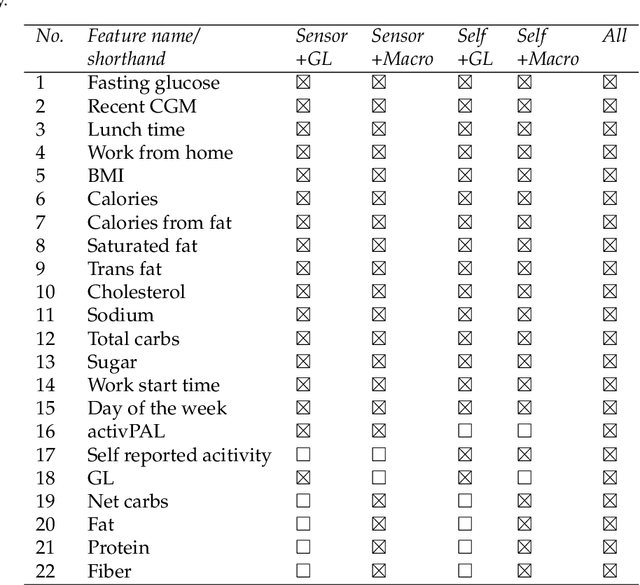
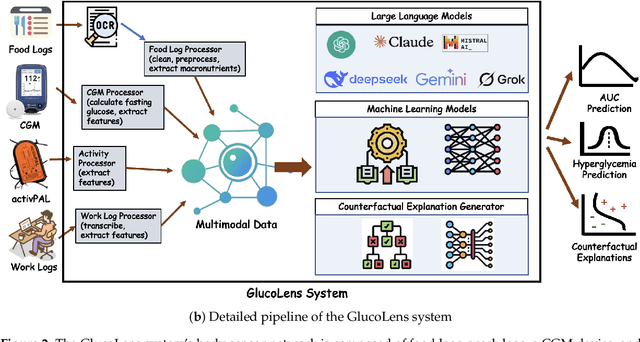

Postprandial hyperglycemia, marked by the blood glucose level exceeding the normal range after meals, is a critical indicator of progression toward type 2 diabetes in prediabetic and healthy individuals. A key metric for understanding blood glucose dynamics after eating is the postprandial area under the curve (PAUC). Predicting PAUC in advance based on a person's diet and activity level and explaining what affects postprandial blood glucose could allow an individual to adjust their lifestyle accordingly to maintain normal glucose levels. In this paper, we propose GlucoLens, an explainable machine learning approach to predict PAUC and hyperglycemia from diet, activity, and recent glucose patterns. We conducted a five-week user study with 10 full-time working individuals to develop and evaluate the computational model. Our machine learning model takes multimodal data including fasting glucose, recent glucose, recent activity, and macronutrient amounts, and provides an interpretable prediction of the postprandial glucose pattern. Our extensive analyses of the collected data revealed that the trained model achieves a normalized root mean squared error (NRMSE) of 0.123. On average, GlucoLense with a Random Forest backbone provides a 16% better result than the baseline models. Additionally, GlucoLens predicts hyperglycemia with an accuracy of 74% and recommends different options to help avoid hyperglycemia through diverse counterfactual explanations. Code available: https://github.com/ab9mamun/GlucoLens.
Role of Mixup in Topological Persistence Based Knowledge Distillation for Wearable Sensor Data
Feb 02, 2025



The analysis of wearable sensor data has enabled many successes in several applications. To represent the high-sampling rate time-series with sufficient detail, the use of topological data analysis (TDA) has been considered, and it is found that TDA can complement other time-series features. Nonetheless, due to the large time consumption and high computational resource requirements of extracting topological features through TDA, it is difficult to deploy topological knowledge in various applications. To tackle this problem, knowledge distillation (KD) can be adopted, which is a technique facilitating model compression and transfer learning to generate a smaller model by transferring knowledge from a larger network. By leveraging multiple teachers in KD, both time-series and topological features can be transferred, and finally, a superior student using only time-series data is distilled. On the other hand, mixup has been popularly used as a robust data augmentation technique to enhance model performance during training. Mixup and KD employ similar learning strategies. In KD, the student model learns from the smoothed distribution generated by the teacher model, while mixup creates smoothed labels by blending two labels. Hence, this common smoothness serves as the connecting link that establishes a connection between these two methods. In this paper, we analyze the role of mixup in KD with time-series as well as topological persistence, employing multiple teachers. We present a comprehensive analysis of various methods in KD and mixup on wearable sensor data.
Multimodal Physical Activity Forecasting in Free-Living Clinical Settings: Hunting Opportunities for Just-in-Time Interventions
Oct 12, 2024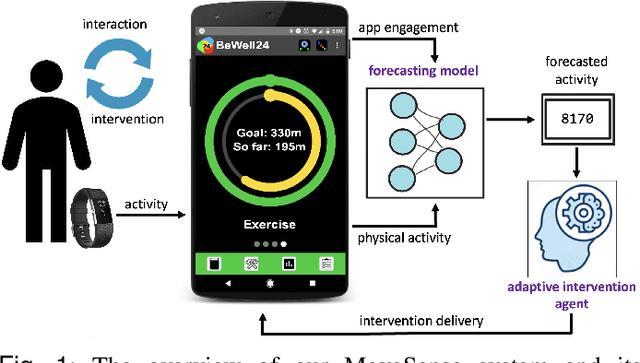

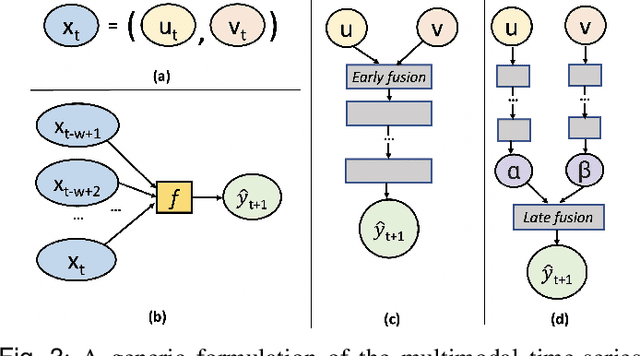
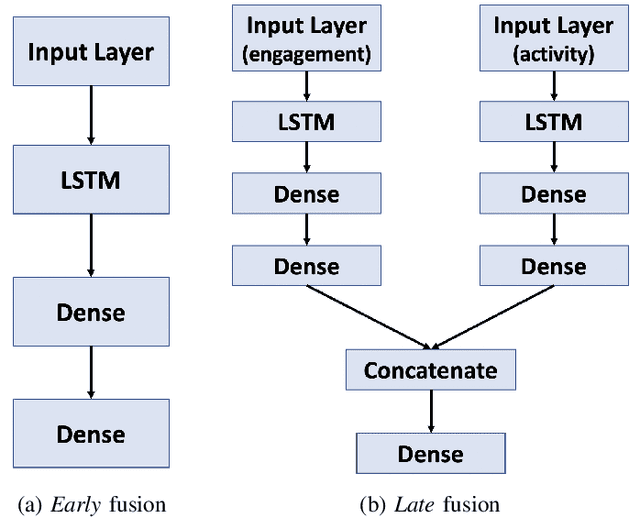
Objective: This research aims to develop a lifestyle intervention system, called MoveSense, that forecasts a patient's activity behavior to allow for early and personalized interventions in real-world clinical environments. Methods: We conducted two clinical studies involving 58 prediabetic veterans and 60 patients with obstructive sleep apnea to gather multimodal behavioral data using wearable devices. We develop multimodal long short-term memory (LSTM) network models, which are capable of forecasting the number of step counts of a patient up to 24 hours in advance by examining data from activity and engagement modalities. Furthermore, we design goal-based forecasting models to predict whether a person's next-day steps will be over a certain threshold. Results: Multimodal LSTM with early fusion achieves 33% and 37% lower mean absolute errors than linear regression and ARIMA respectively on the prediabetes dataset. LSTM also outperforms linear regression and ARIMA with a margin of 13% and 32% on the sleep dataset. Multimodal forecasting models also perform with 72% and 79% accuracy on the prediabetes dataset and sleep dataset respectively on goal-based forecasting. Conclusion: Our experiments conclude that multimodal LSTM models with early fusion are better than multimodal LSTM with late fusion and unimodal LSTM models and also than ARIMA and linear regression models. Significance: We address an important and challenging task of time-series forecasting in uncontrolled environments. Effective forecasting of a person's physical activity can aid in designing adaptive behavioral interventions to keep the user engaged and adherent to a prescribed routine.
Topological Persistence Guided Knowledge Distillation for Wearable Sensor Data
Jul 07, 2024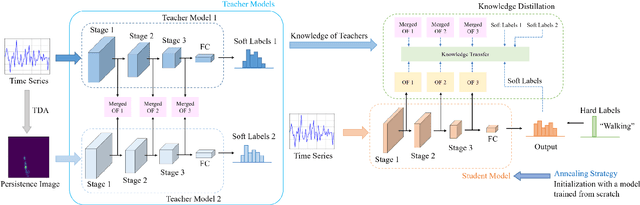
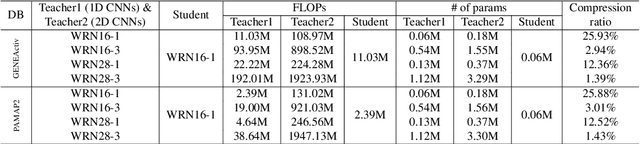
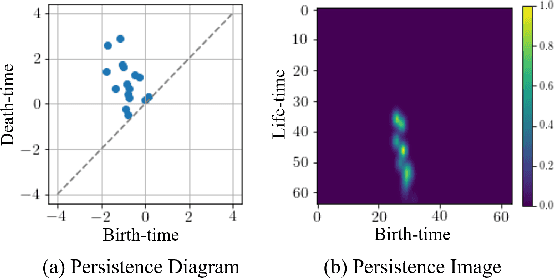
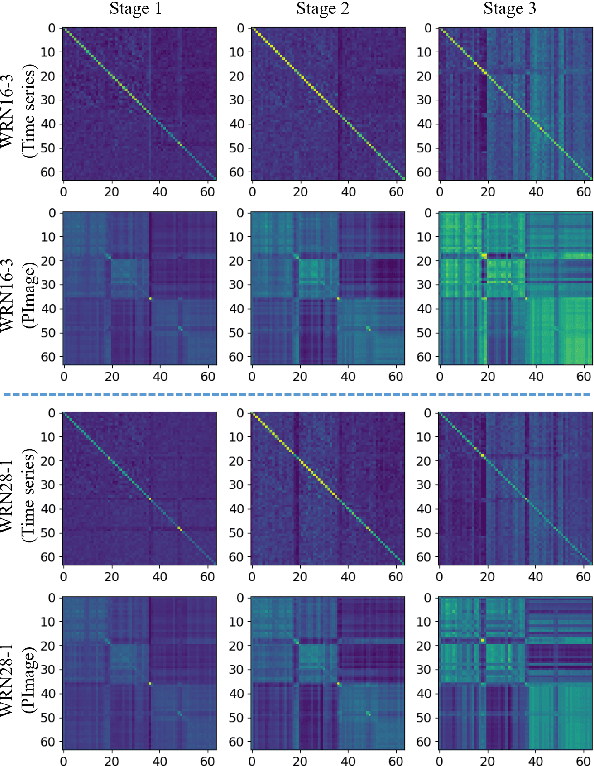
Deep learning methods have achieved a lot of success in various applications involving converting wearable sensor data to actionable health insights. A common application areas is activity recognition, where deep-learning methods still suffer from limitations such as sensitivity to signal quality, sensor characteristic variations, and variability between subjects. To mitigate these issues, robust features obtained by topological data analysis (TDA) have been suggested as a potential solution. However, there are two significant obstacles to using topological features in deep learning: (1) large computational load to extract topological features using TDA, and (2) different signal representations obtained from deep learning and TDA which makes fusion difficult. In this paper, to enable integration of the strengths of topological methods in deep-learning for time-series data, we propose to use two teacher networks, one trained on the raw time-series data, and another trained on persistence images generated by TDA methods. The distilled student model utilizes only the raw time-series data at test-time. This approach addresses both issues. The use of KD with multiple teachers utilizes complementary information, and results in a compact model with strong supervisory features and an integrated richer representation. To assimilate desirable information from different modalities, we design new constraints, including orthogonality imposed on feature correlation maps for improving feature expressiveness and allowing the student to easily learn from the teacher. Also, we apply an annealing strategy in KD for fast saturation and better accommodation from different features, while the knowledge gap between the teachers and student is reduced. Finally, a robust student model is distilled, which uses only the time-series data as an input, while implicitly preserving topological features.
* Engineering Applications of Artificial Intelligence 130, 107719
Role of Data Augmentation Strategies in Knowledge Distillation for Wearable Sensor Data
Jan 01, 2022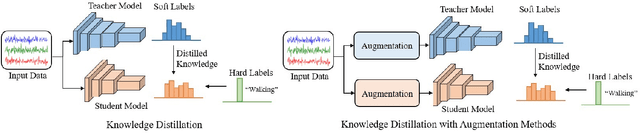
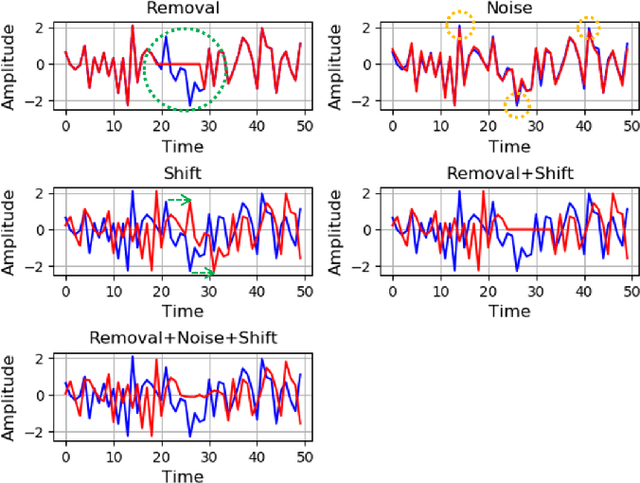
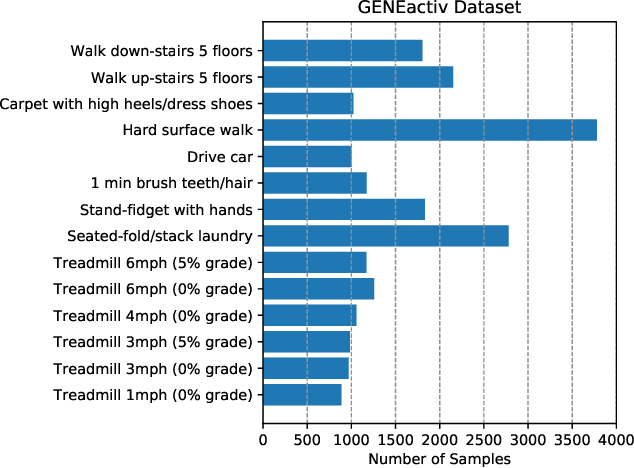
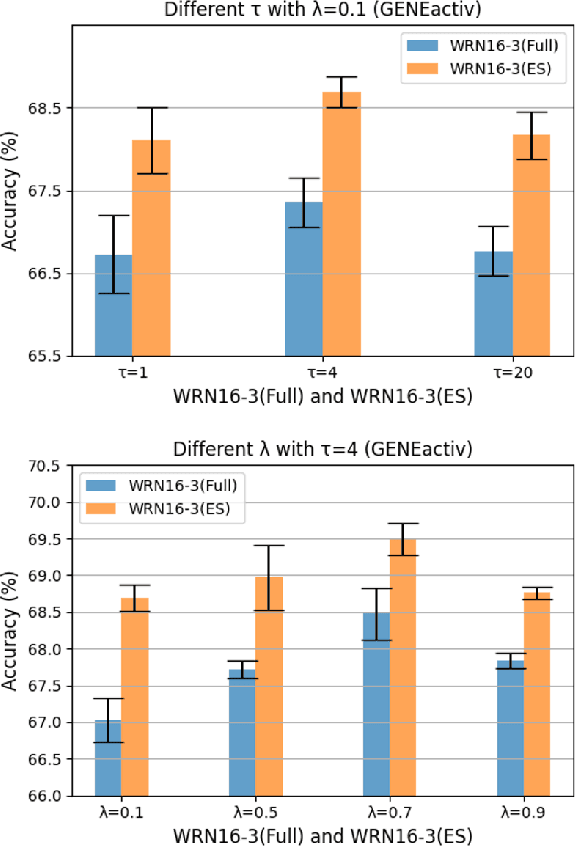
Deep neural networks are parametrized by several thousands or millions of parameters, and have shown tremendous success in many classification problems. However, the large number of parameters makes it difficult to integrate these models into edge devices such as smartphones and wearable devices. To address this problem, knowledge distillation (KD) has been widely employed, that uses a pre-trained high capacity network to train a much smaller network, suitable for edge devices. In this paper, for the first time, we study the applicability and challenges of using KD for time-series data for wearable devices. Successful application of KD requires specific choices of data augmentation methods during training. However, it is not yet known if there exists a coherent strategy for choosing an augmentation approach during KD. In this paper, we report the results of a detailed study that compares and contrasts various common choices and some hybrid data augmentation strategies in KD based human activity analysis. Research in this area is often limited as there are not many comprehensive databases available in the public domain from wearable devices. Our study considers databases from small scale publicly available to one derived from a large scale interventional study into human activity and sedentary behavior. We find that the choice of data augmentation techniques during KD have a variable level of impact on end performance, and find that the optimal network choice as well as data augmentation strategies are specific to a dataset at hand. However, we also conclude with a general set of recommendations that can provide a strong baseline performance across databases.